Downloaded 10 times








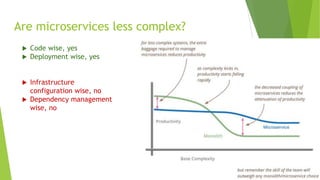












The document outlines the concept of microservices as small, autonomous software components that address specific tasks while being loosely coupled and independently scalable. It discusses the conditions under which microservices should be considered, the appropriate size for a microservice, communication methods, and management strategies, including deployment tools and self-healing practices. The complexities and challenges associated with microservices, particularly in terms of infrastructure and dependency management, are also highlighted.











































































