Downloaded 48 times





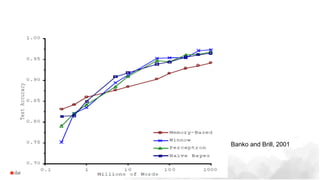







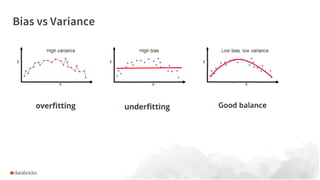

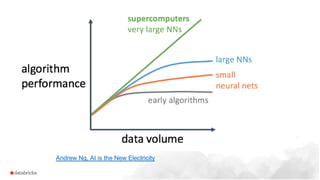










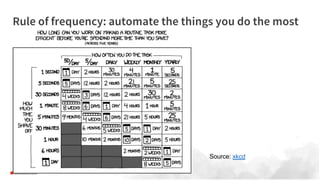
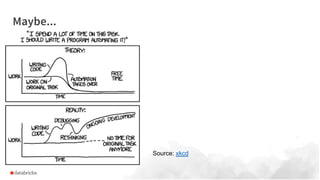




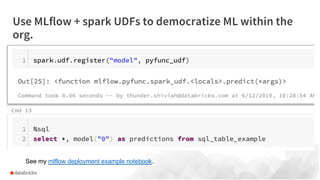



Larger datasets enhance deep learning models in high variance areas like NLP and images, but do not substantially improve traditional ML in high bias domains. Transfer learning is often more effective than distributed data models when more data reaches its limits. Databricks addresses challenges faced by data scientists, such as parallel model running and automating setups, using tools like pandas UDFs, ML runtime, and MLflow.























































































