





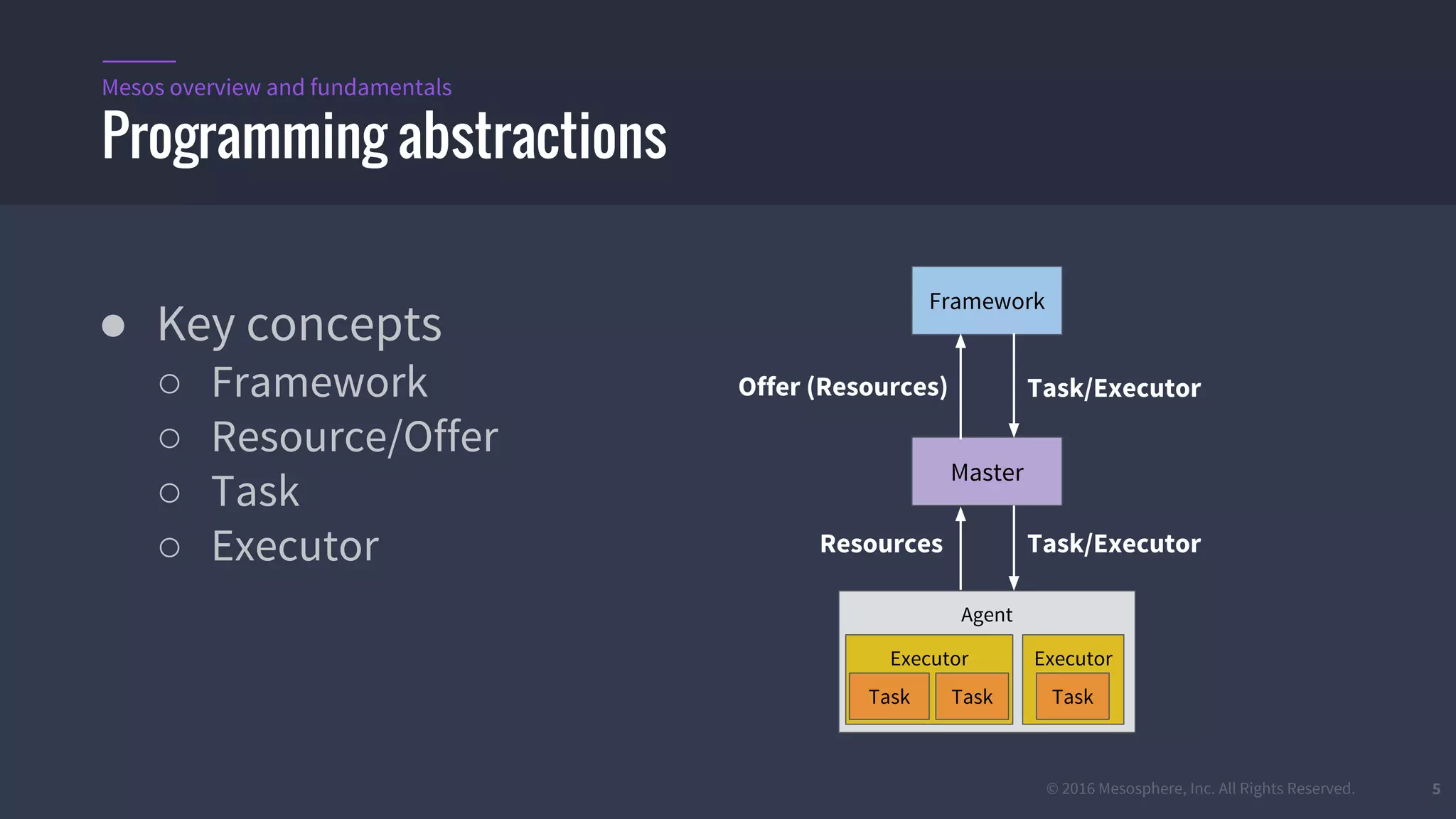
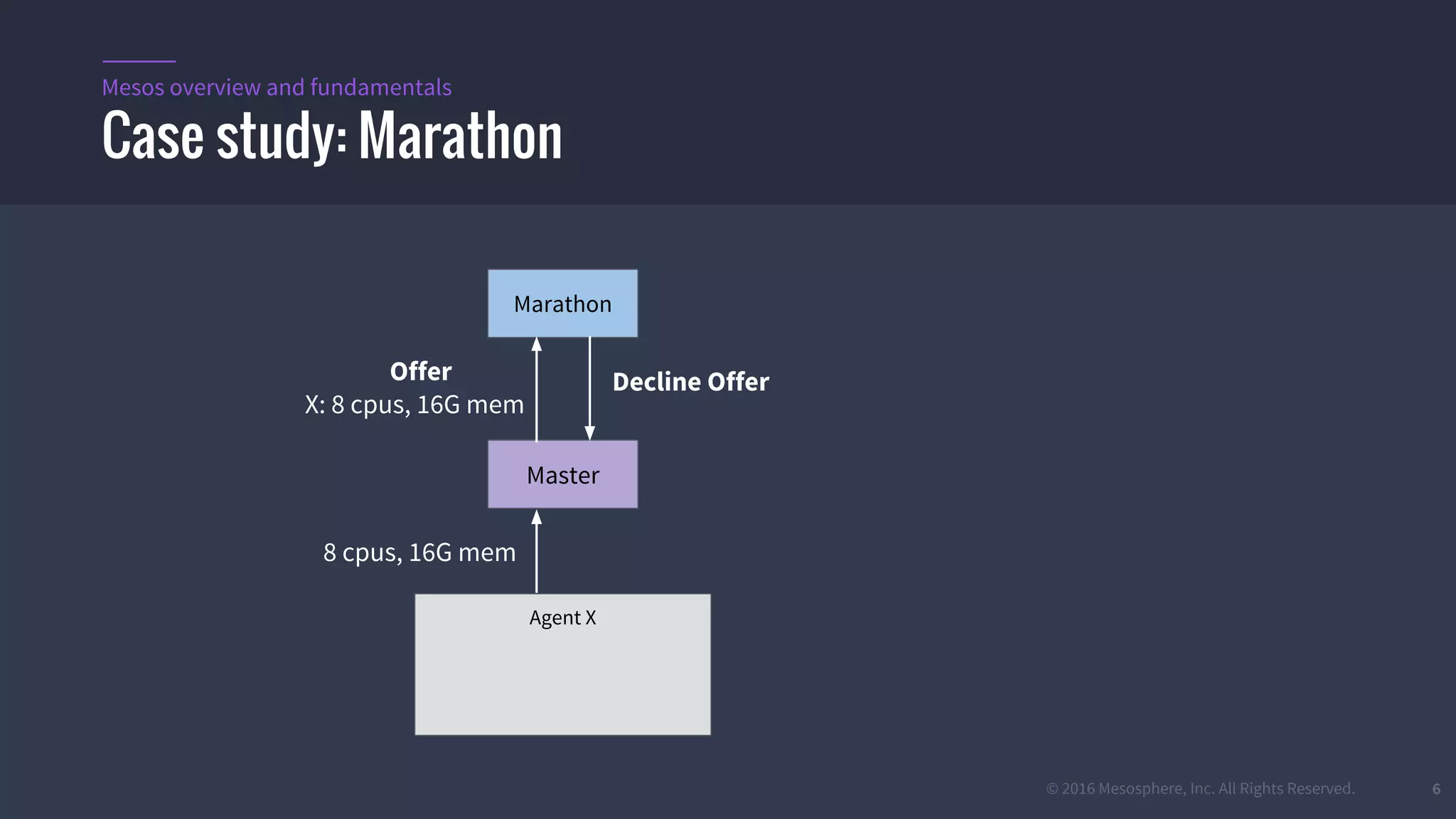
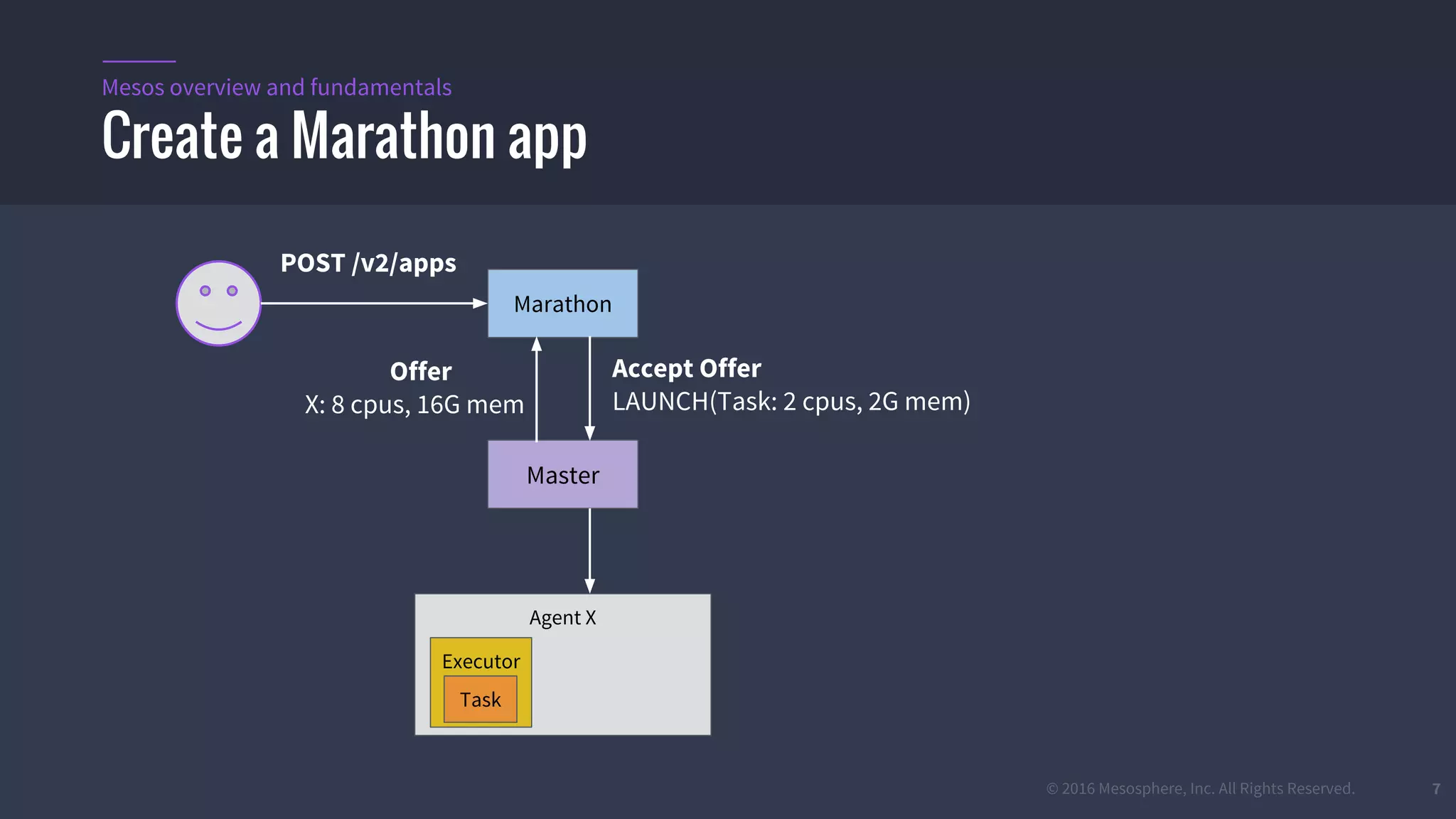
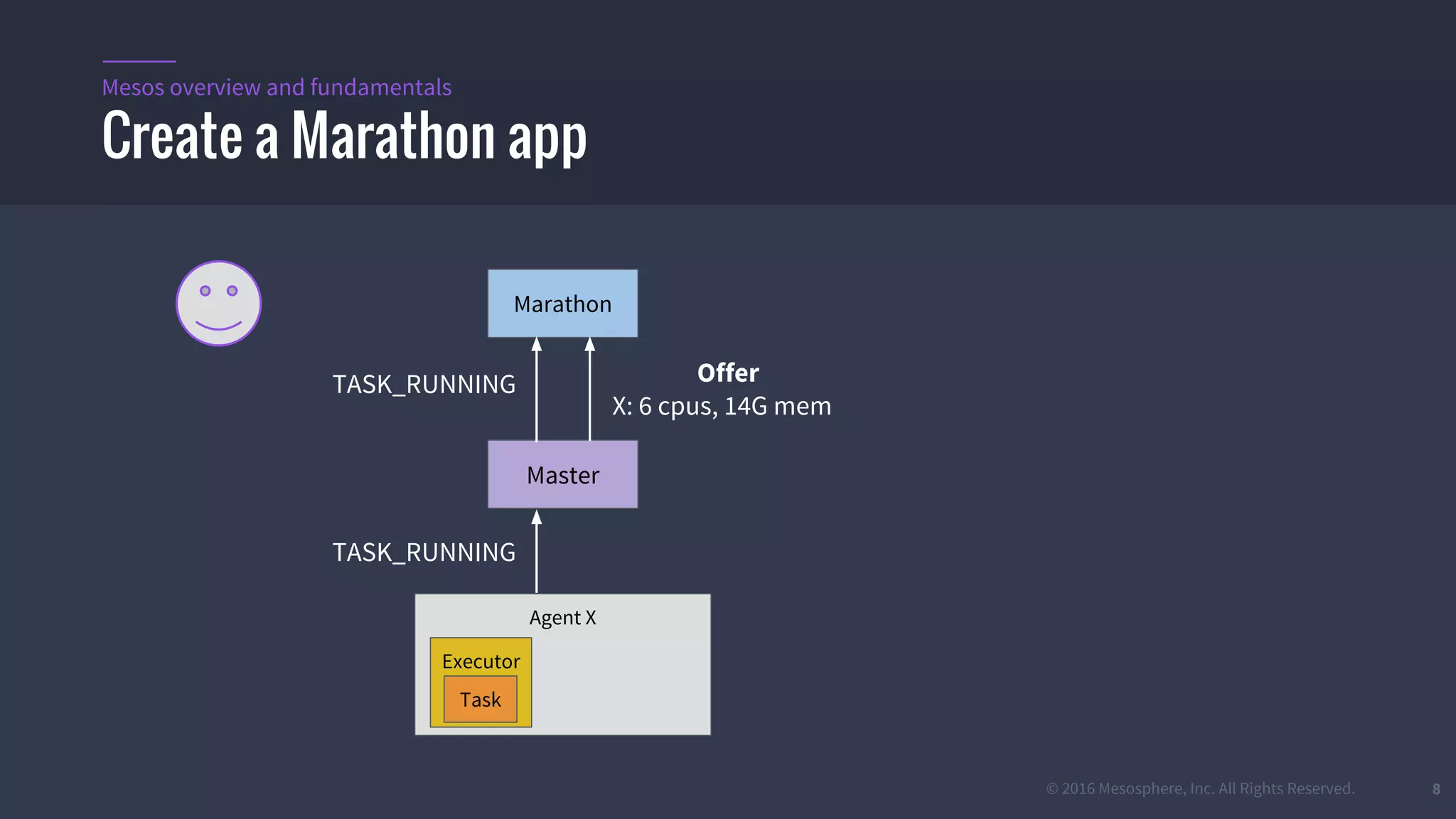
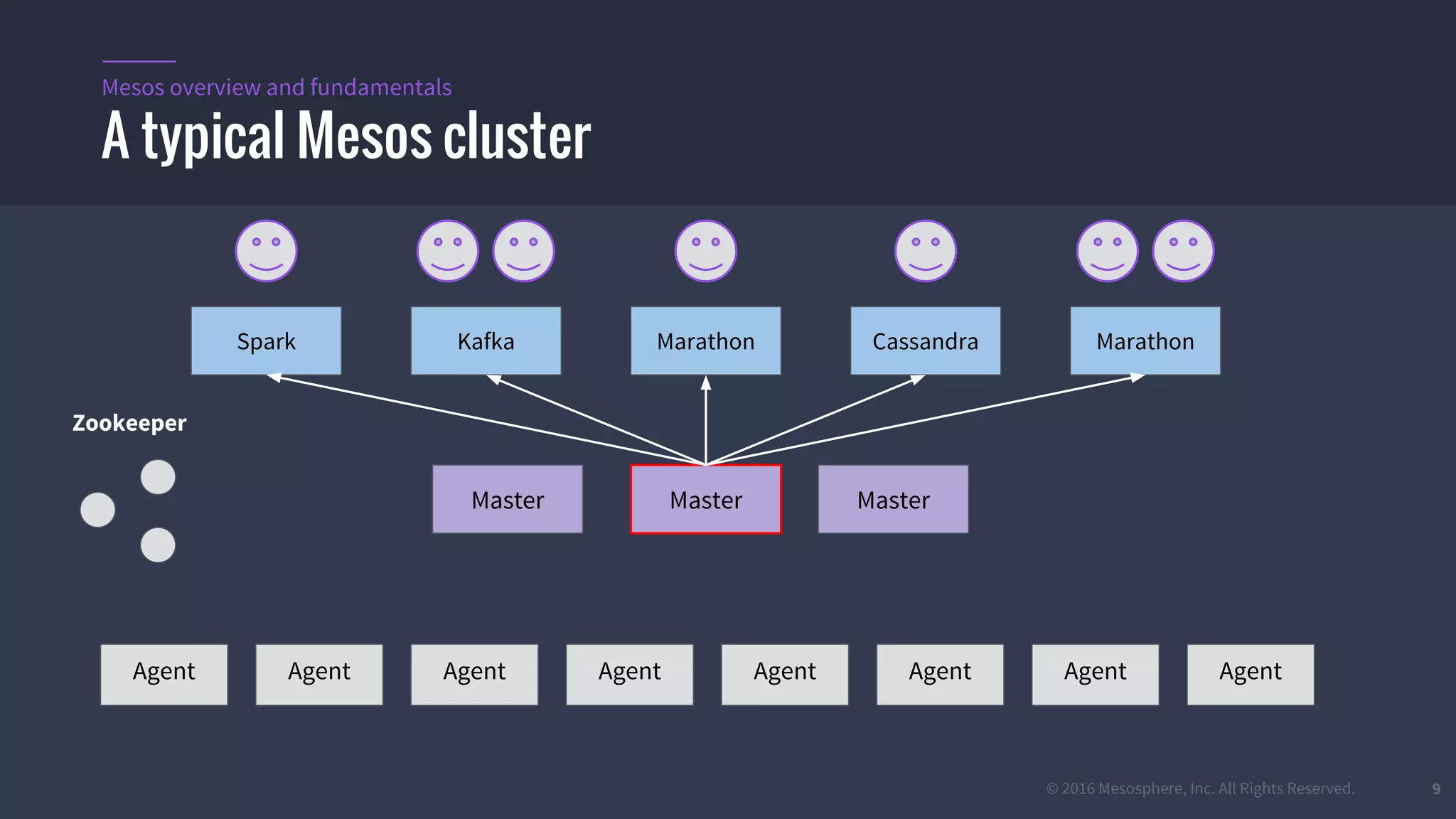
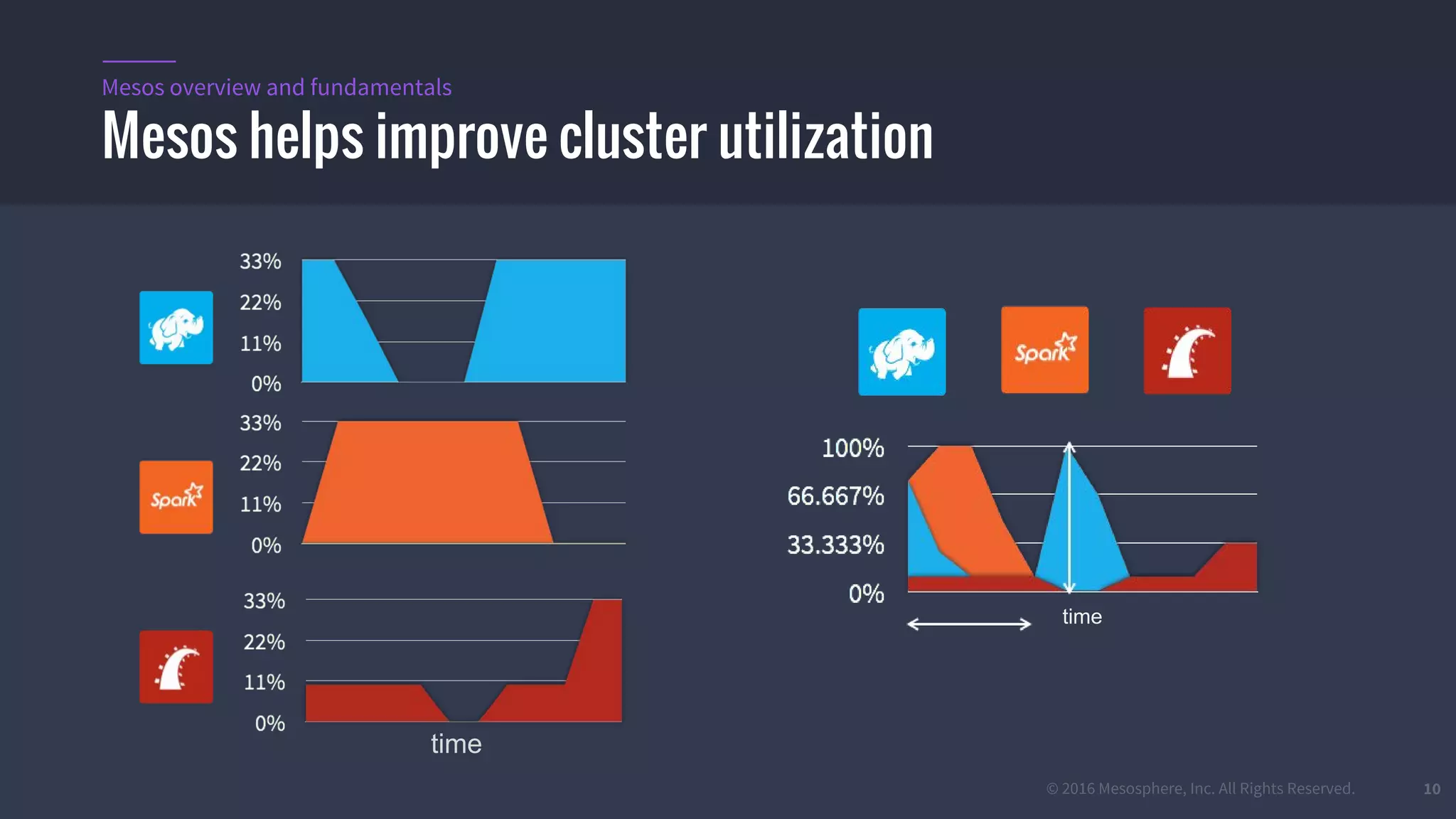
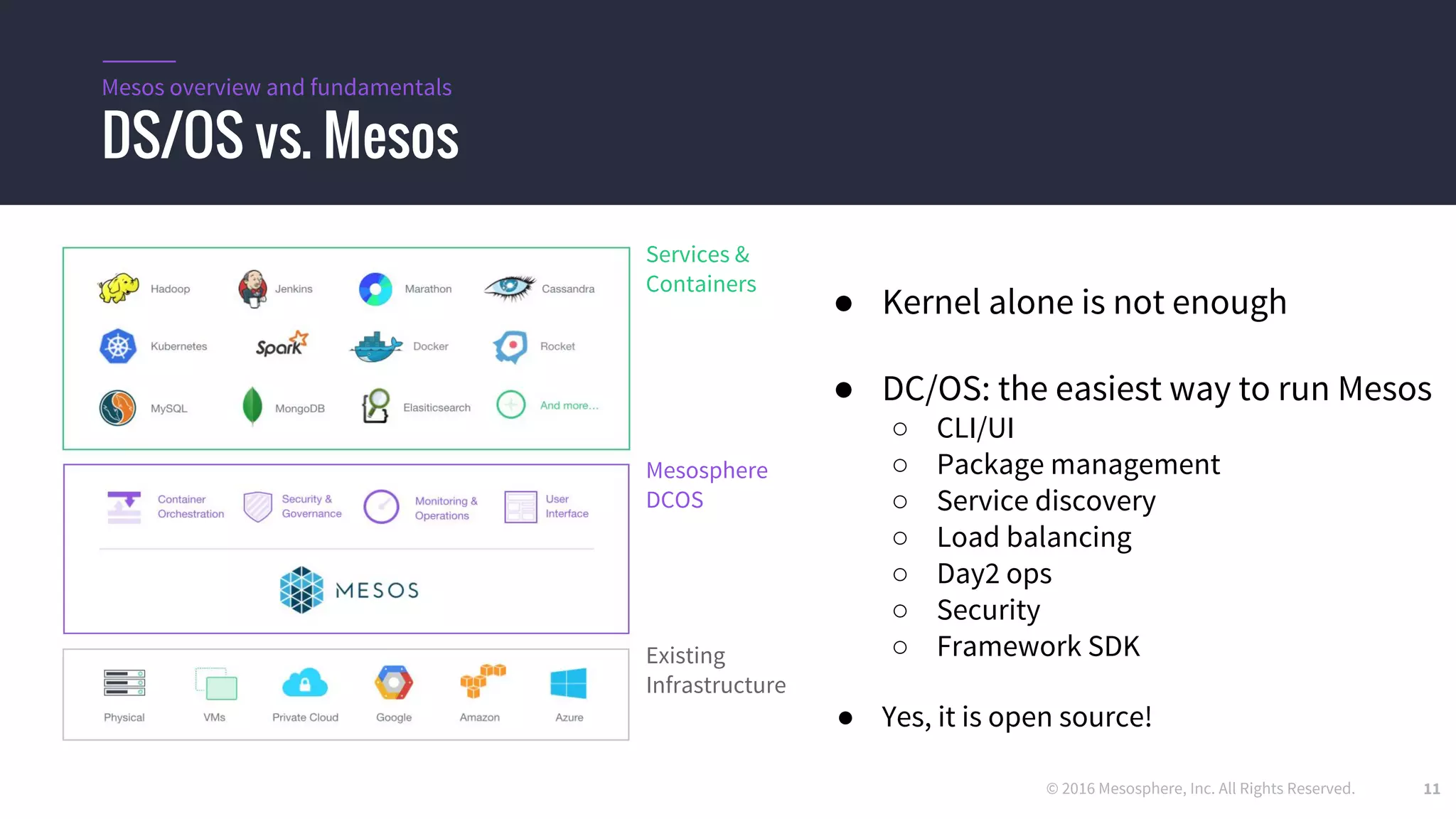


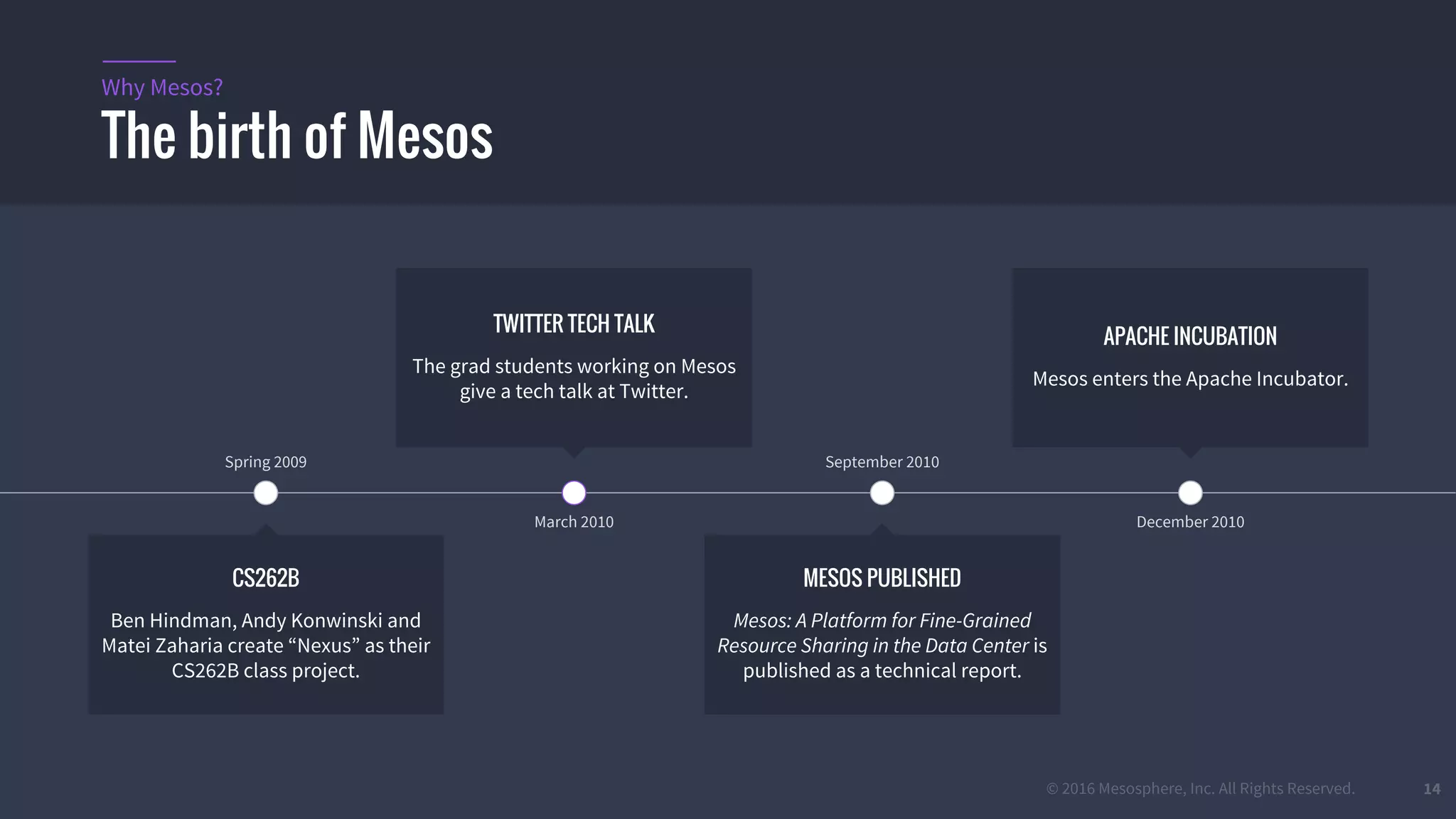
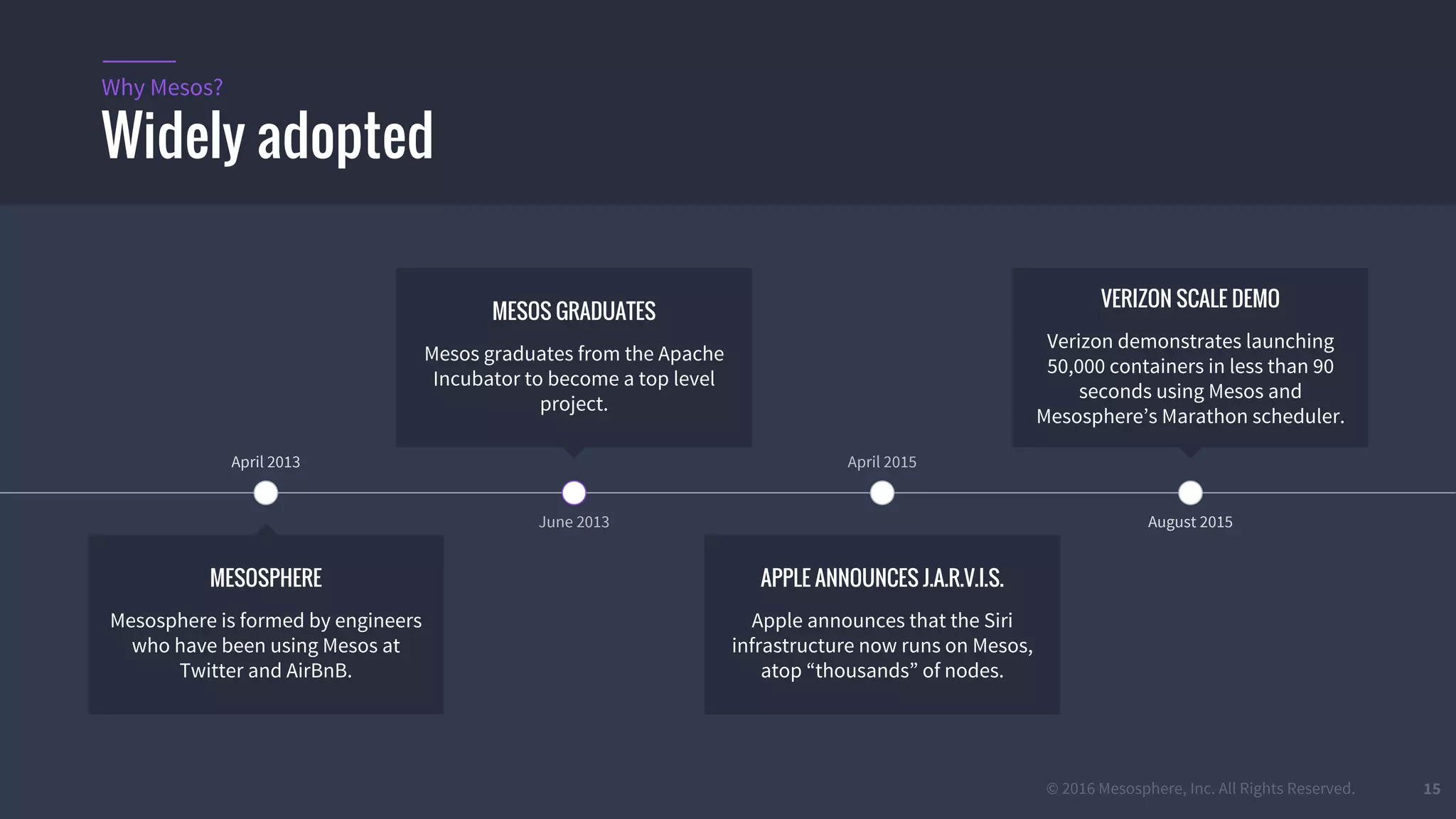


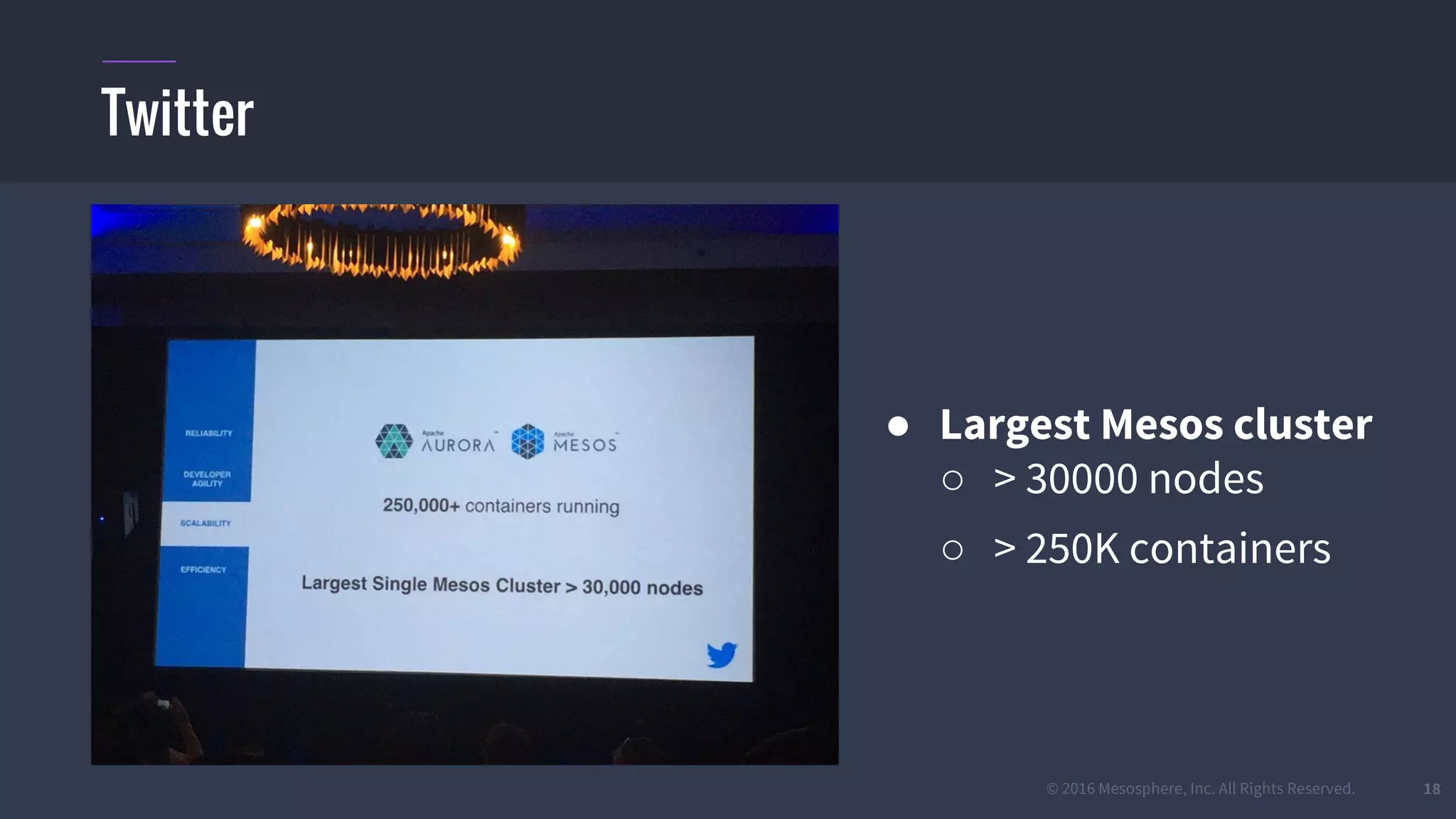










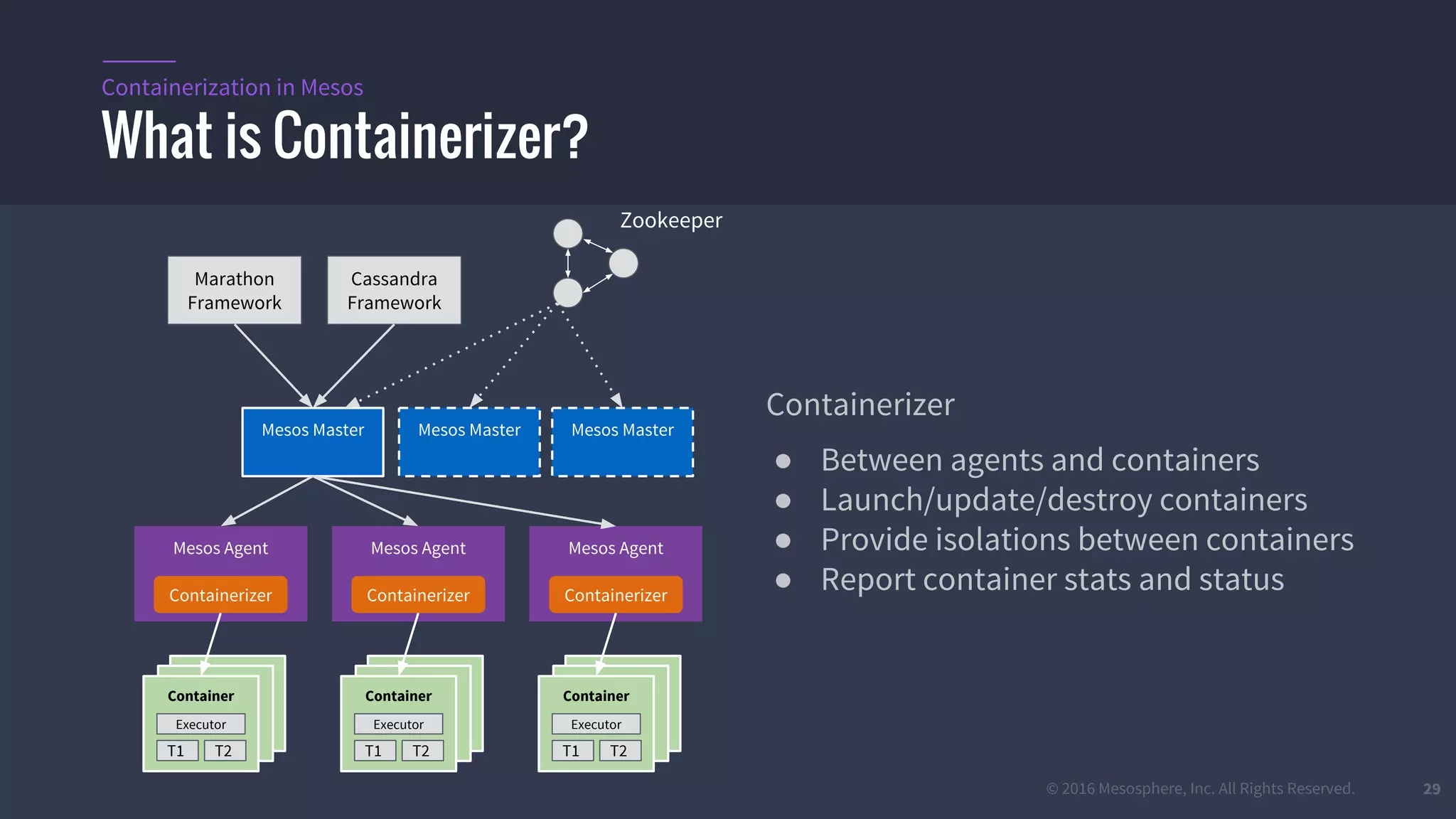




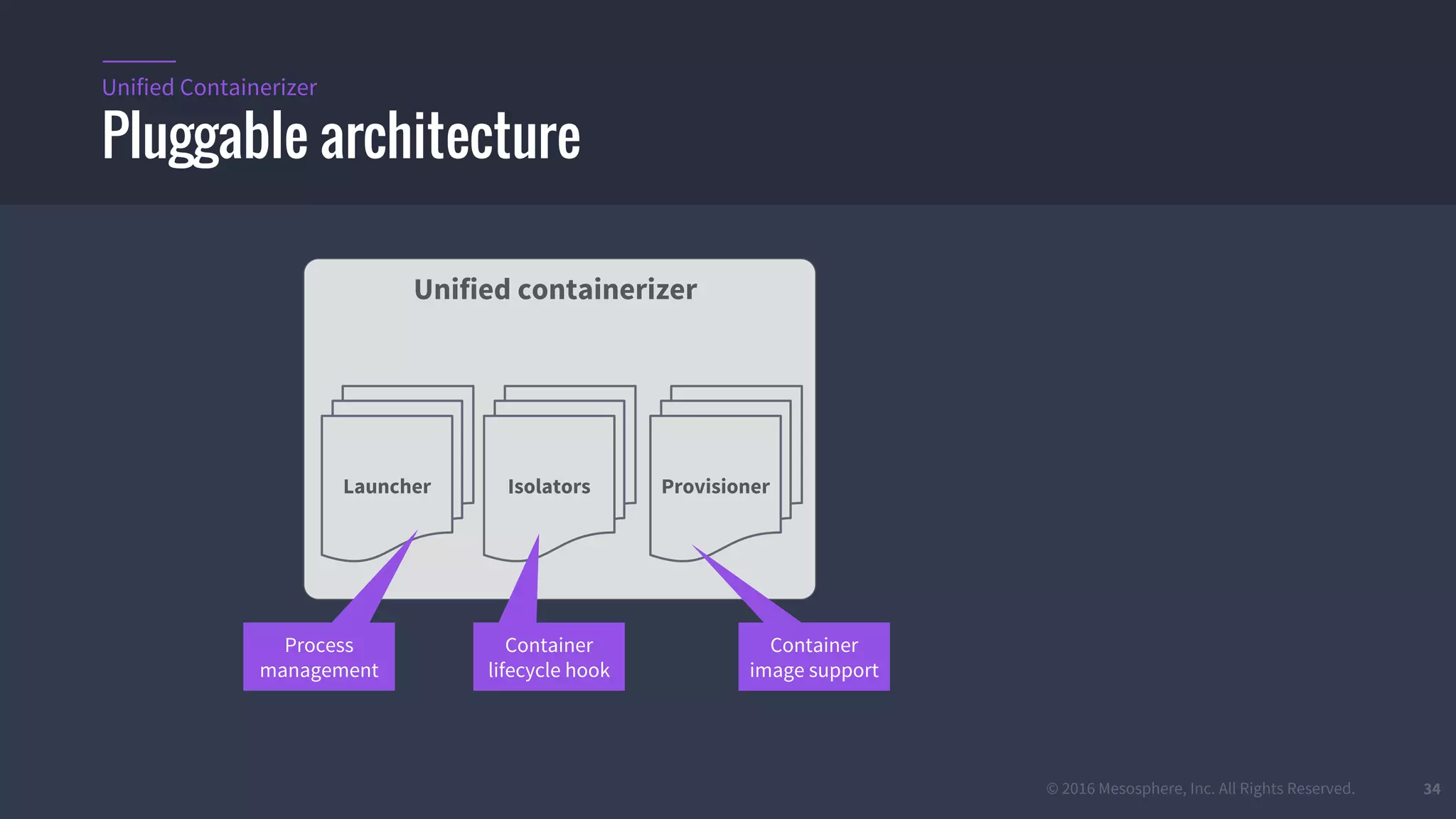


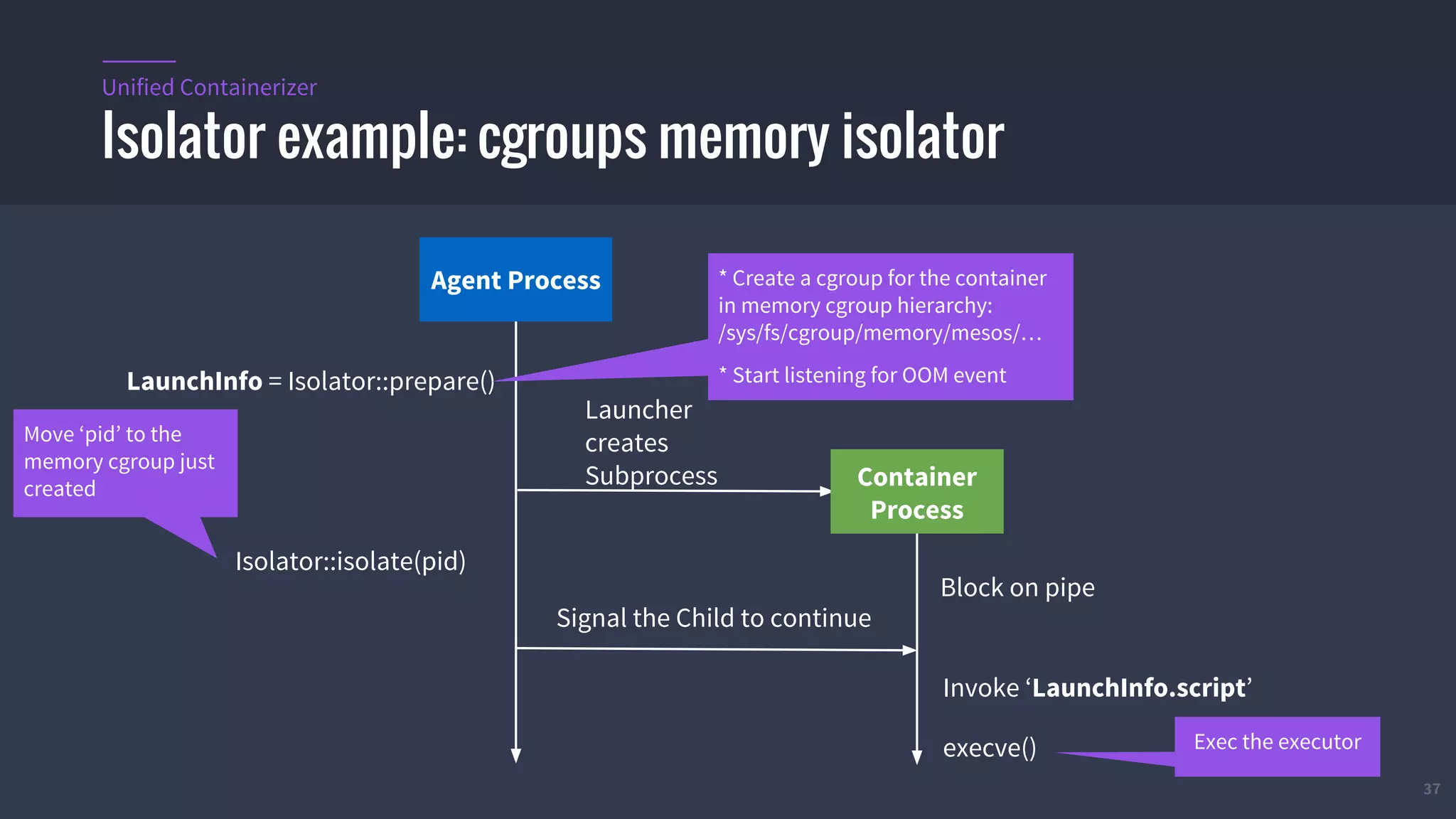
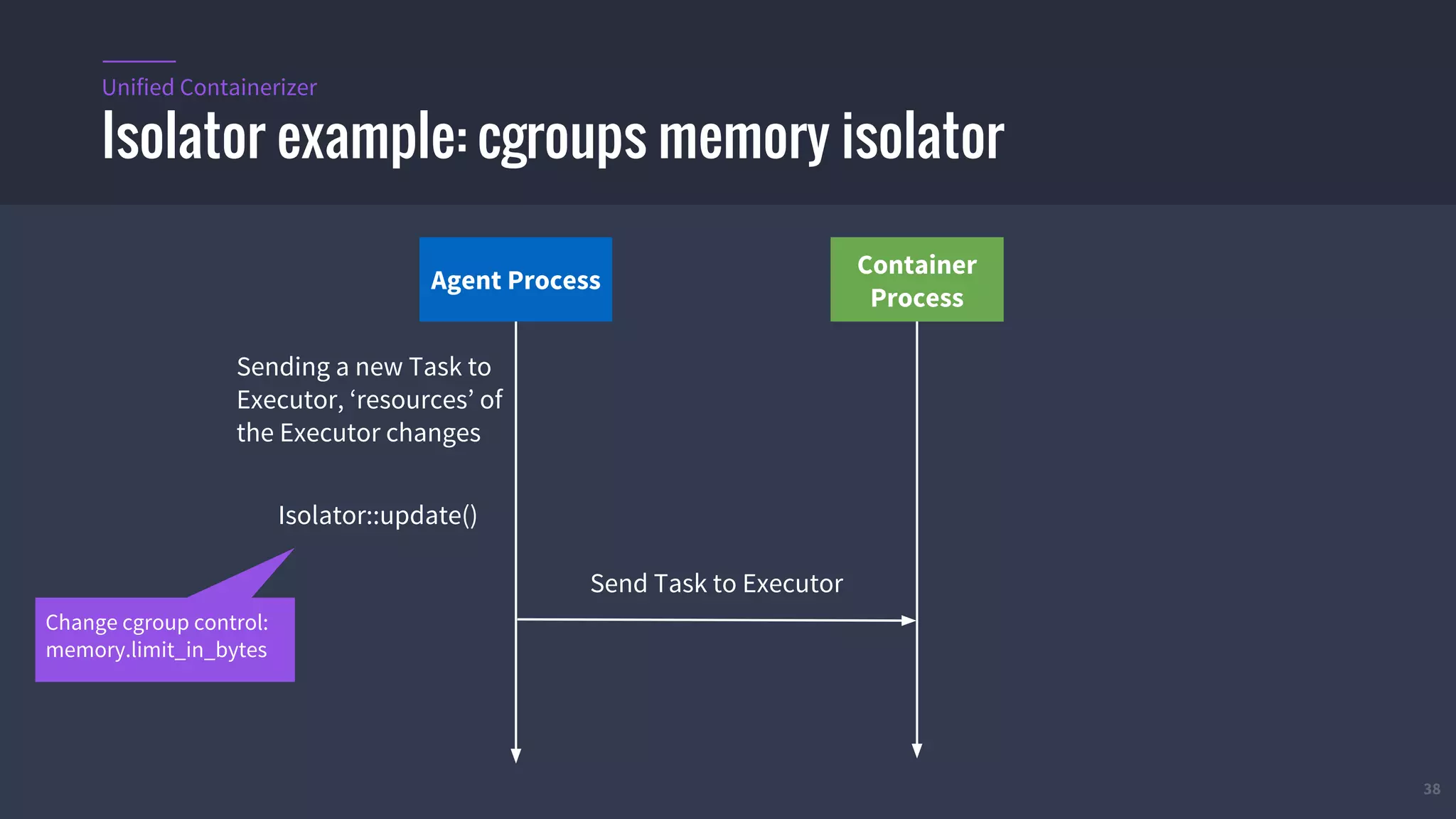
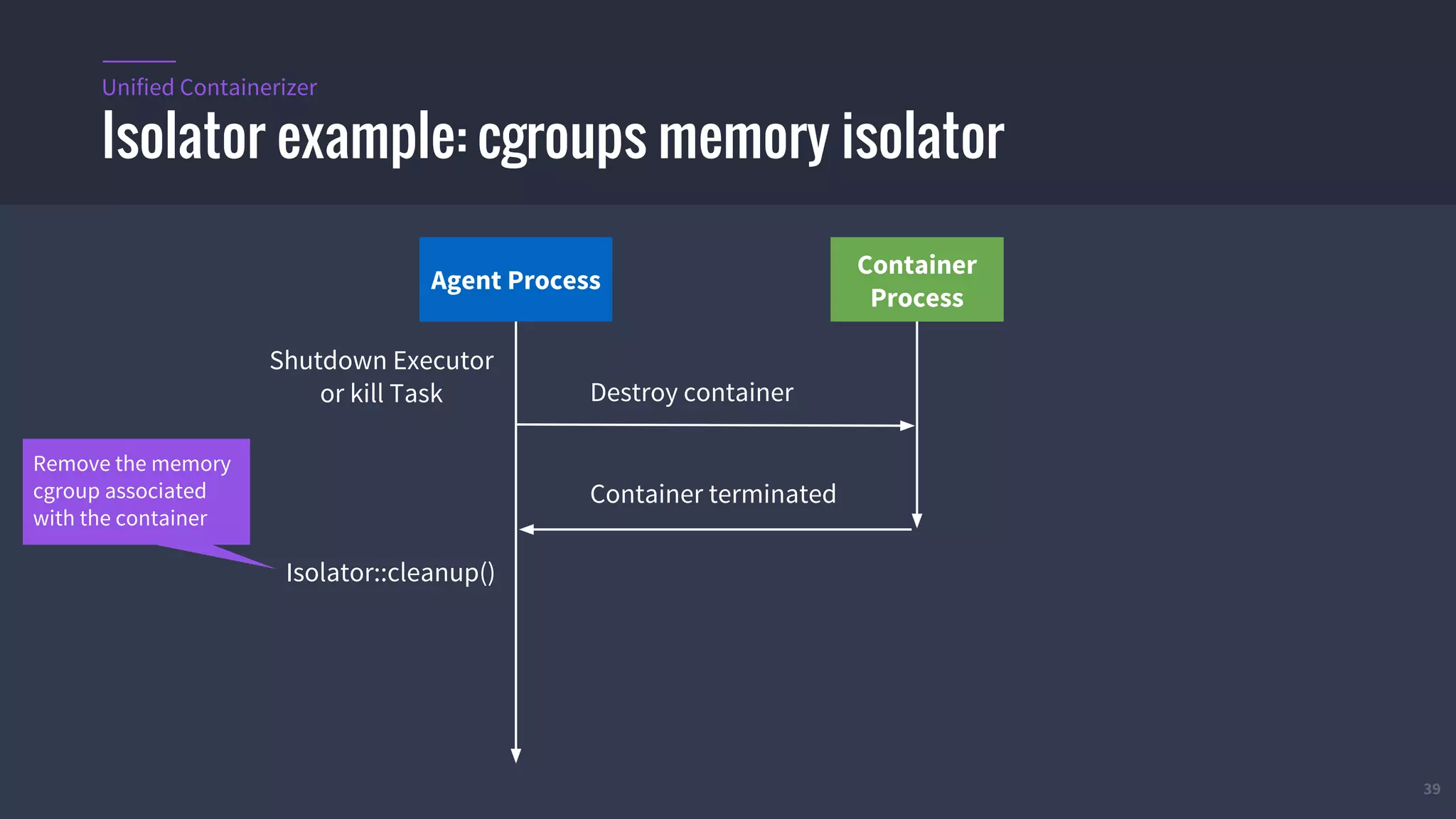


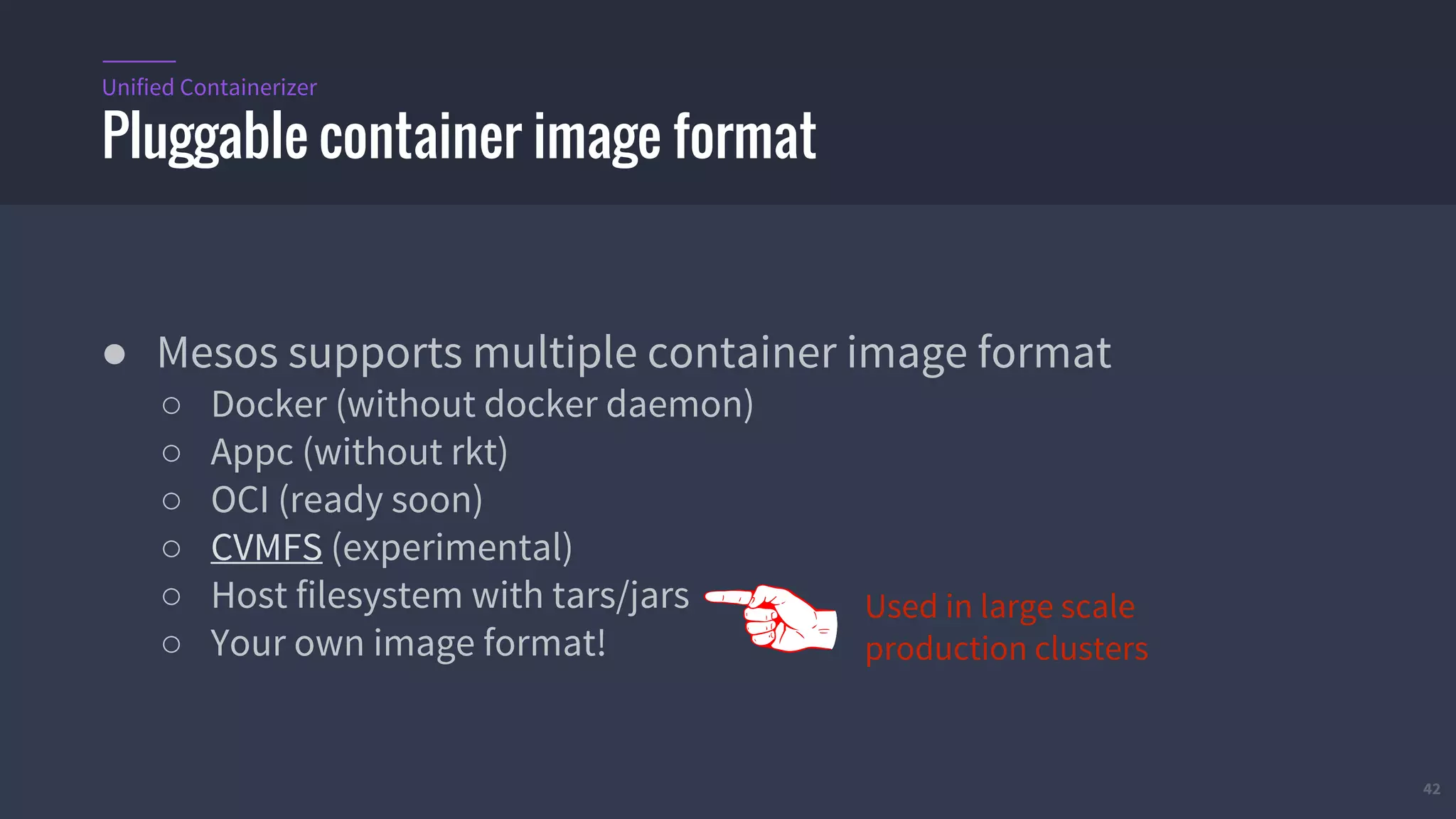



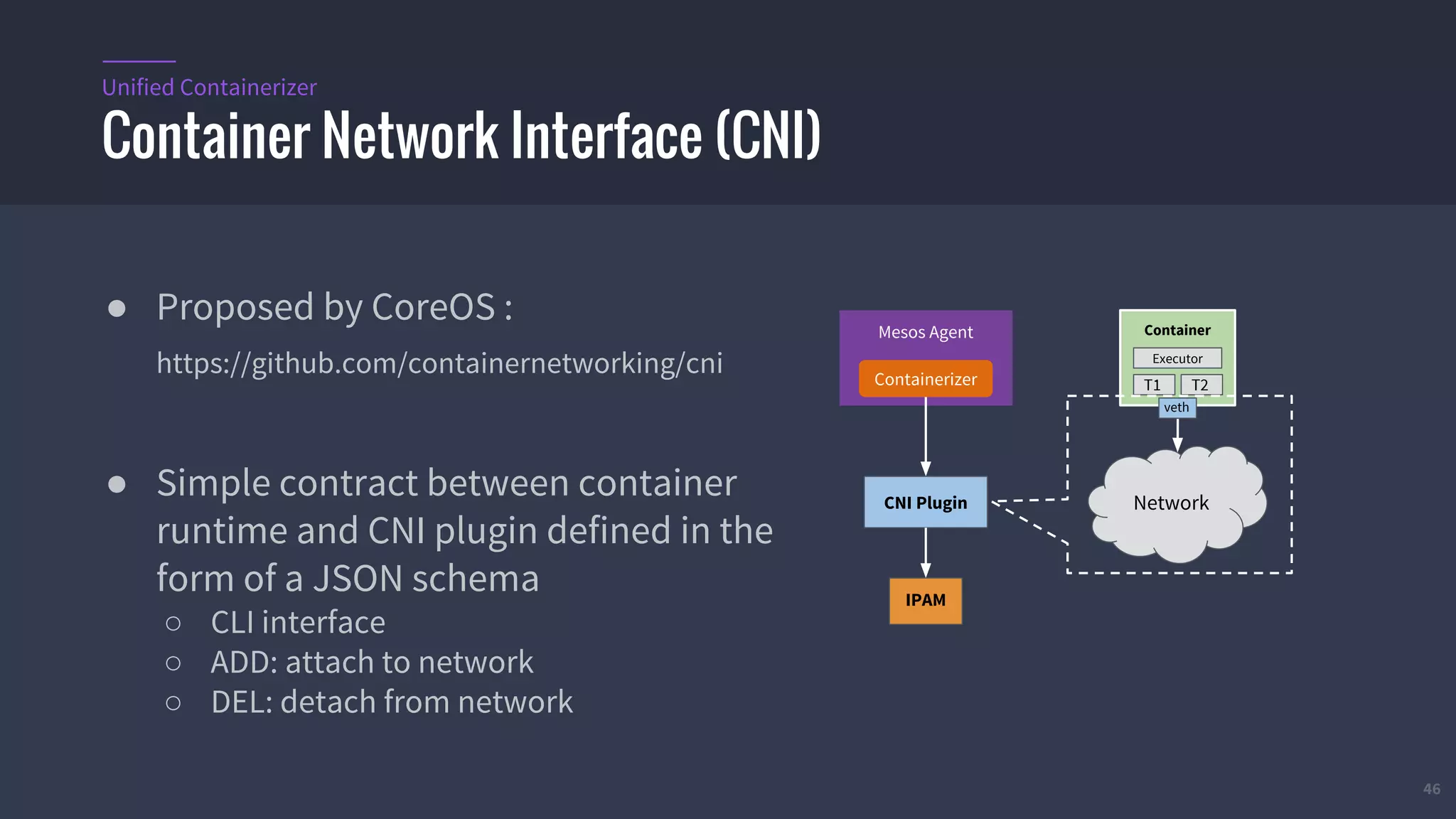

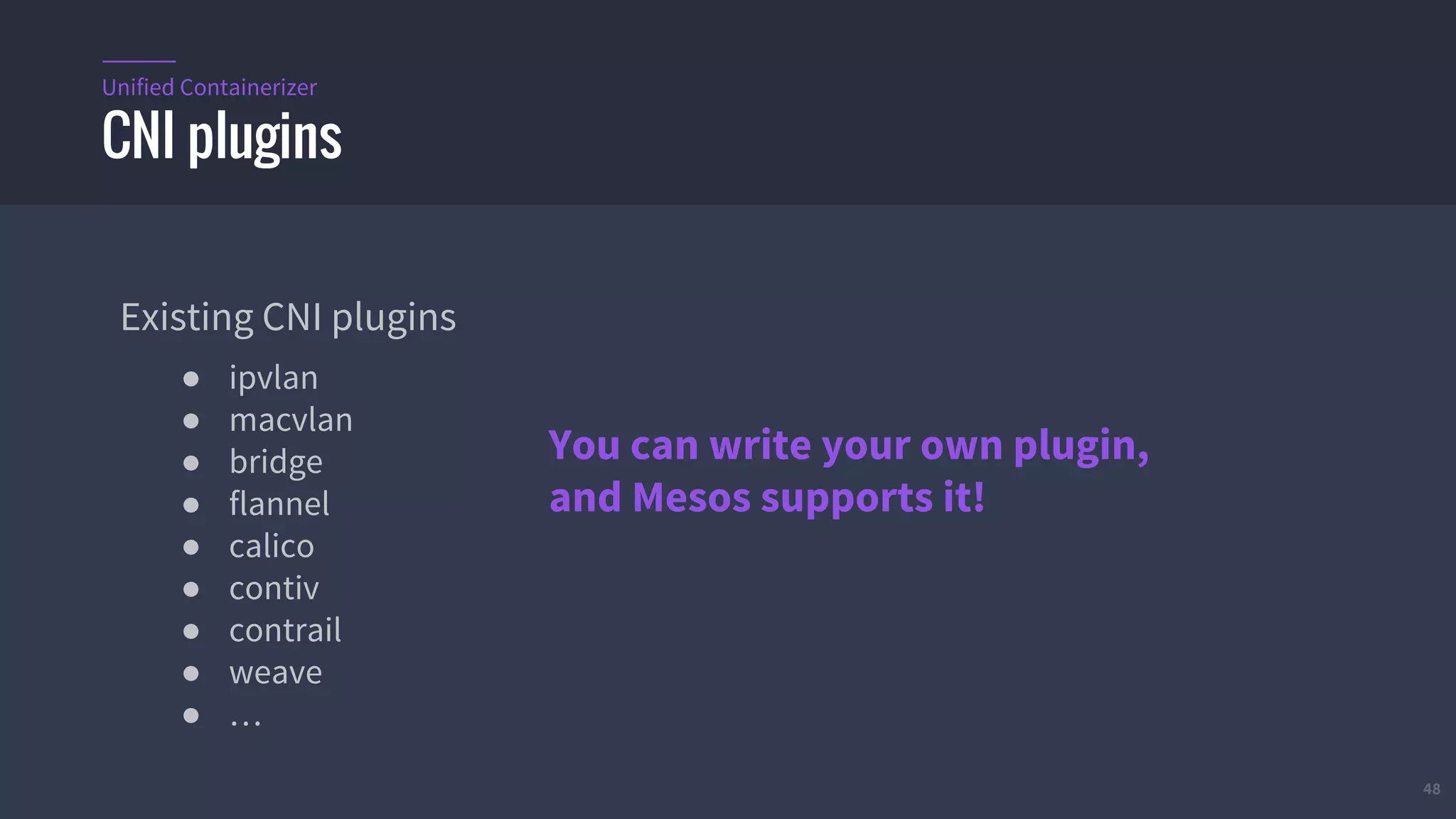



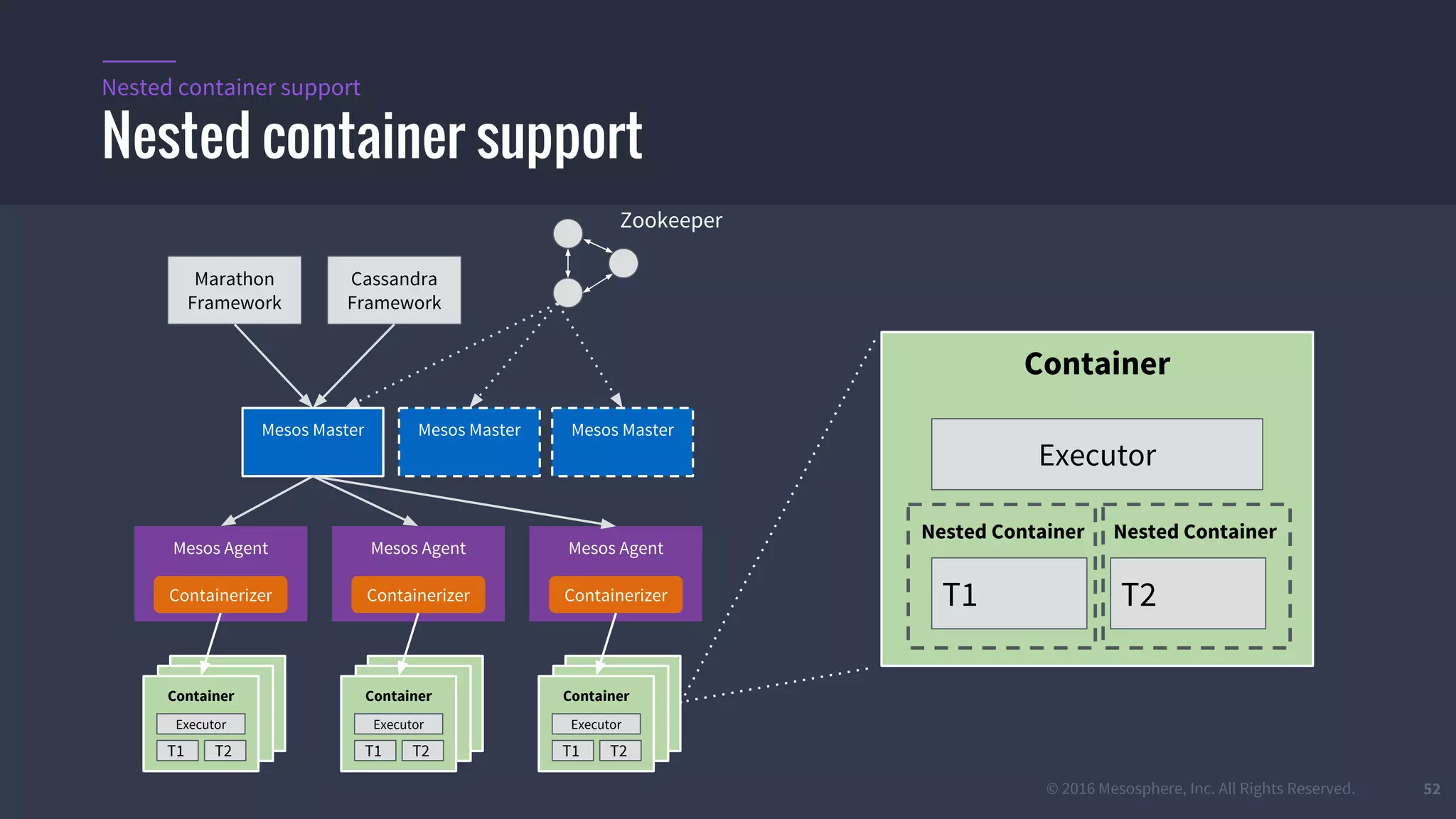

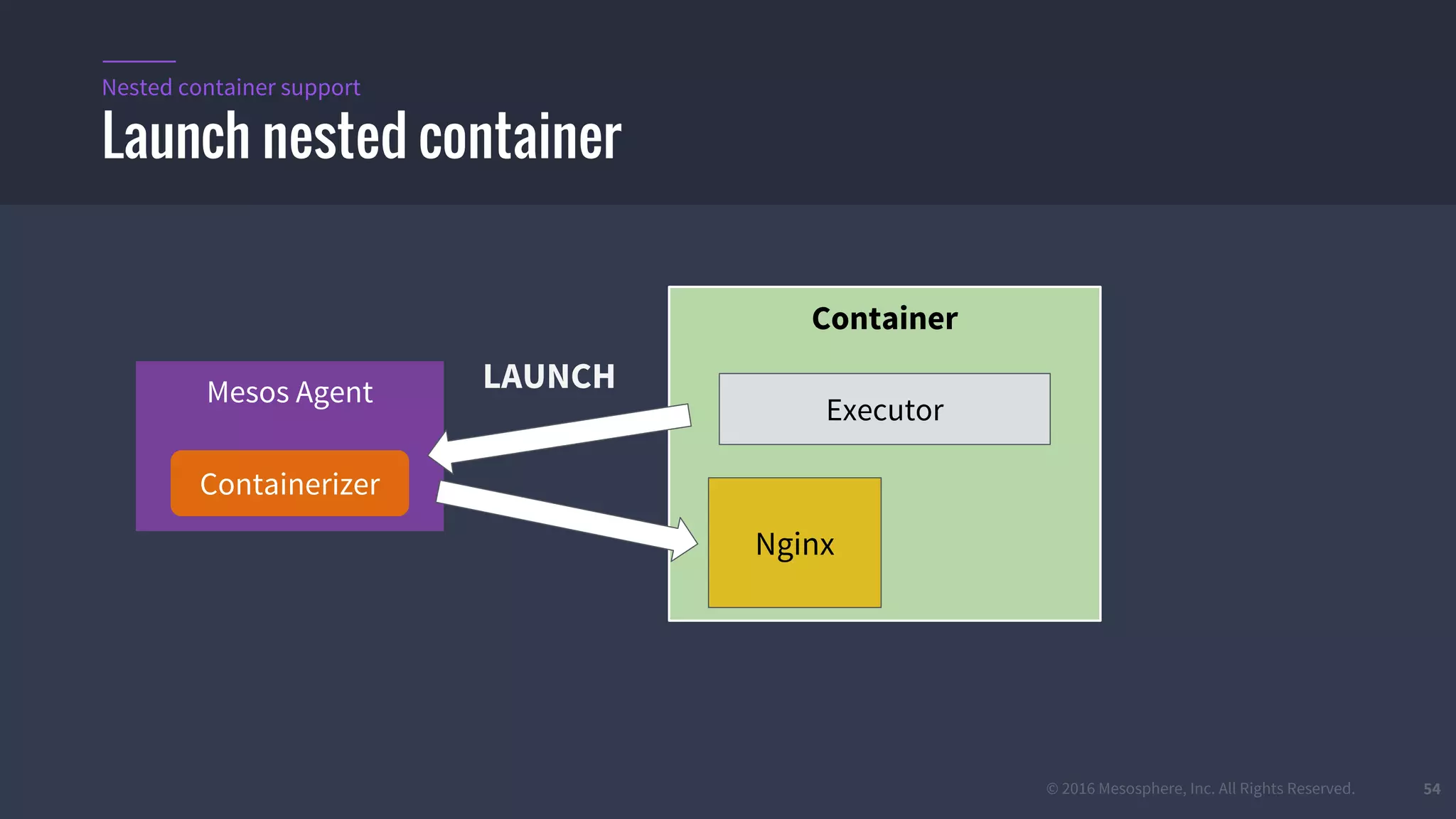
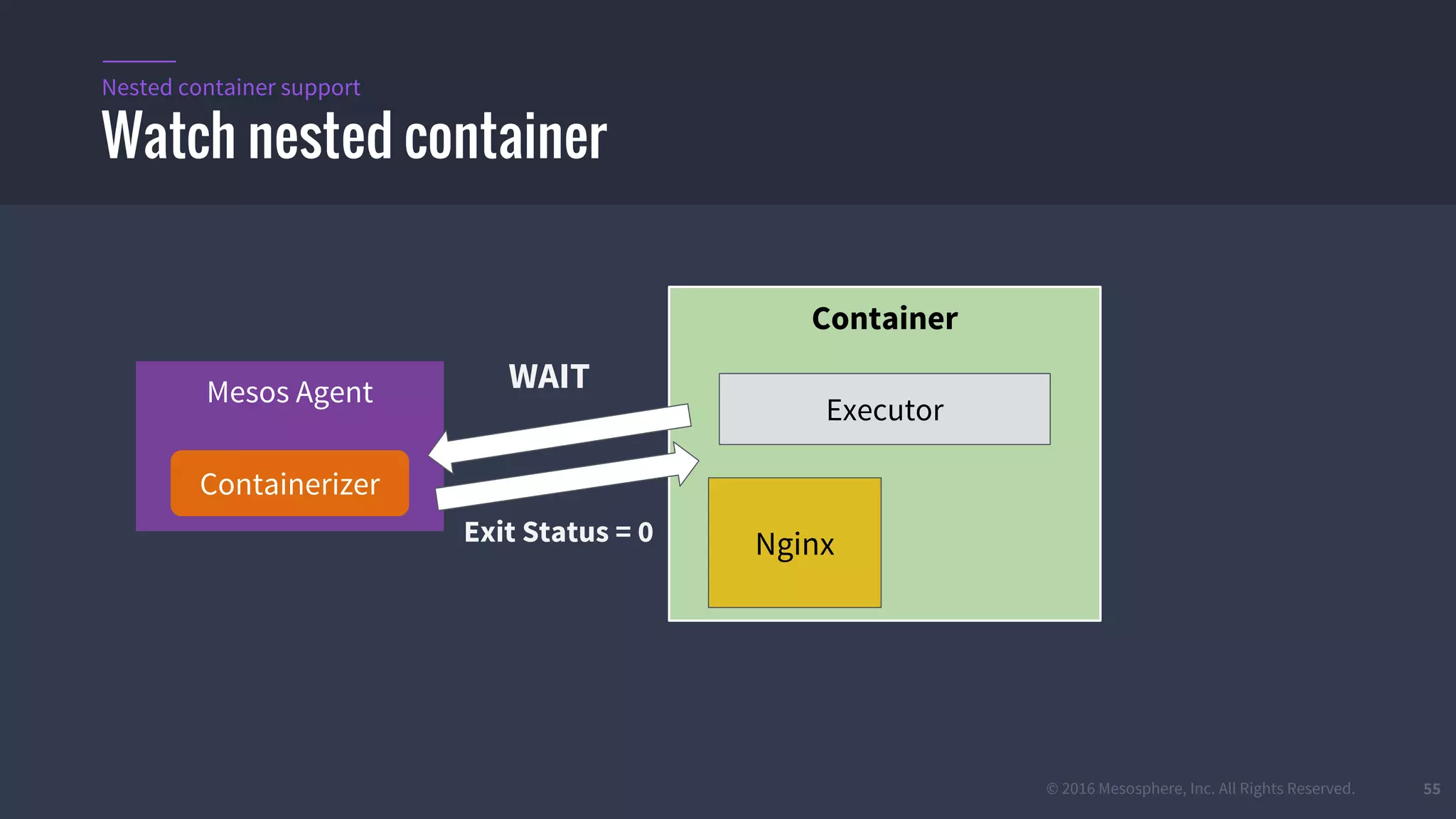
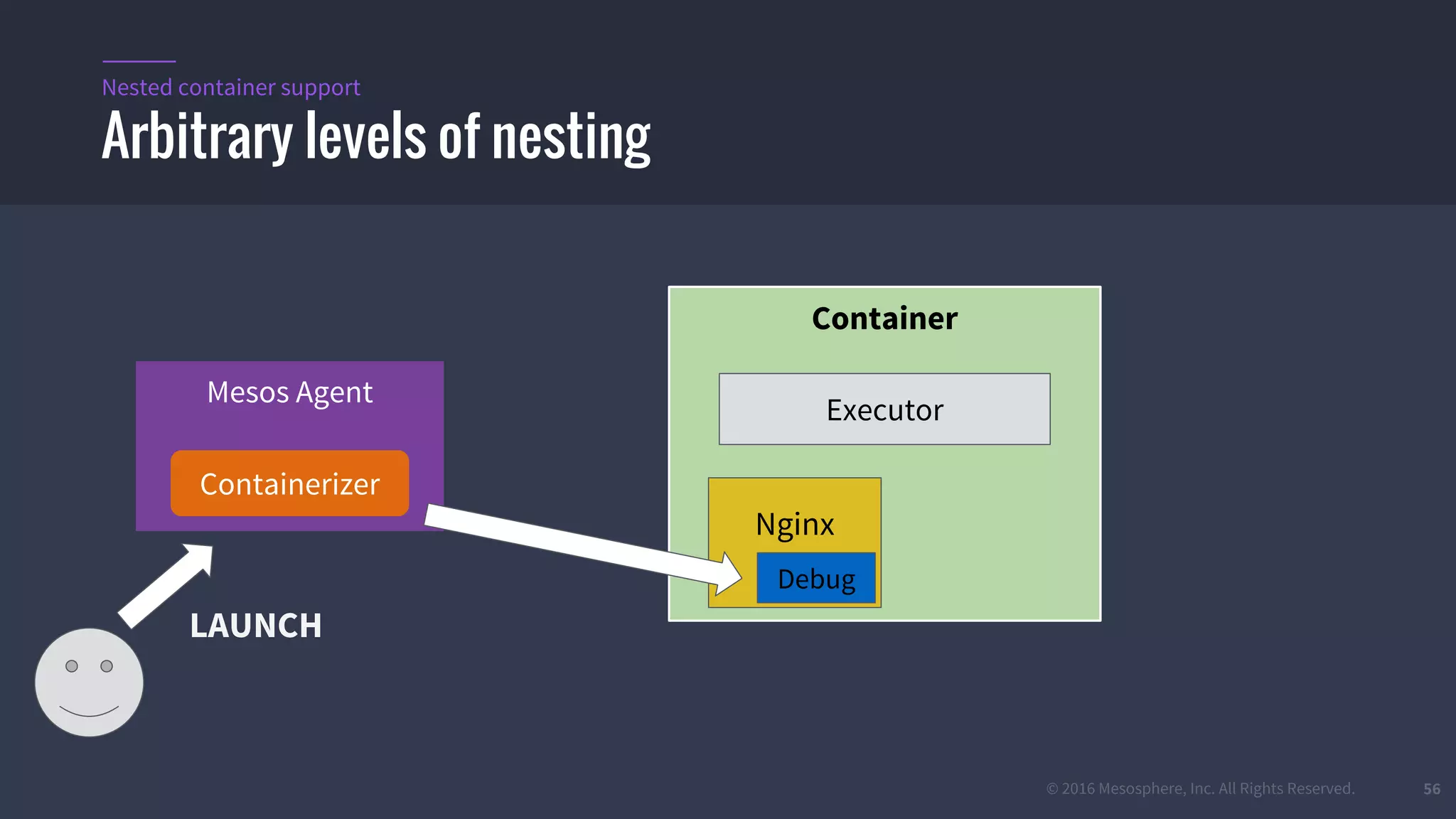



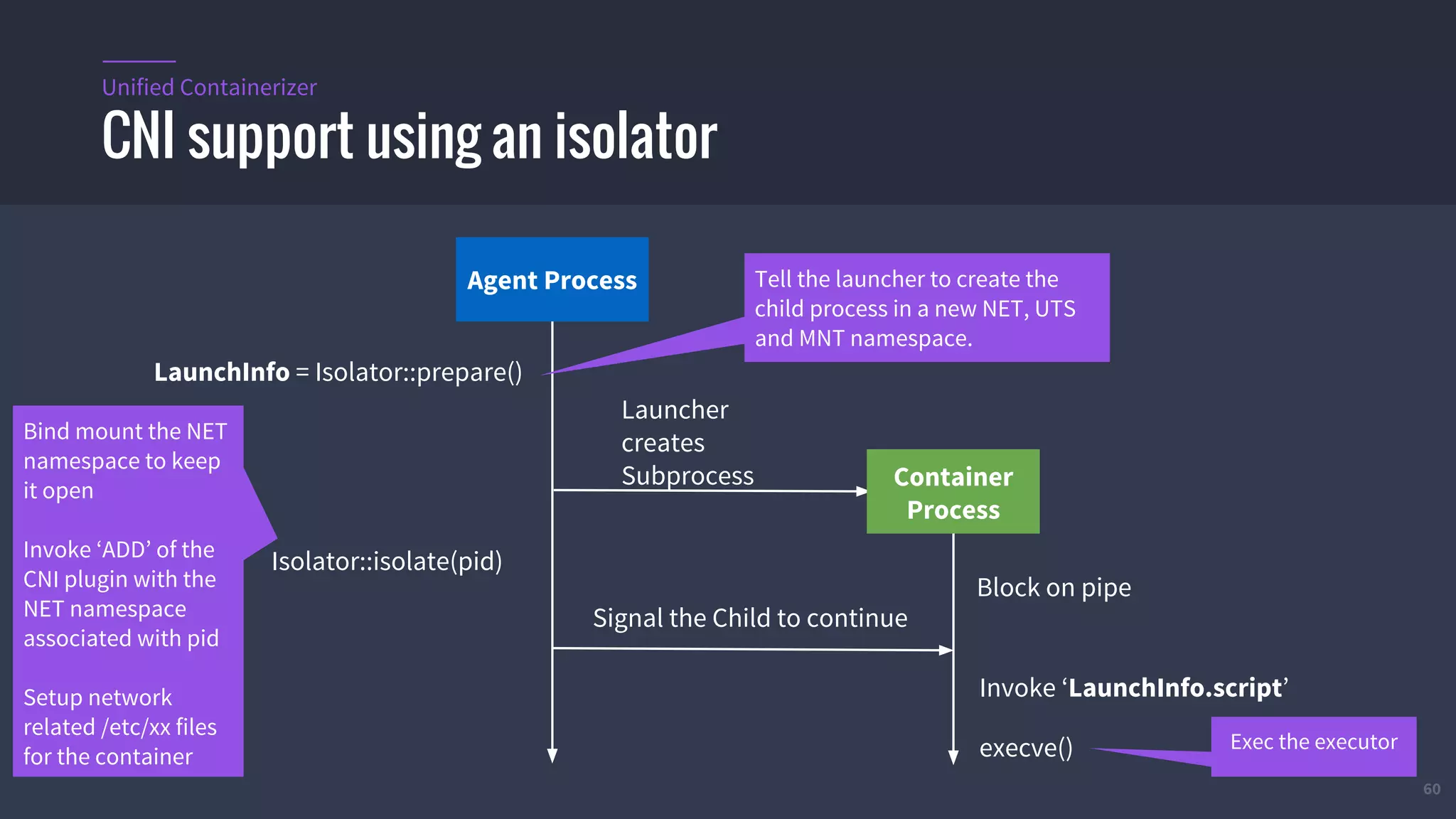
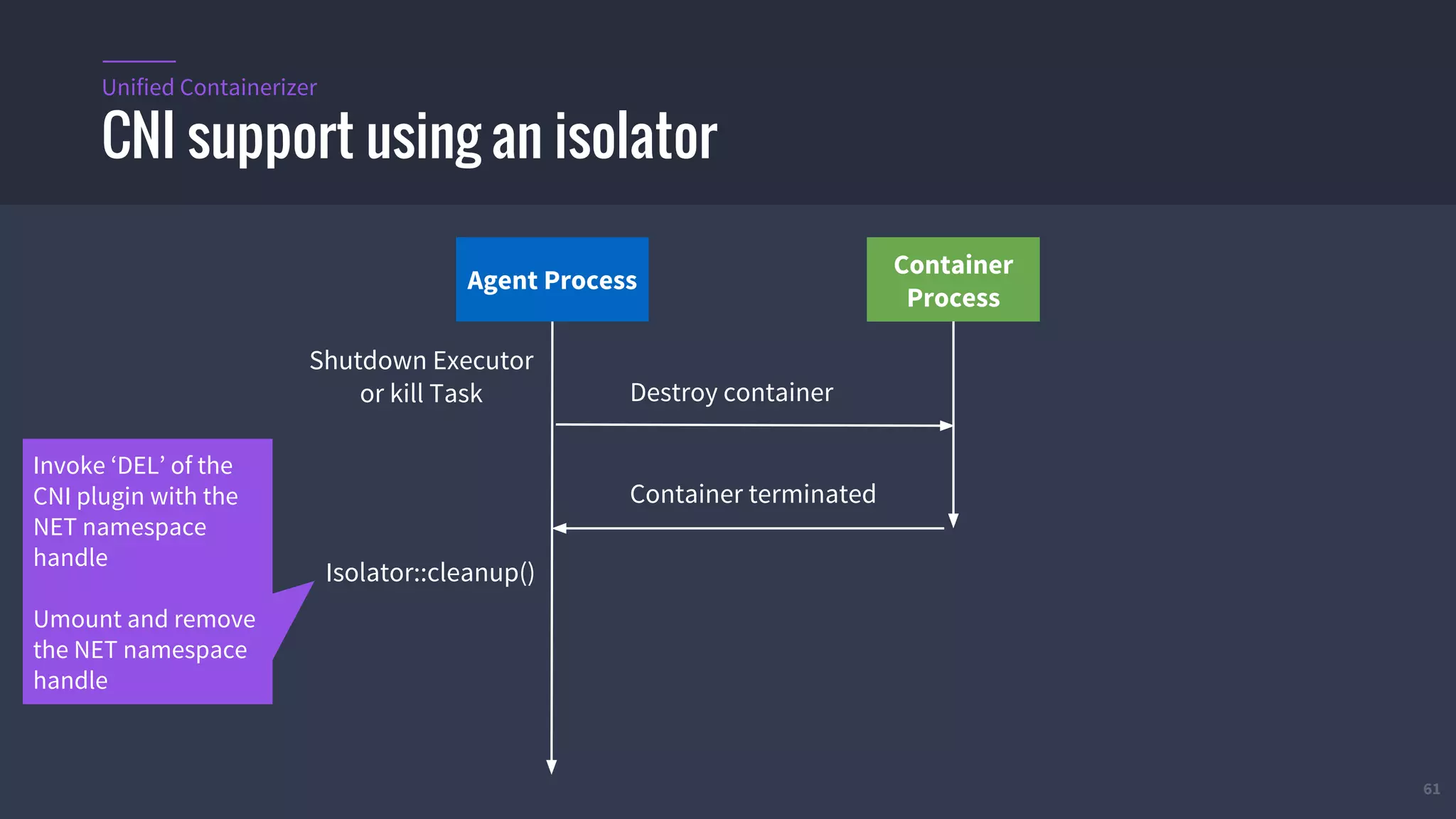



The document provides an overview of Mesos, a powerful container orchestrator designed for data center applications, emphasizing its state-of-the-art resource management and programming abstractions. It outlines key concepts, production readiness, proven scalability, and customizable features, such as pluggable schedulers and containerization options, including support for Docker and AppC images. Additionally, it highlights Mesos's usage in major companies like Twitter and Apple, showcasing its ability to handle large-scale deployments effectively.



































































































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


