Download to read offline



![“No one size fits all”
● “A panoply of data models, and they typically operate on flexible storage
formats such as JSON” [1]
● “Increasingly, we see applications that deploy multiple engines, resulting in a
need to join data across systems.” [1]
● “Increasingly, desktop and mobile applications are using the cloud
infrastructure to take advantage of the high-availability and scalability
characteristics. In the past, these type of systems used local databases to
store information and application state. There are many new applications that
share some or all their data with applications running on other hosts or in the
cloud and use these data stores for persistence.” [2]](https://image.slidesharecdn.com/sbrc-v2-151123133558-lva1-app6892/85/Design-of-Experiments-on-Federator-Polystore-Architecture-3-320.jpg)
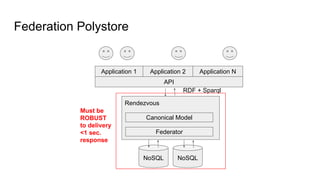
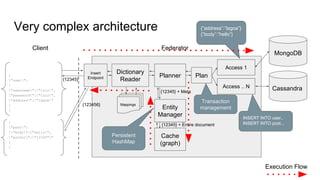
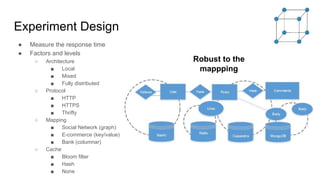

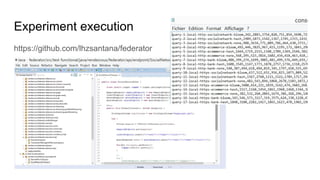

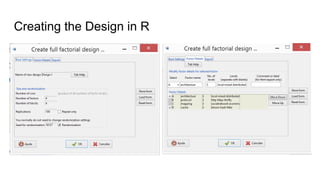

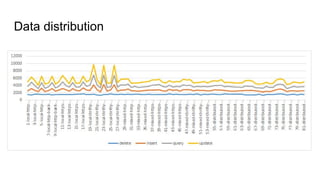


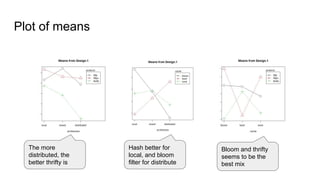




The document discusses the design of experiments on a federator polystore architecture, emphasizing the need for robustness in response times and mapping variations across different architectures and protocols. It outlines an experimental approach with multiple factors, including architecture type, protocol choice, mapping strategies, and caching mechanisms, and includes hypothesis testing and data analysis. The conclusions emphasize the challenges encountered, such as high variability in query times and the impact of architecture on memory usage, while identifying future work needed to explore mixed queries and fully distributed systems.










































































































