Download as PDF, PPTX



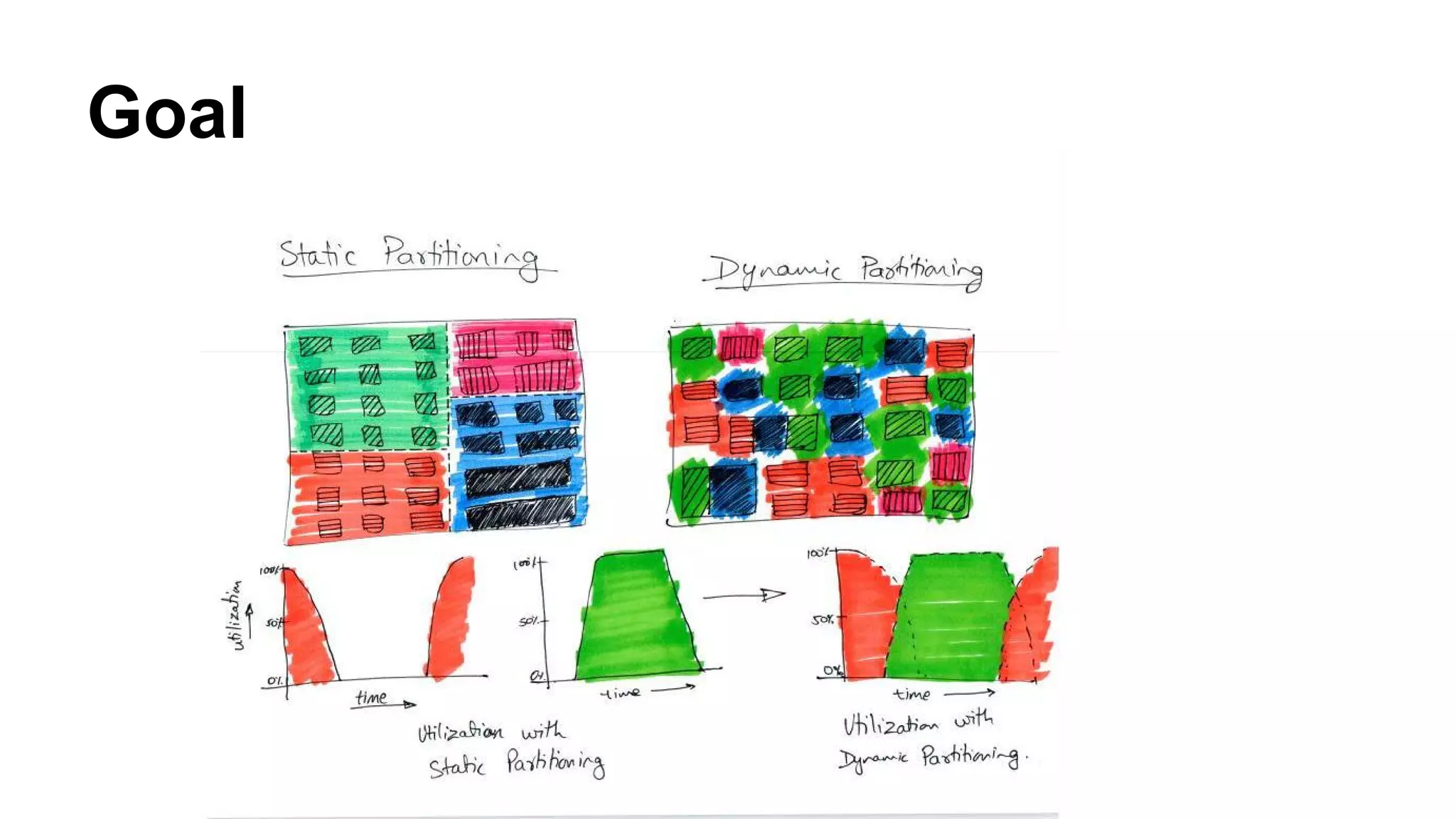
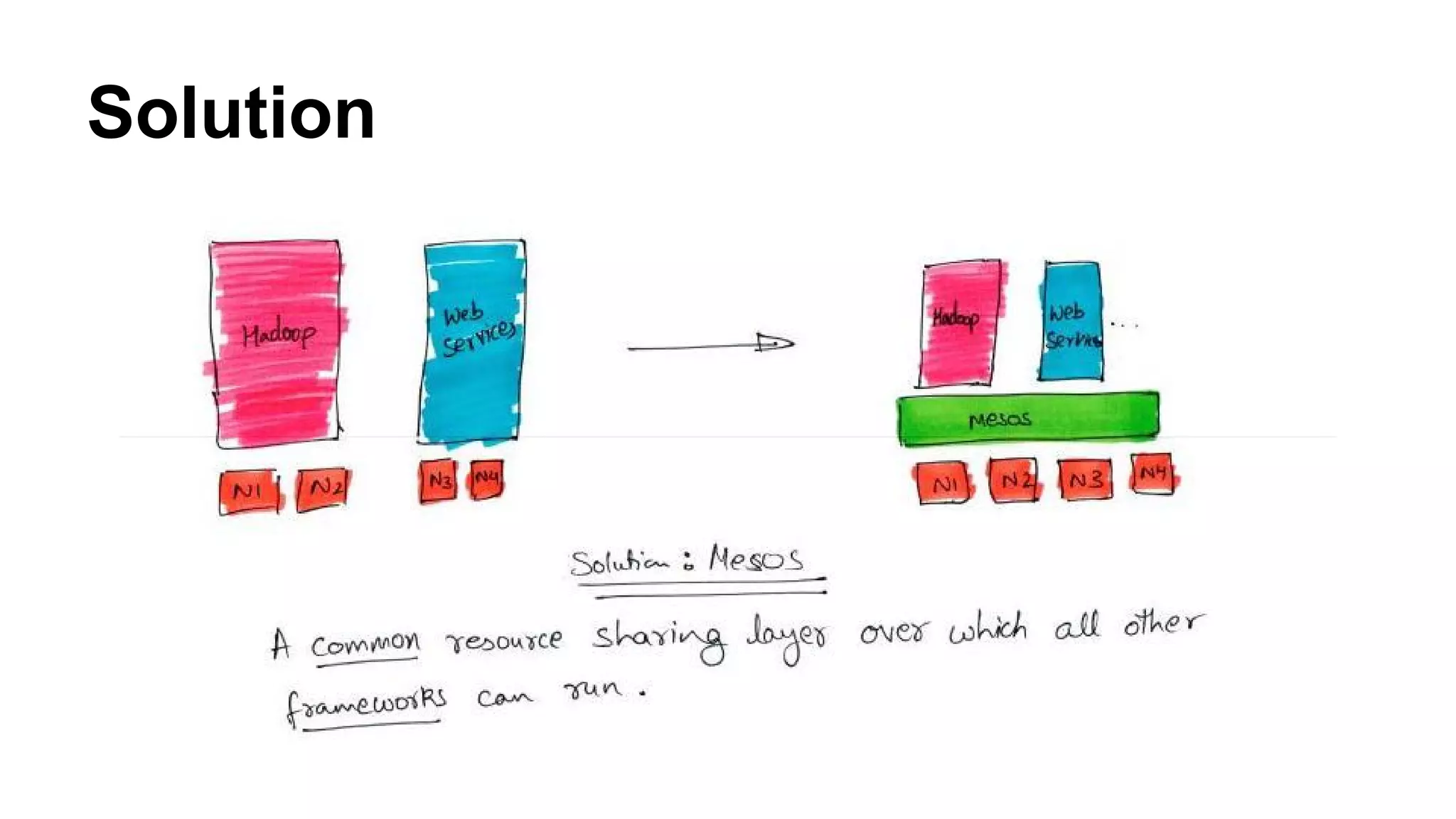



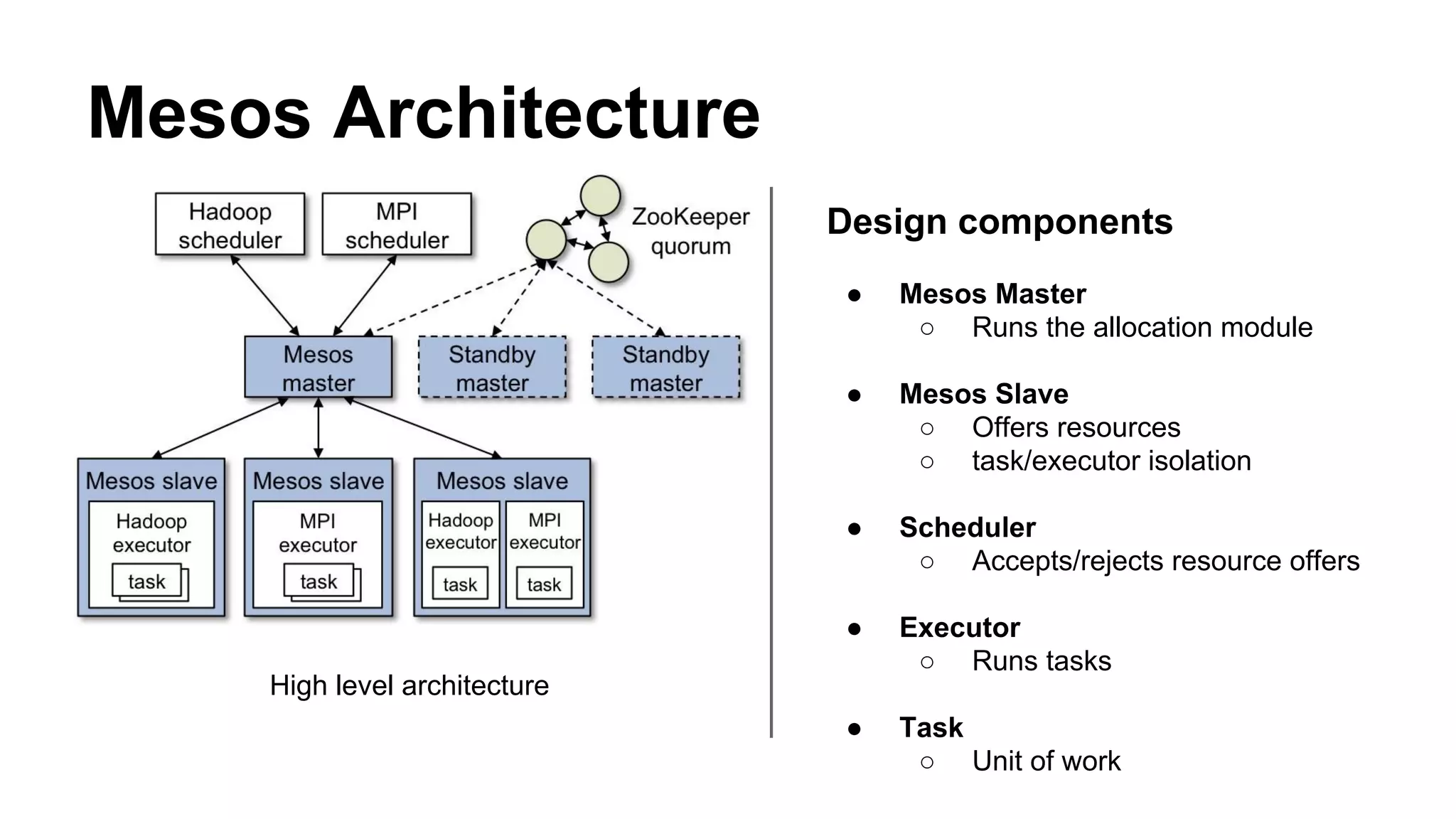

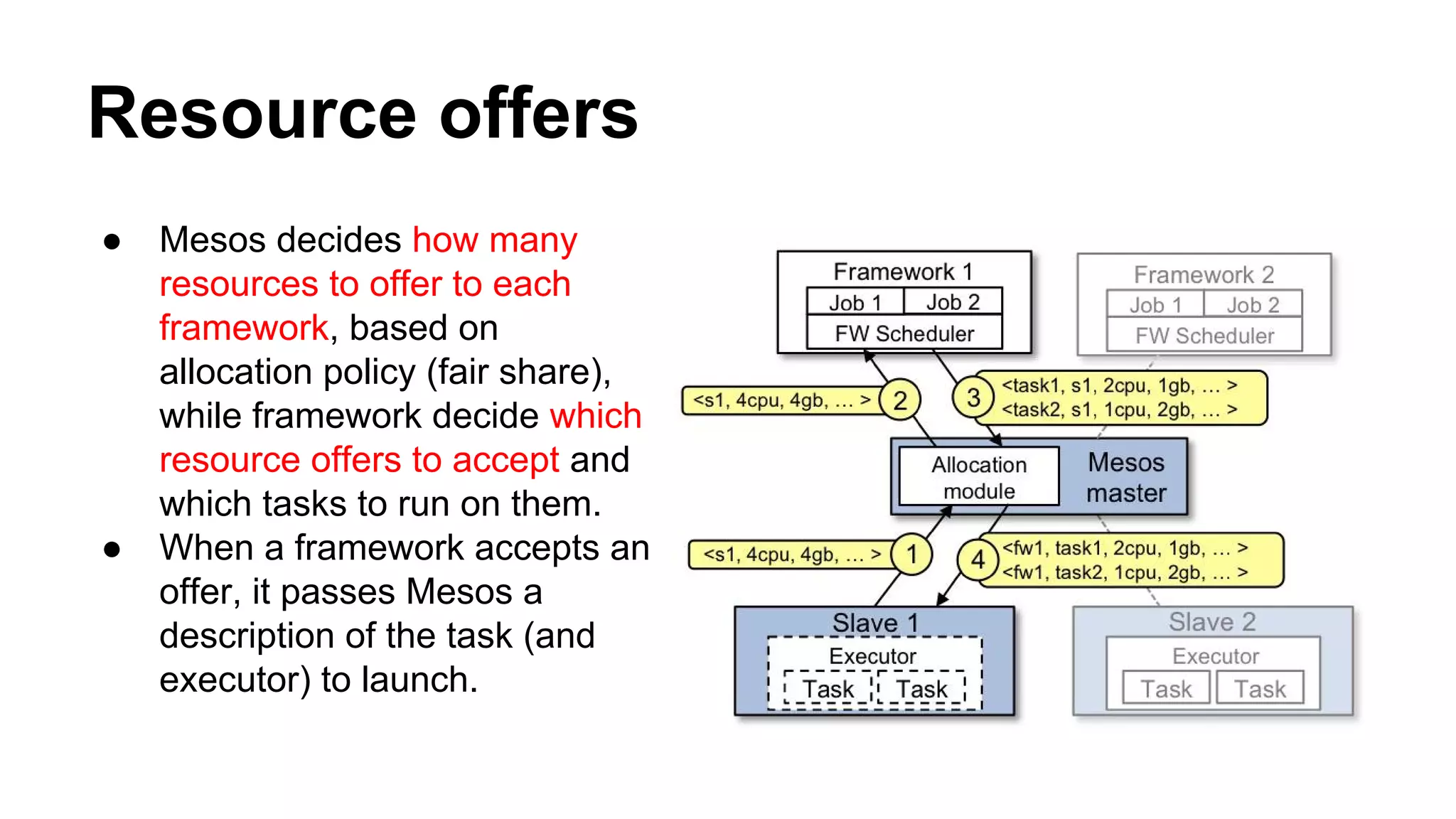






Mesos is a resource management platform aimed at fine-grained sharing in data centers, supporting diverse frameworks and maximizing resource utilization. It employs a two-level scheduling system to manage resource offers and task execution efficiently, ensuring fault tolerance and scalability. The system has demonstrated improvements in data locality and performance, achieving significant speedups and effective failure recovery.



































































