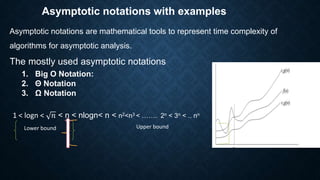
The document outlines the importance of algorithms in solving problems and their role in computer systems, highlighting key concepts such as asymptotic notations and performance analysis. It details the three types of algorithm analysis: worst case, average case, and best case, alongside explanations of theta, big O, and omega notations for representing time complexity. The conclusion emphasizes the significance of understanding time and space complexity while also mentioning the advantages and disadvantages of measuring algorithm performance.