




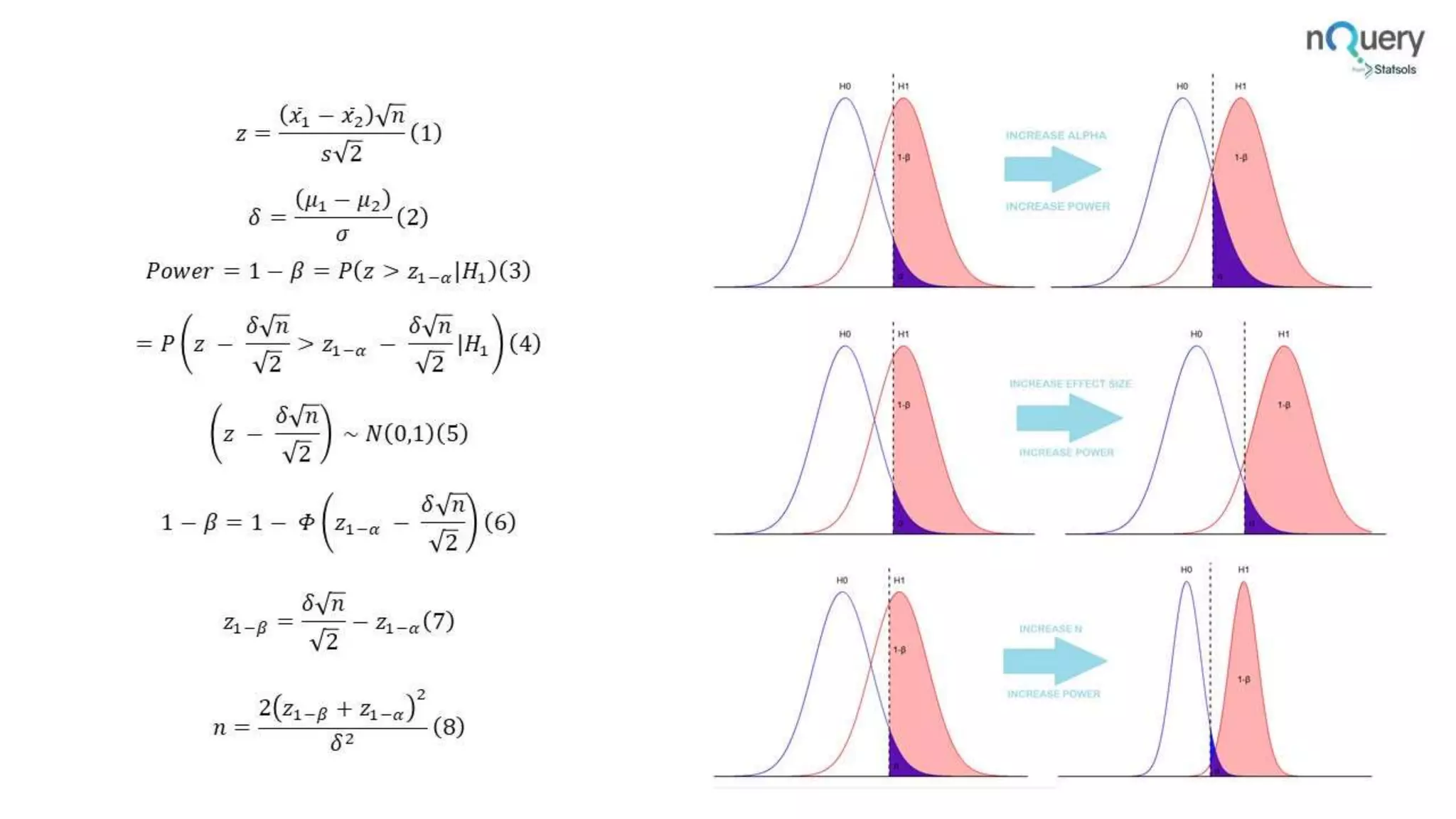














The document provides an overview of a webinar led by Ronan Fitzpatrick on sample size determination, emphasizing its importance in clinical trials. It covers methods such as Bayesian sample size determination, survival analysis, and the functionalities of the software nQuery, highlighting its user-friendly features and updates. Key topics include the calculation of required sample sizes for achieving statistical power and the relevance of estimating sample size to ensure valid conclusions in research.










































































