Downloaded 246 times













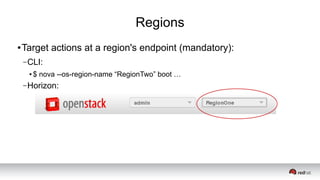
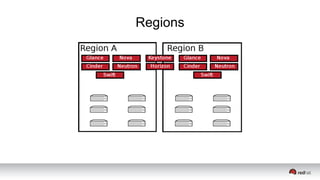
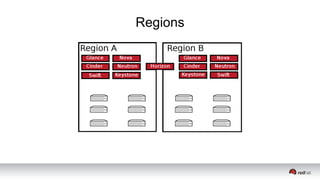
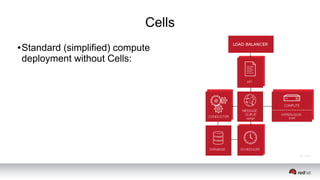
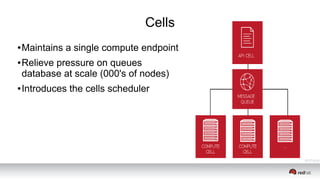
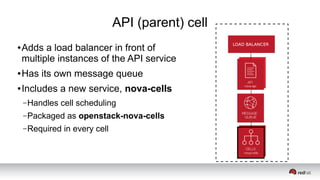
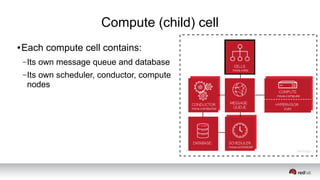








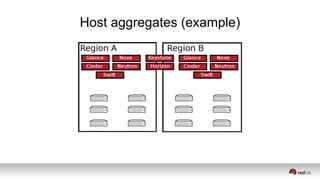
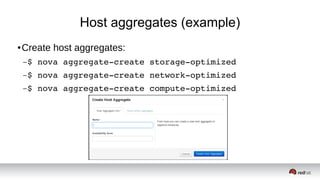


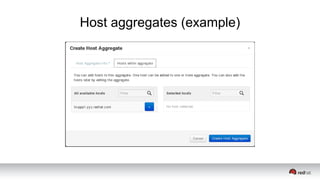
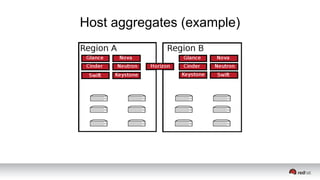
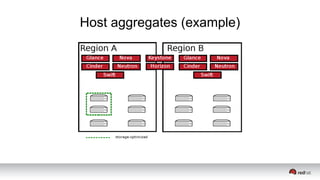
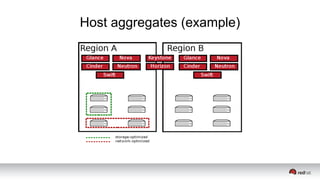
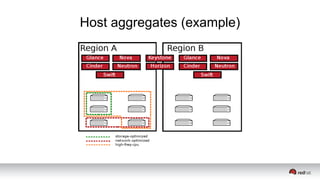
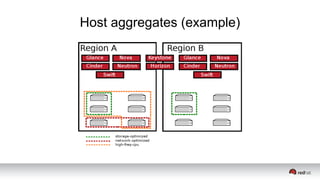

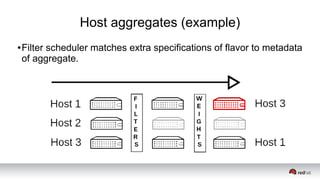


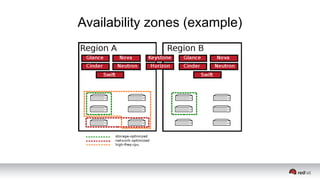
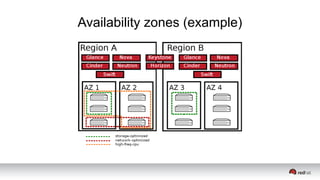





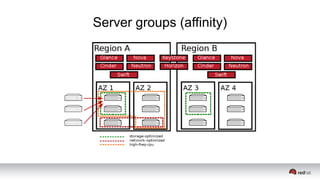
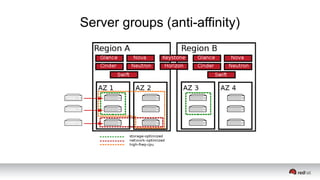




This document discusses resource segregation techniques in OpenStack clouds. It describes how infrastructure resources like compute hosts can be logically grouped using regions, cells, host aggregates, and availability zones. It also discusses workload segregation using server groups that define affinity and anti-affinity rules for instance placement. The goals of segregation include isolating workloads, ensuring high availability, and enabling horizontal scaling of the infrastructure.

















































![[Rakuten TechConf2014] [F-4] At Rakuten, The Rakuten OpenStack Platform and B...](https://cdn.slidesharecdn.com/ss_thumbnails/f4openstackrakutentechnologyconference20141025-141105211349-conversion-gate02-thumbnail.jpg?width=640&height=640&fit=bounds)








































