Downloaded 20 times


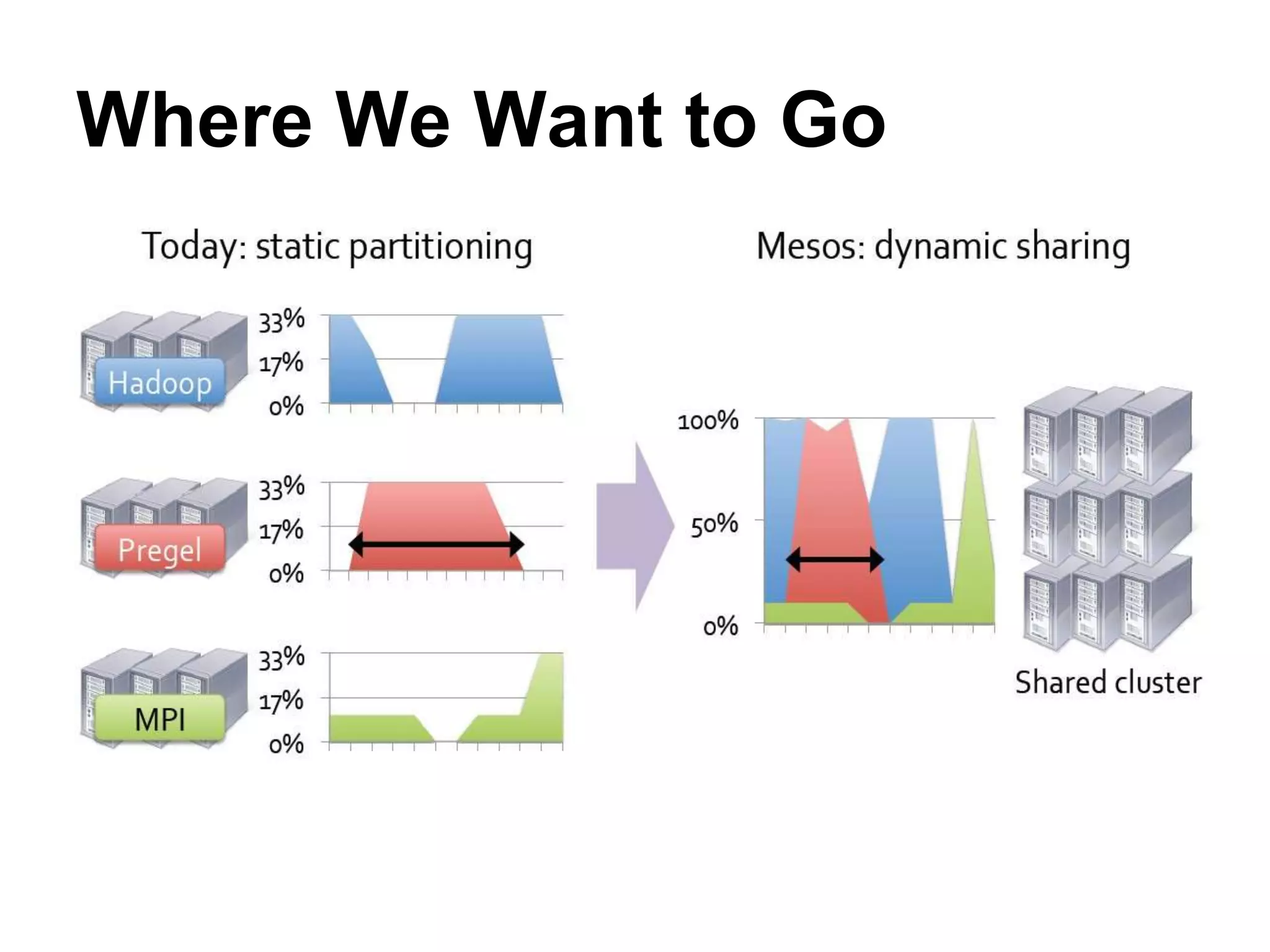
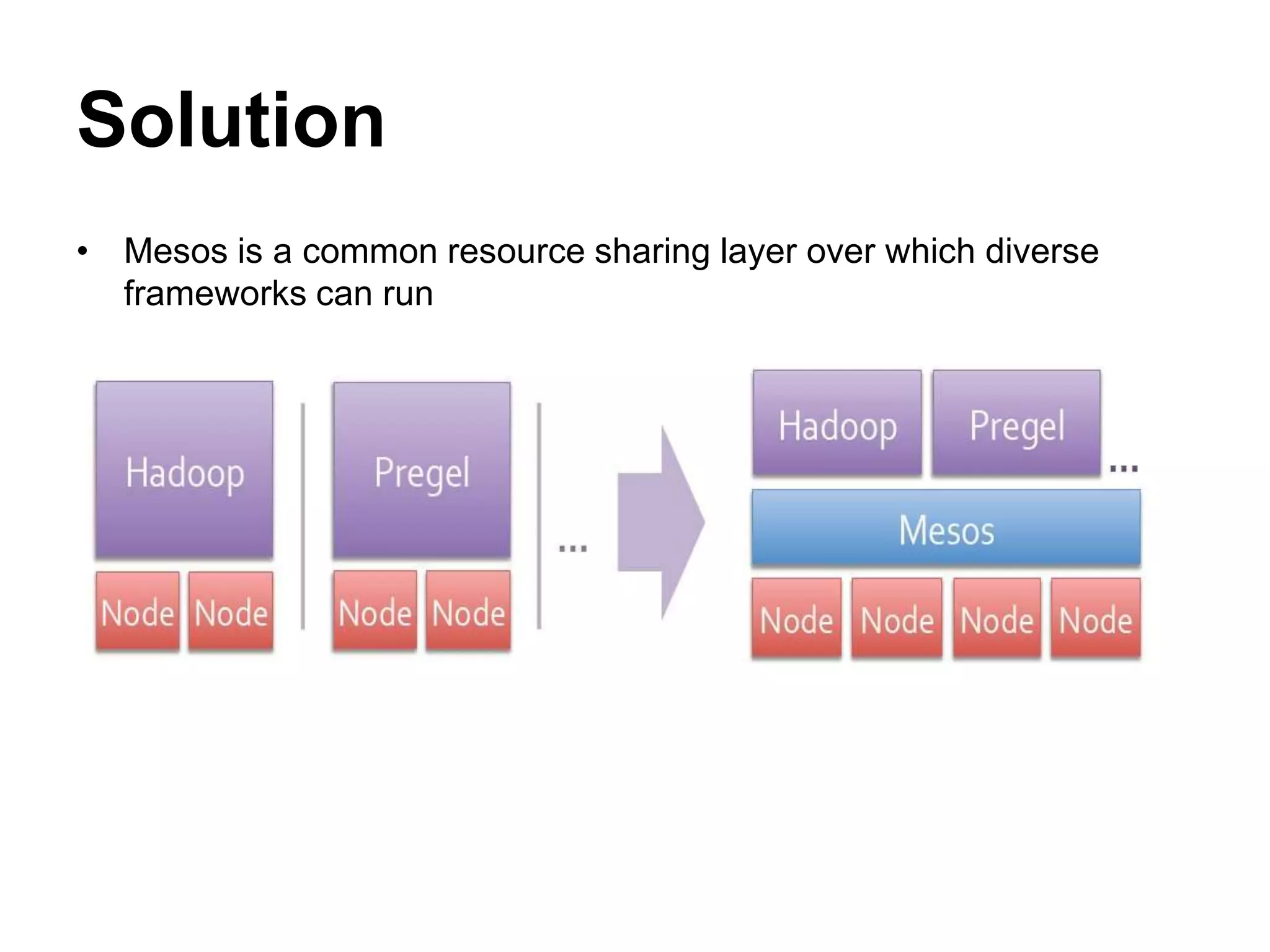


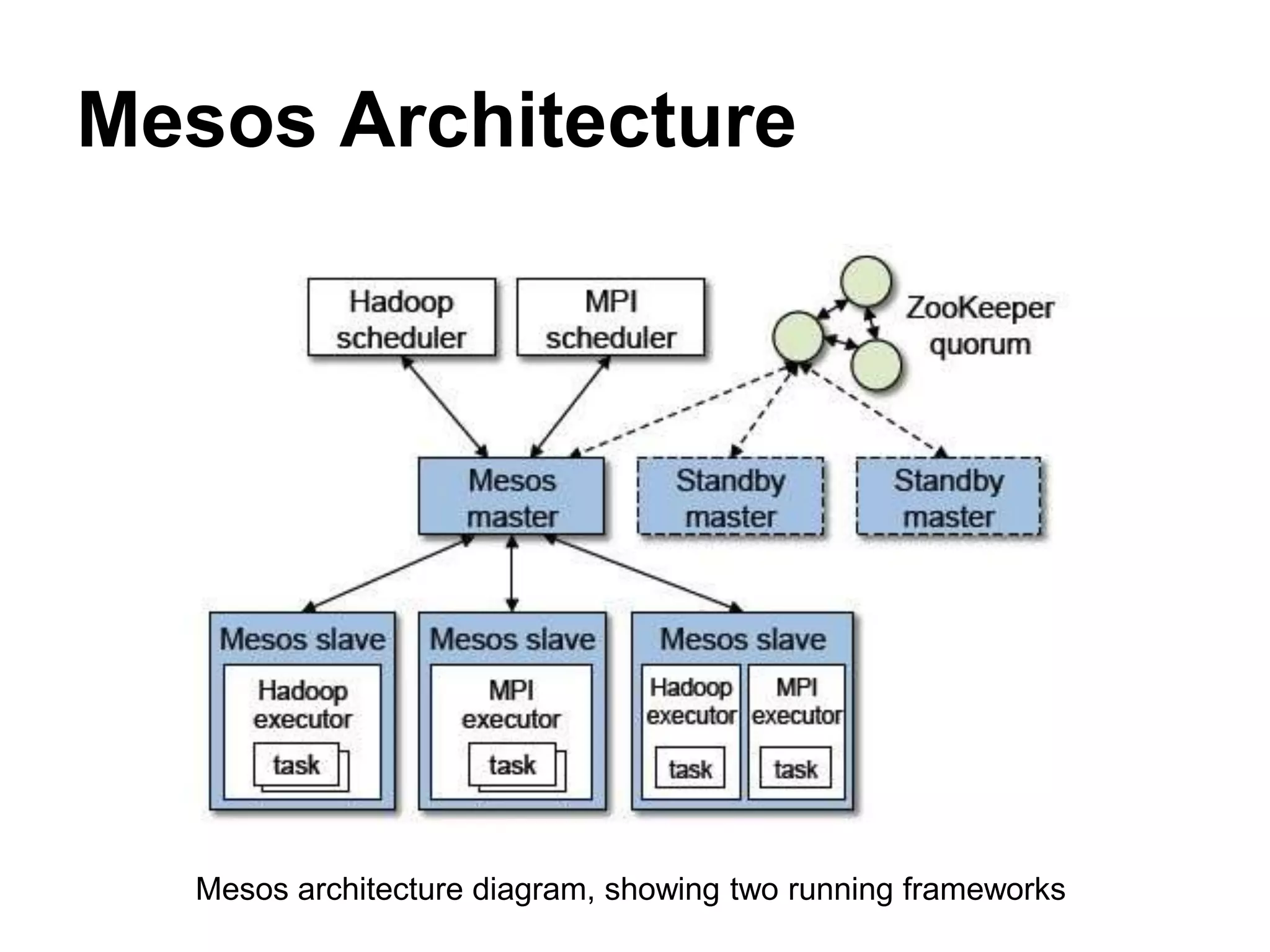


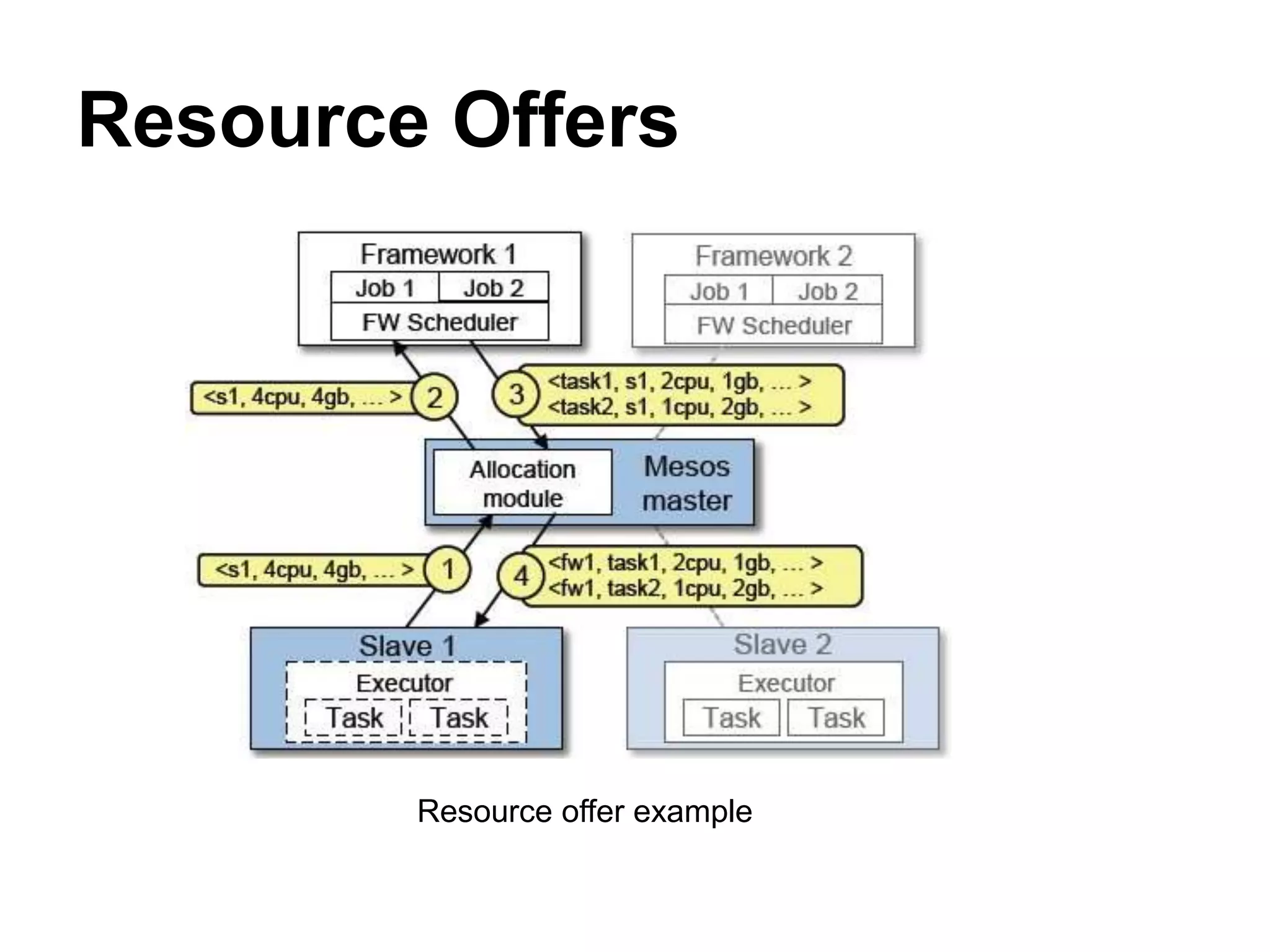
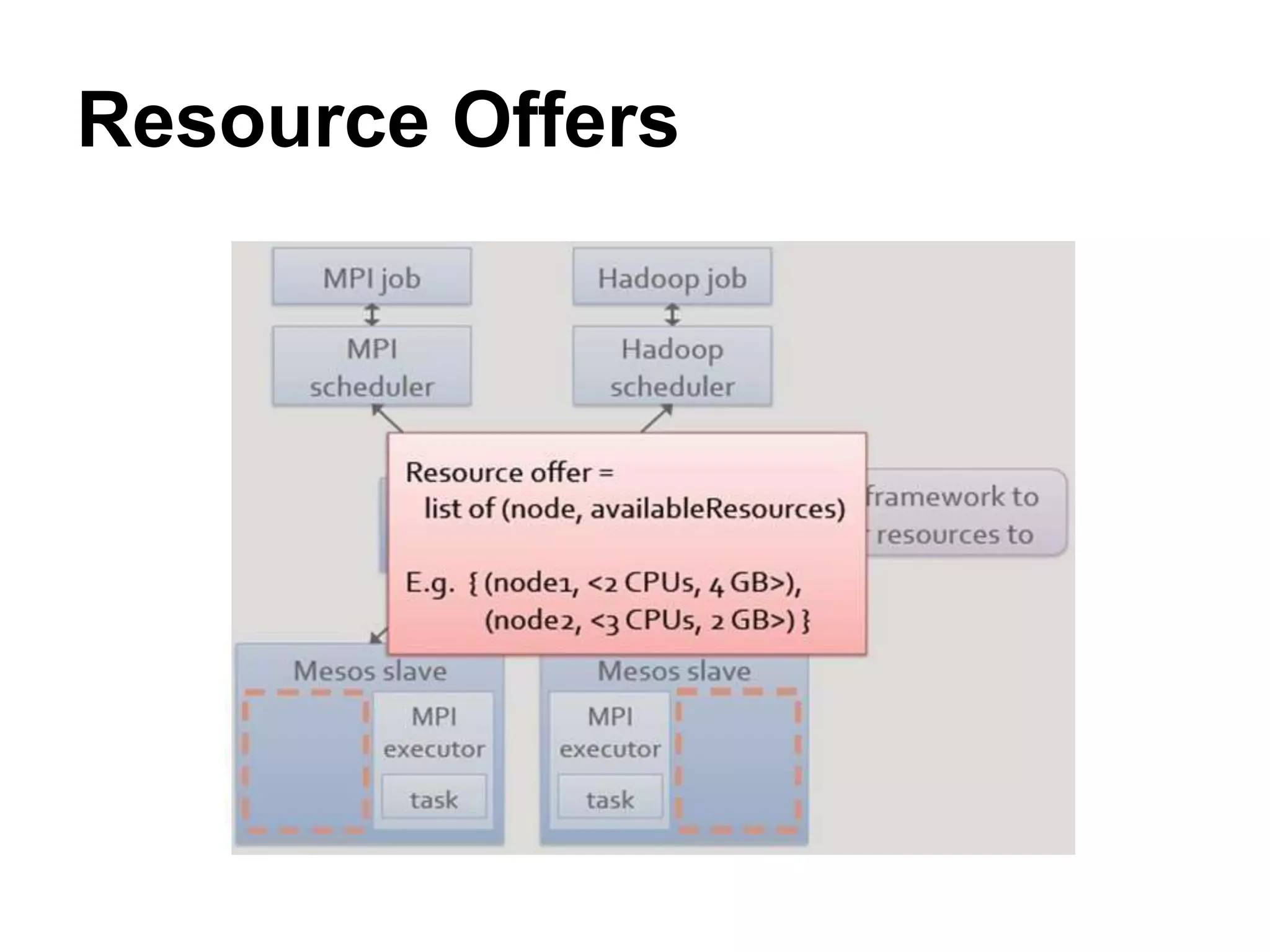
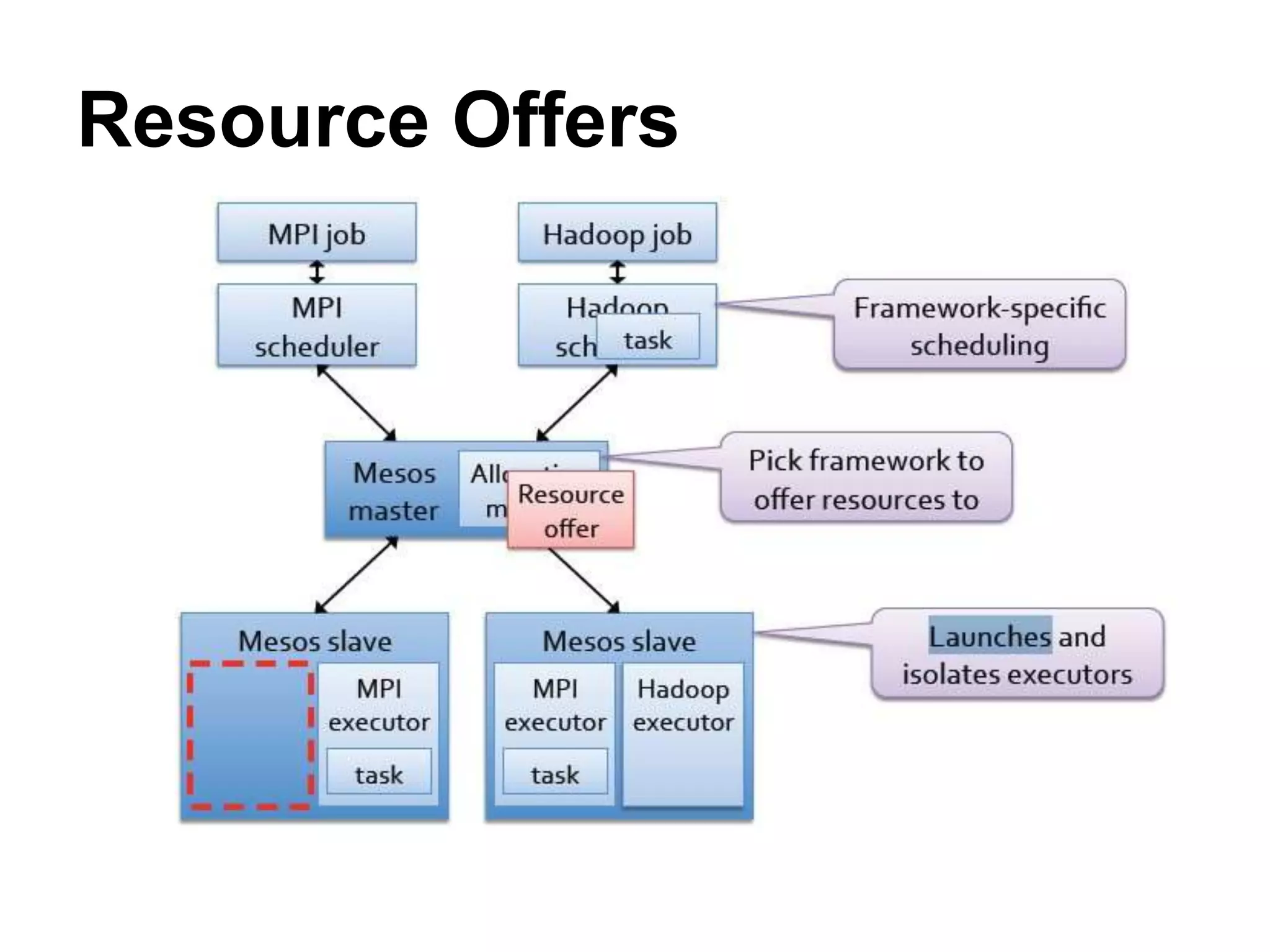






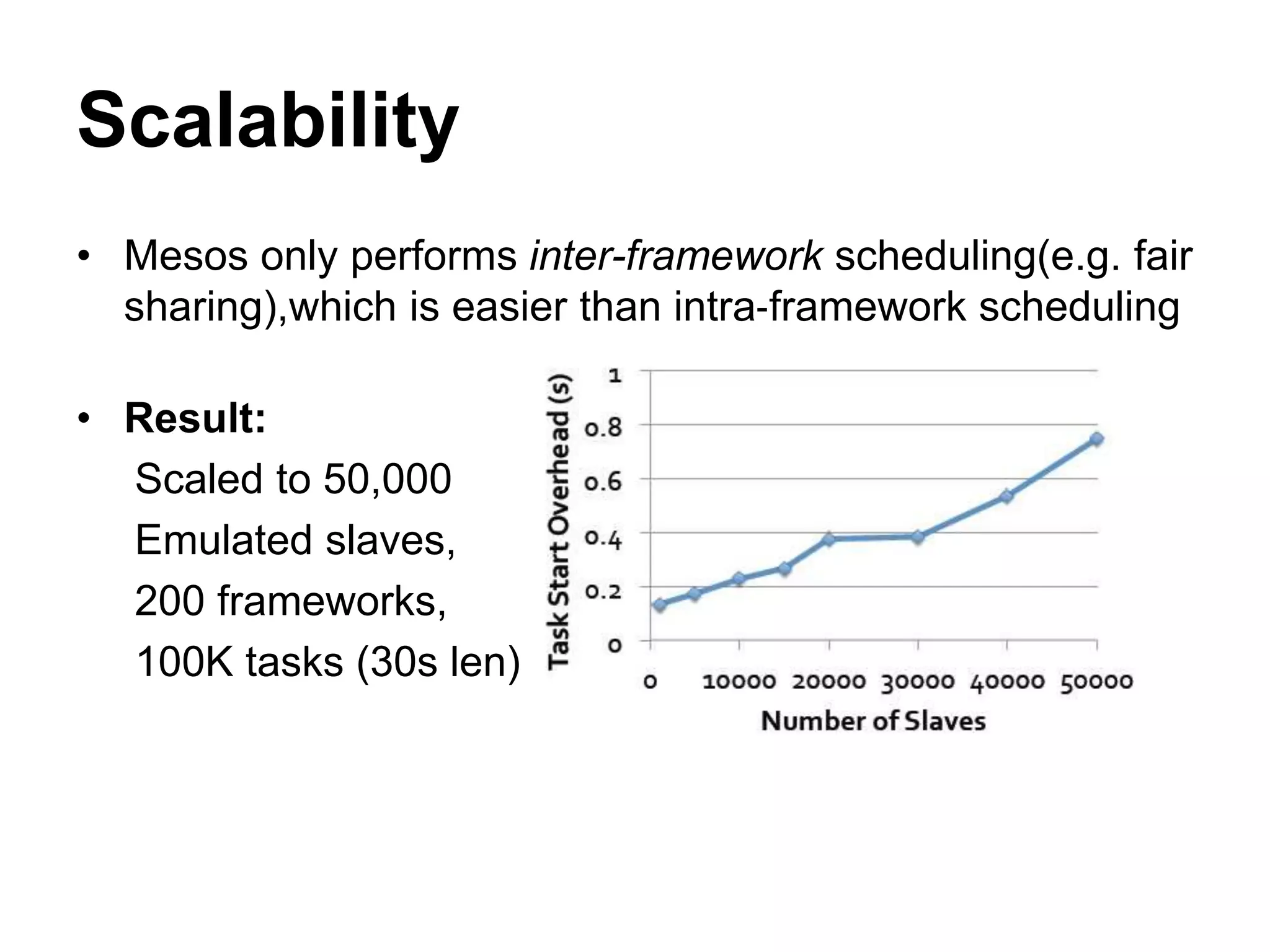


Mesos is a platform that enables sharing of cluster resources between different frameworks. It achieves this through a two-level resource sharing approach: 1) Mesos manages coarse-grained sharing of resources like CPUs and memory between frameworks; 2) Frameworks control fine-grained sharing of tasks within their allocated resources. Mesos's use of resource offers allows frameworks to dynamically accept or reject resources based on their needs, improving cluster utilization. It has been used successfully at large companies to share resources between frameworks like Hadoop and Spark.



















































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)






![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







