Download as PDF, PPTX




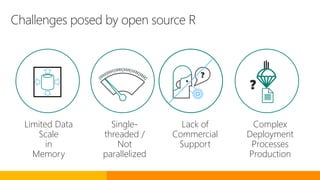




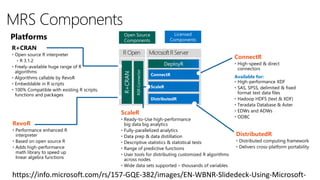






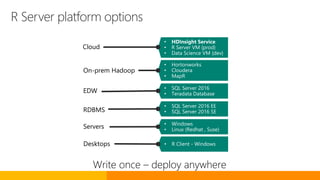

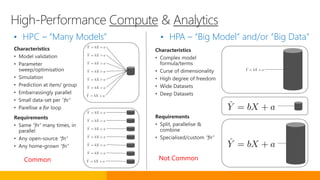




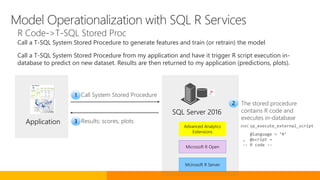








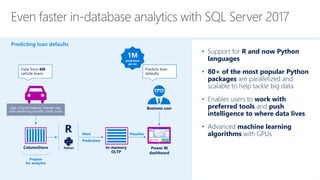
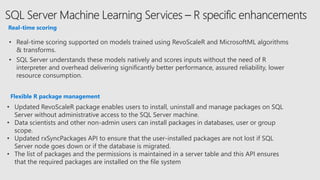



The document discusses advancements in Microsoft R products aimed at enhancing the scalability and capabilities of R for data analysis and big data applications. Key features include multi-threading, parallel processing, and integration with SQL Server, which enable efficient analytics on large datasets while maintaining data security. The release also highlights new functionalities such as cognitive models for sentiment analysis and image feature extraction, thereby providing valuable tools for diverse industries.










![[Pulsar summit na 21] Change Data Capture To Data Lakes Using Apache Pulsar/Hudi](https://cdn.slidesharecdn.com/ss_thumbnails/pulsarsummitna21cdcusinghudipulsardeck-210628151056-thumbnail.jpg?width=640&height=640&fit=bounds)
























































