Download to read offline



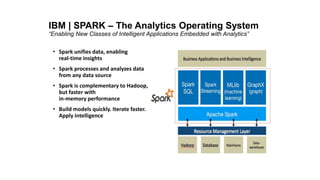

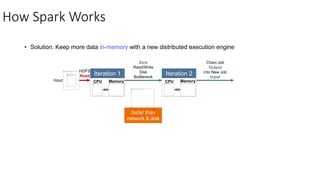
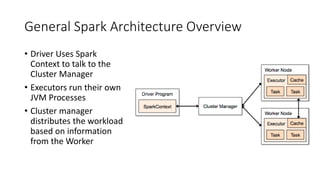




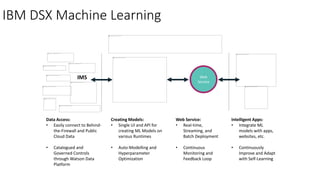


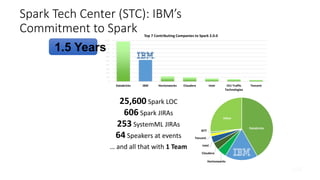
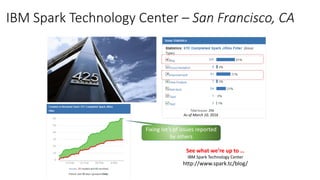





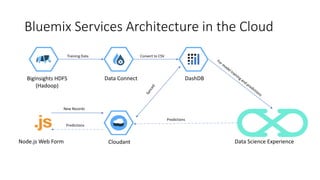
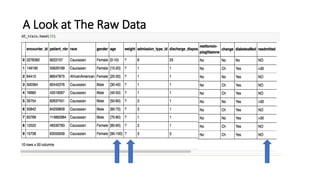

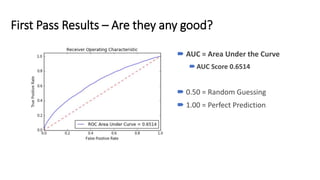
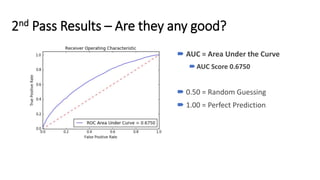
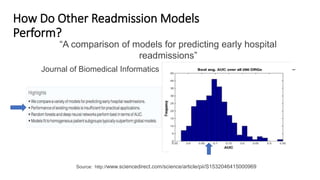





This document provides an introduction and overview of Spark: - Spark is an open-source in-memory data processing engine that can handle large datasets across clusters of computers using an API in Scala, Python, or R. - IBM is heavily committed to Spark, contributing the most code and fixing the most issues reported by other organizations to continually improve the full analytics stack. - An example is presented on using Spark to predict hospital readmissions from diabetes patient data, obtaining AUC scores comparable to other published models.























































































