Download as PDF, PPTX



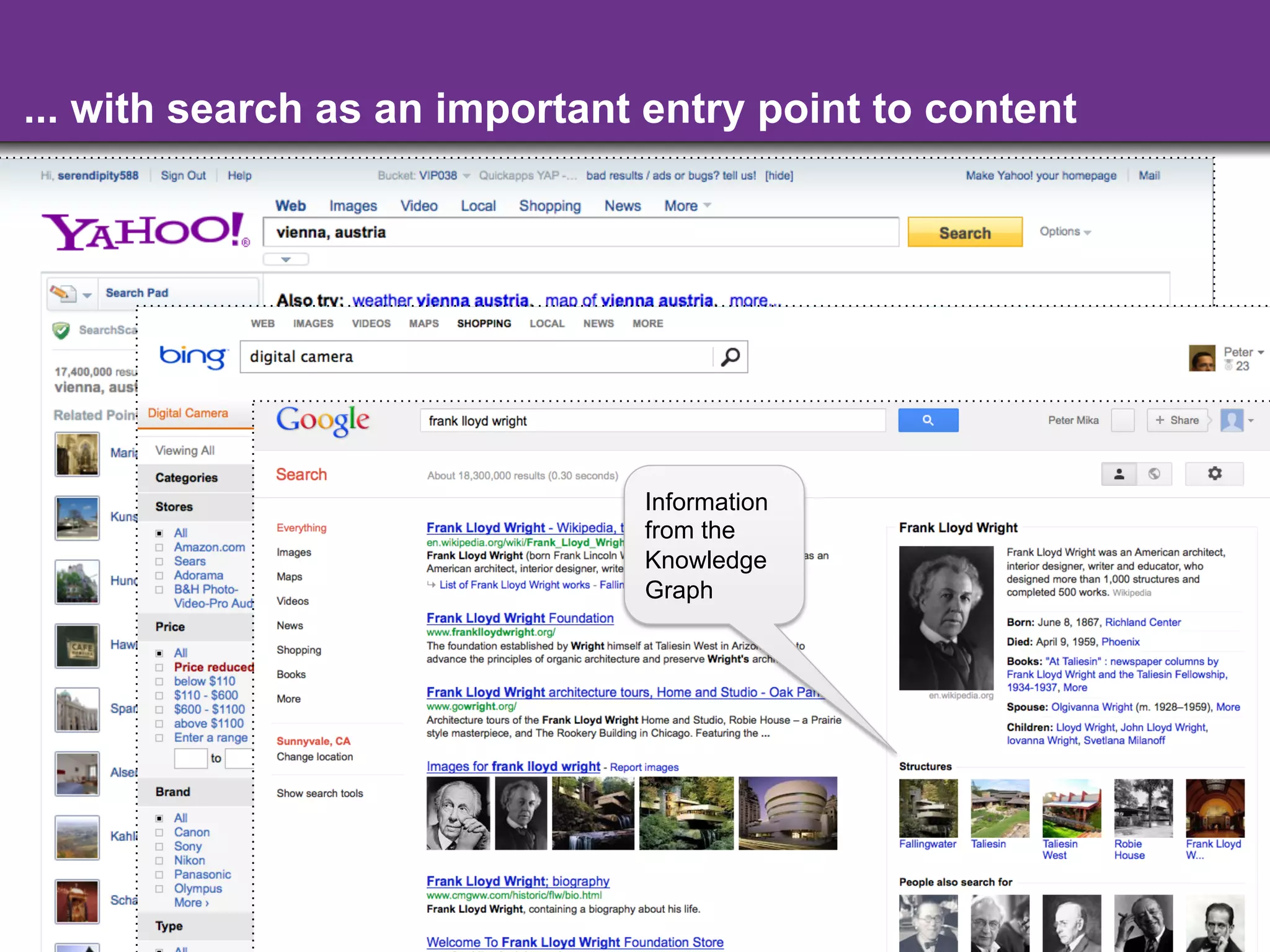
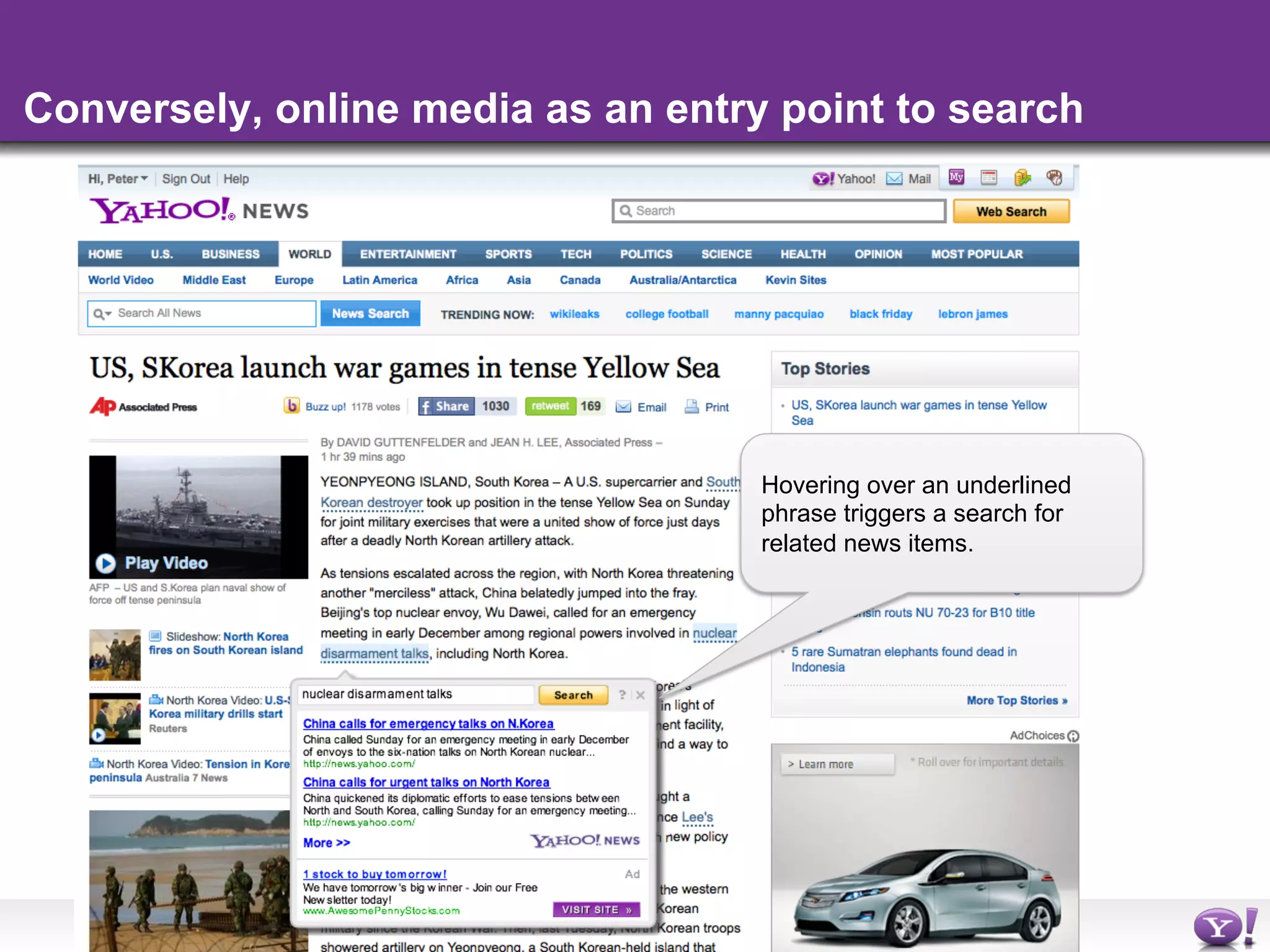
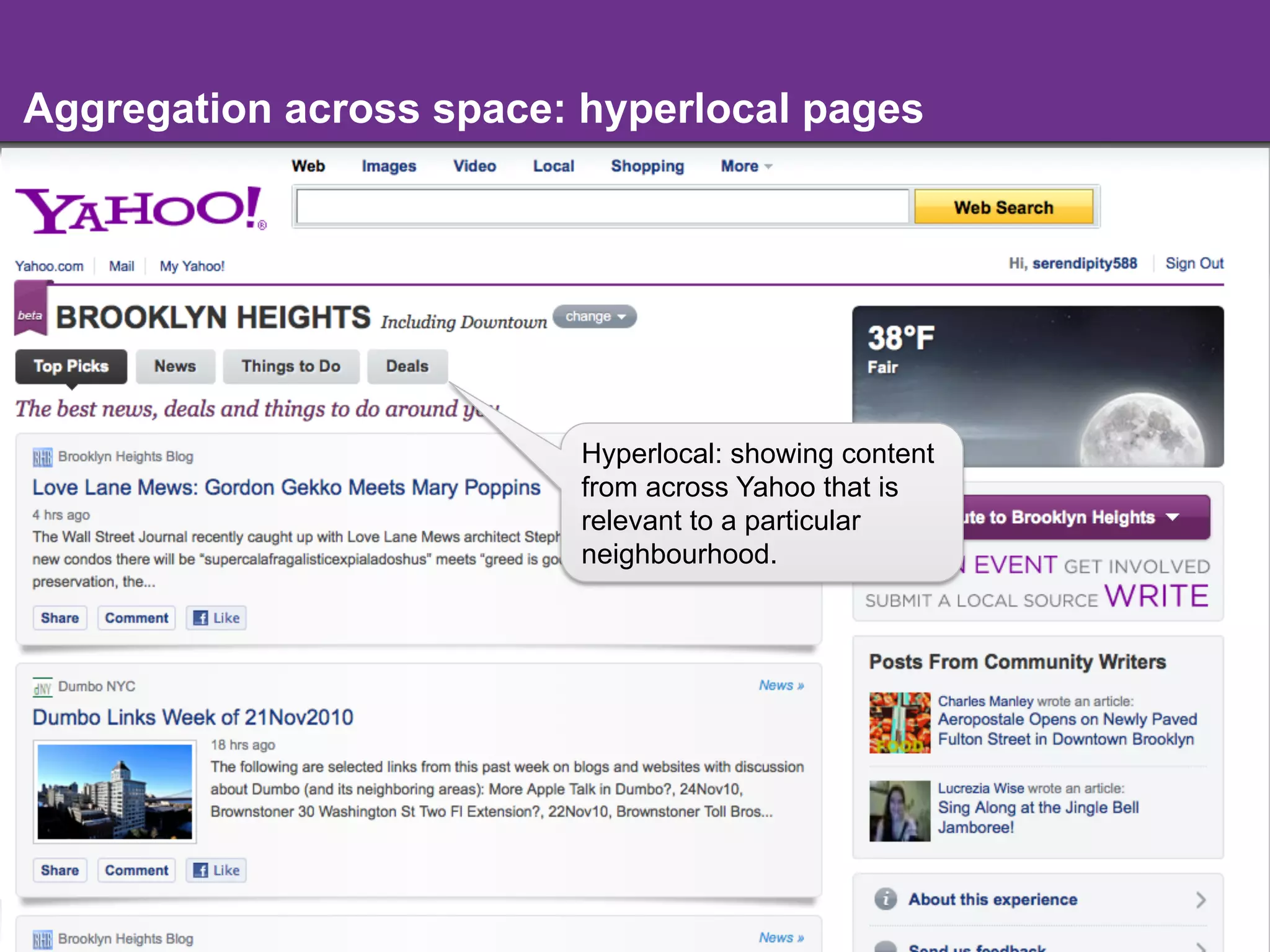
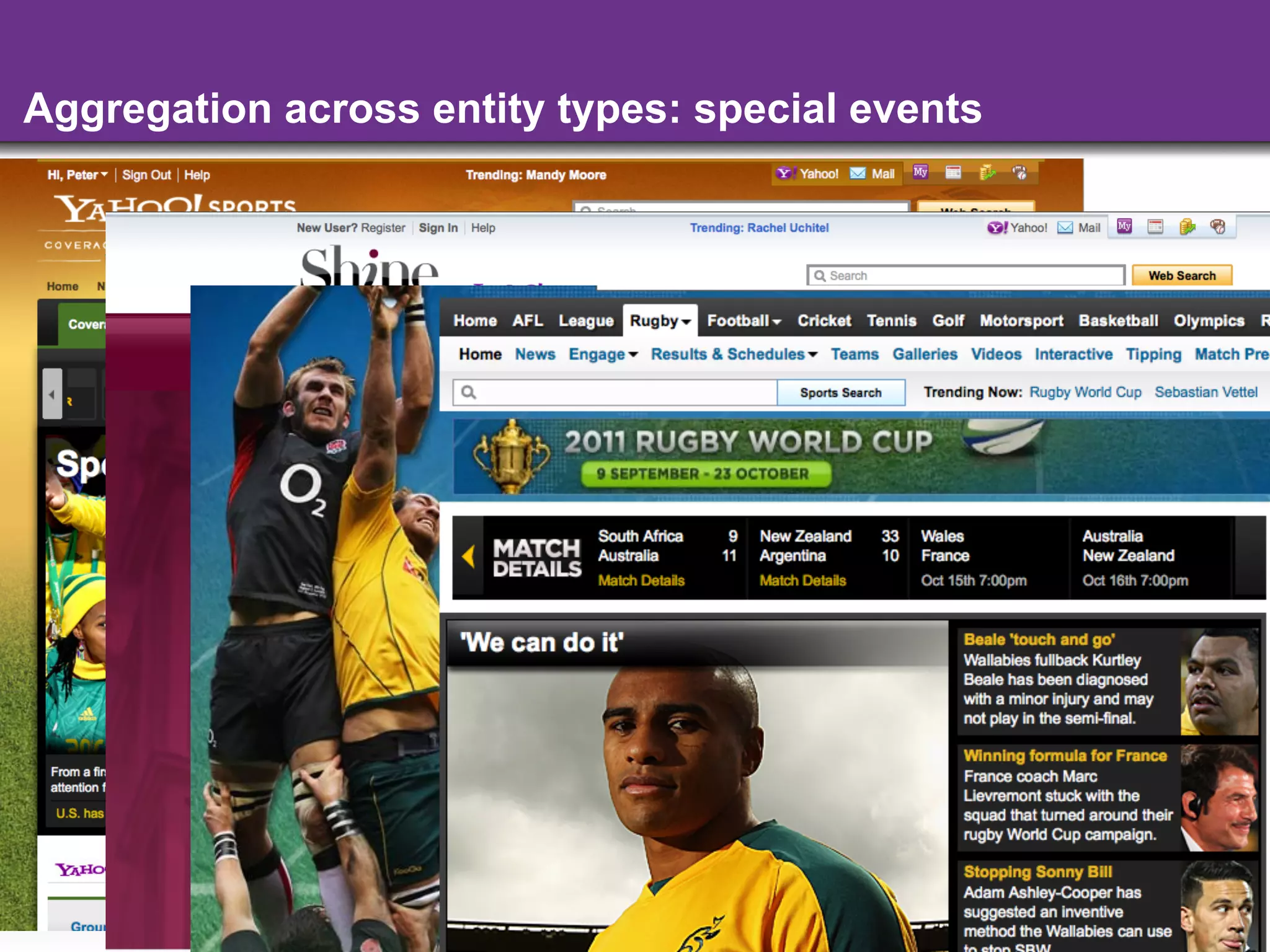
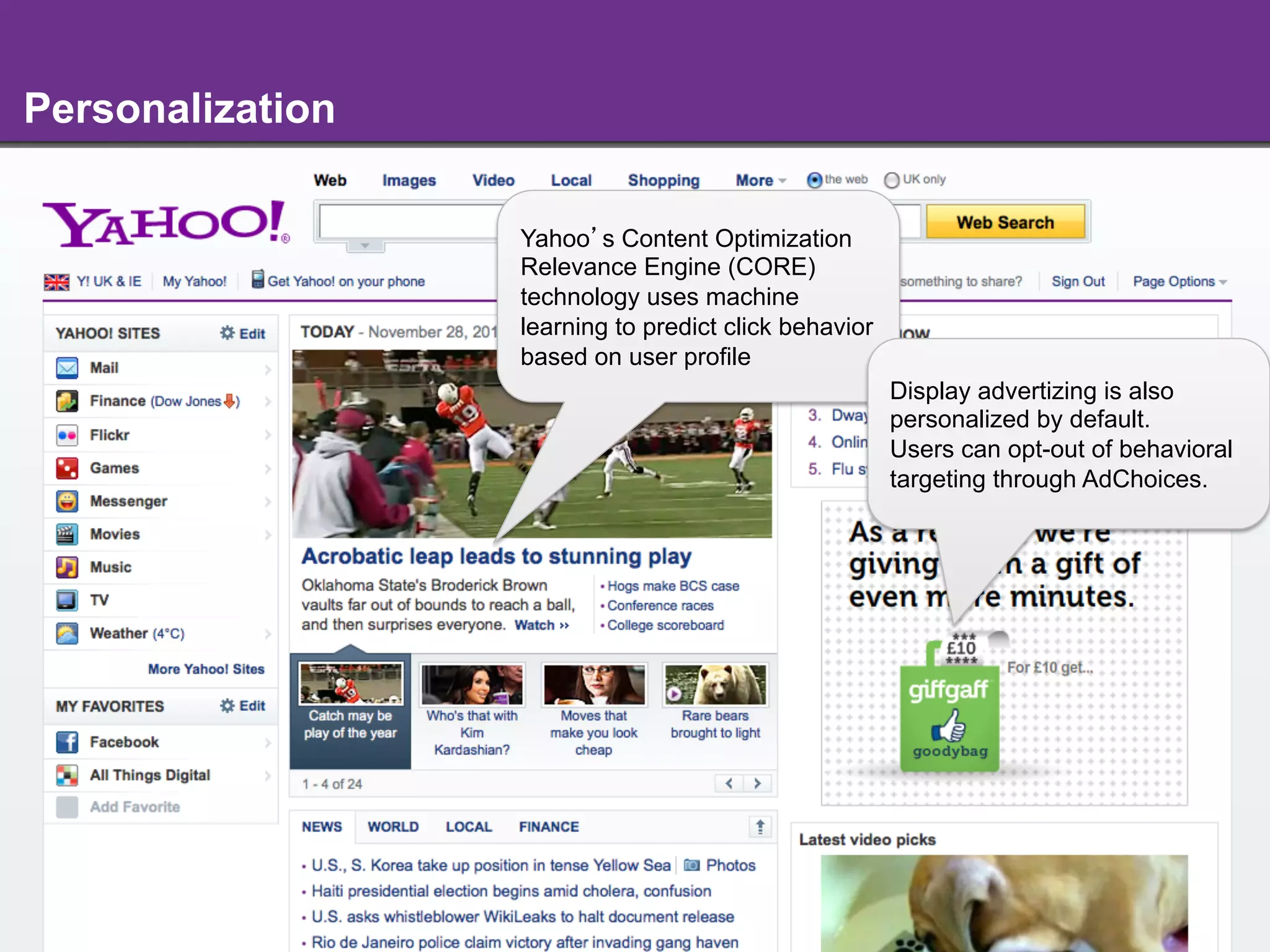
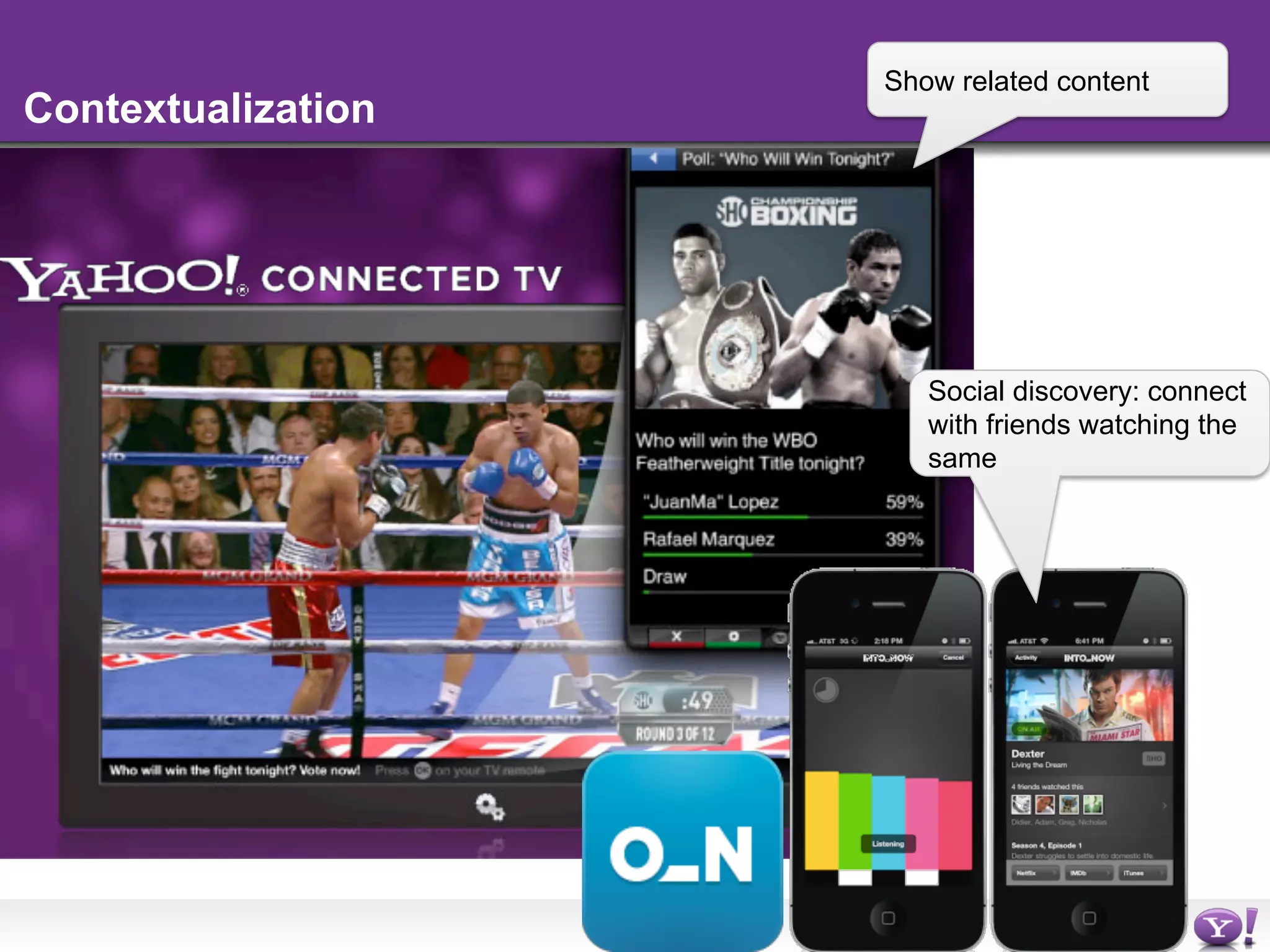




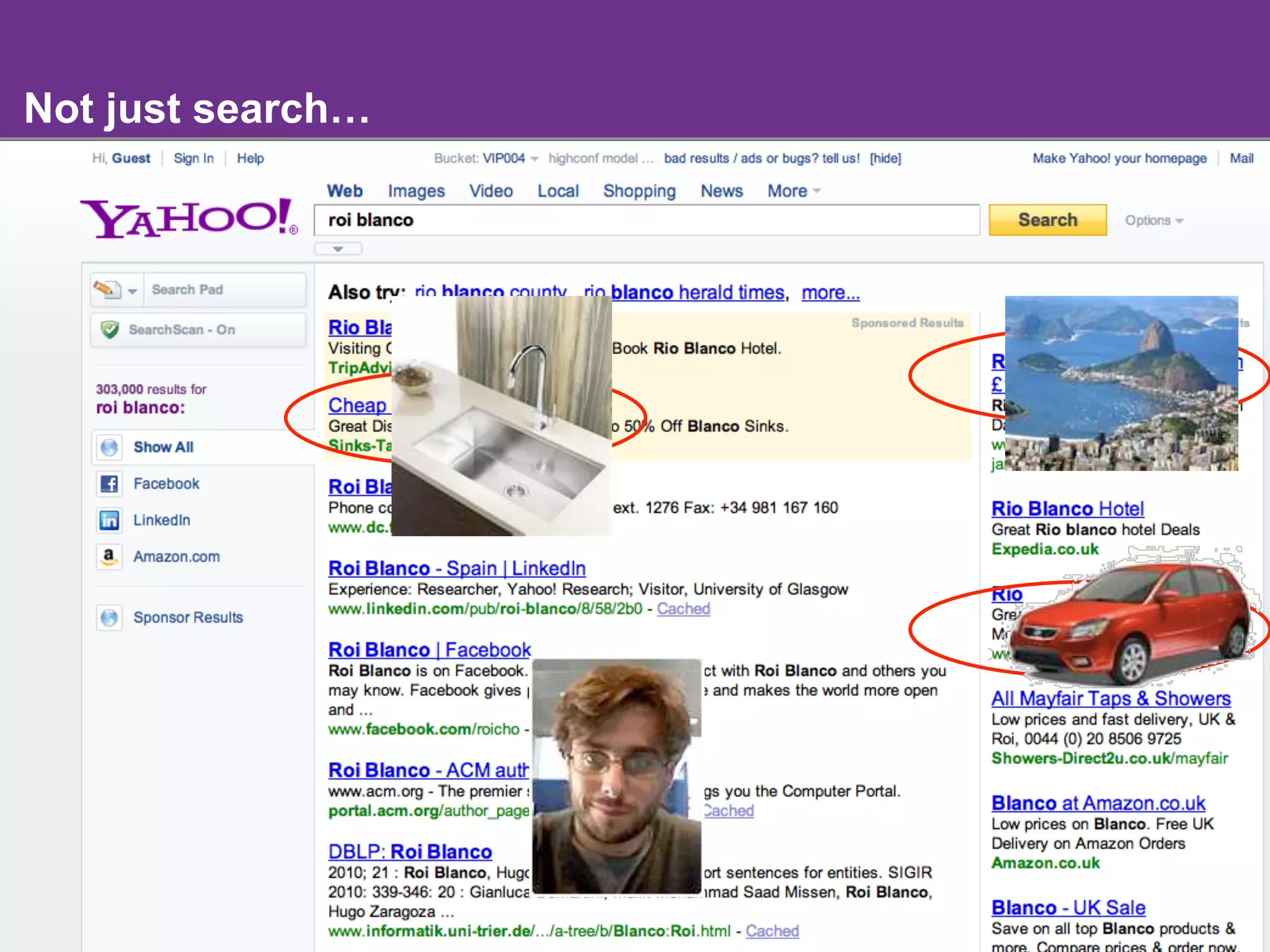
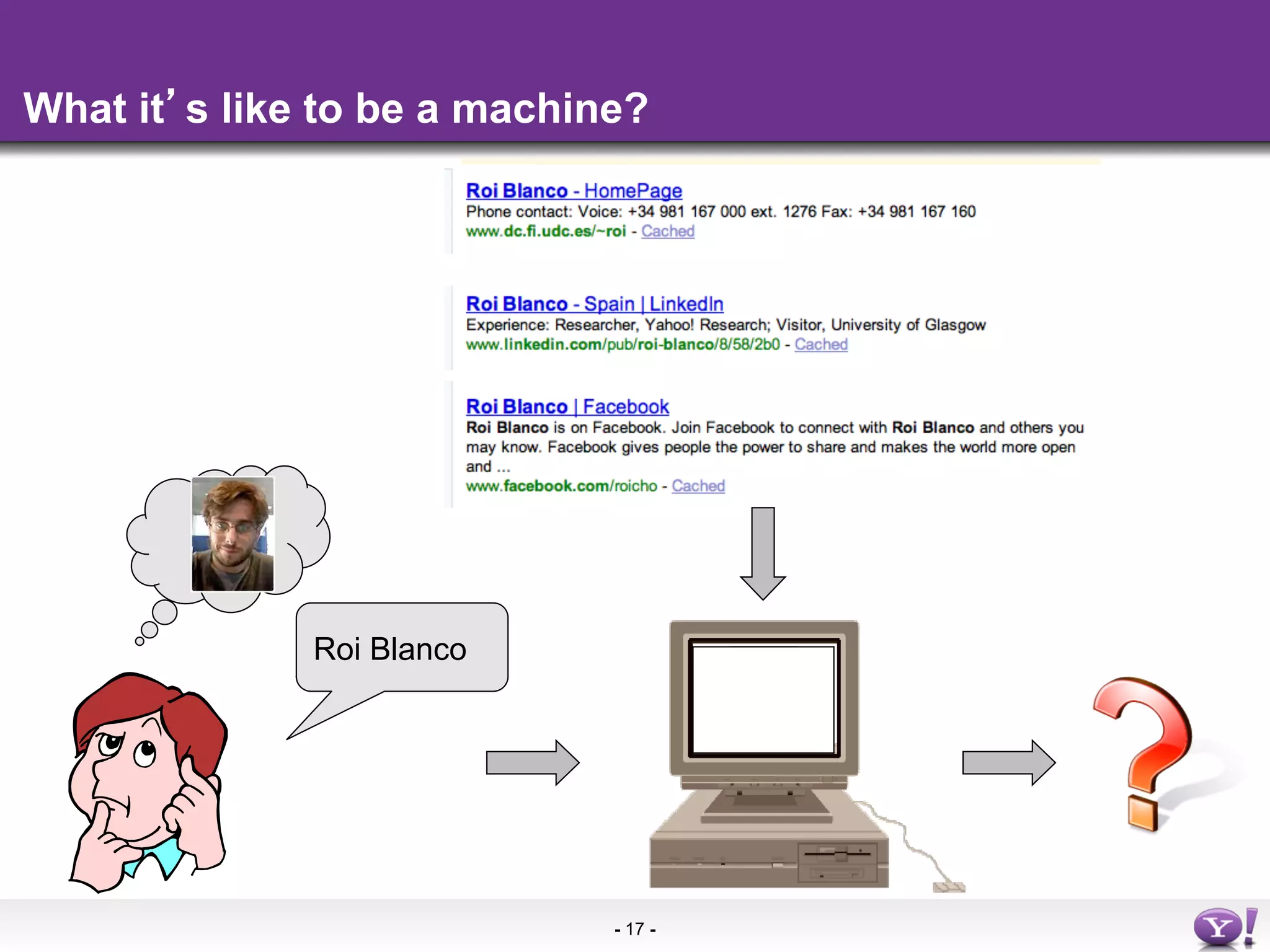
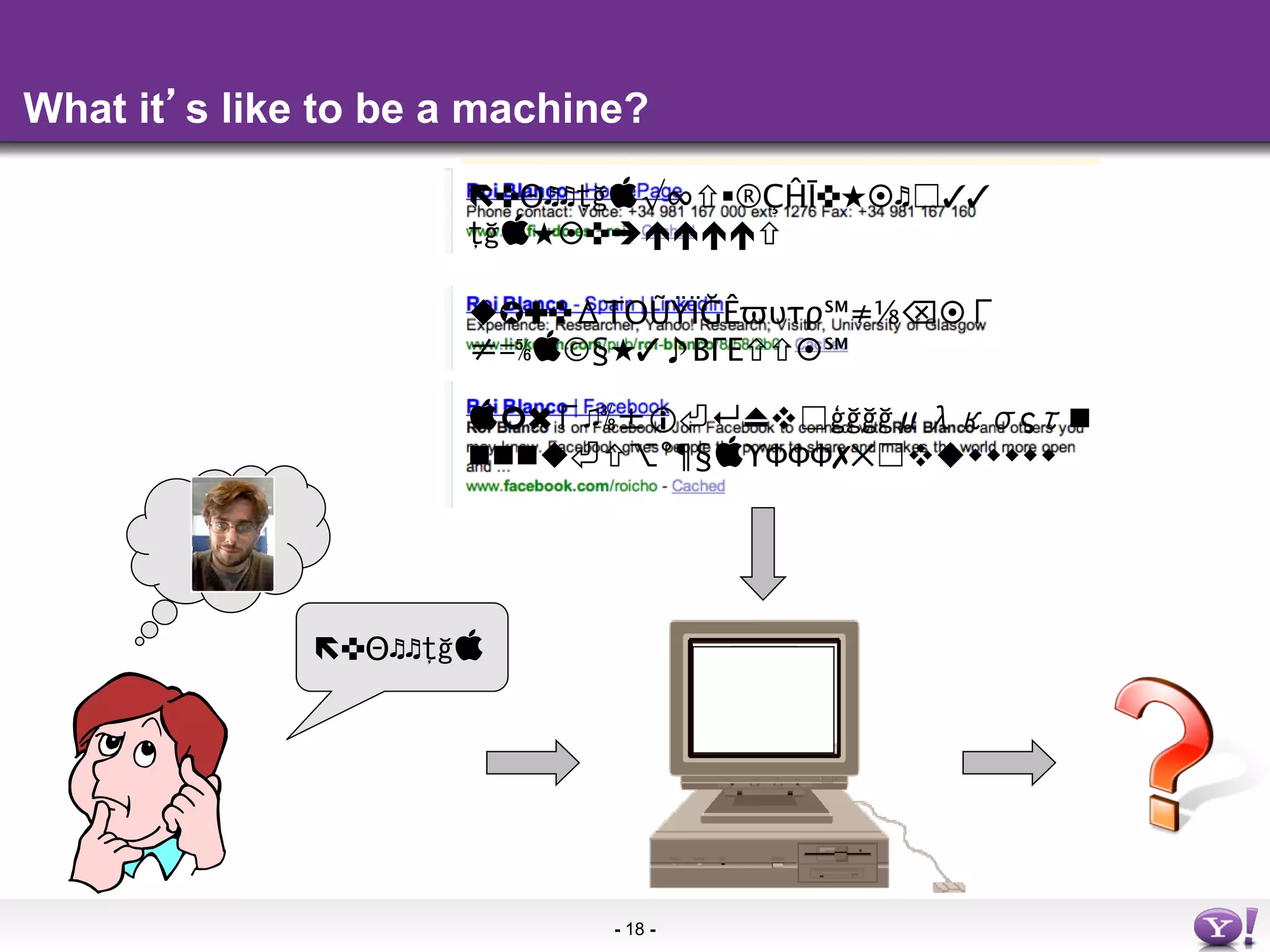


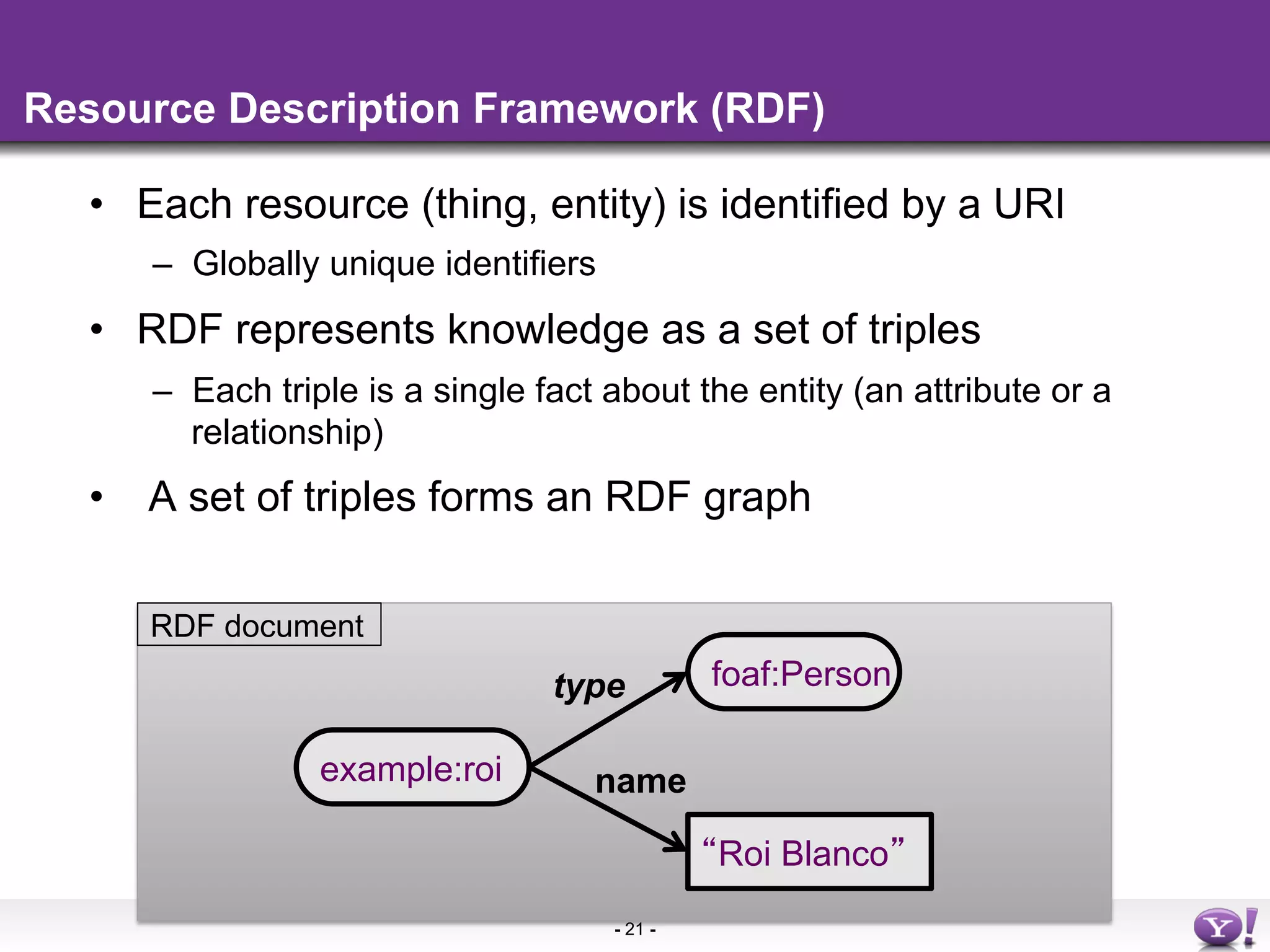
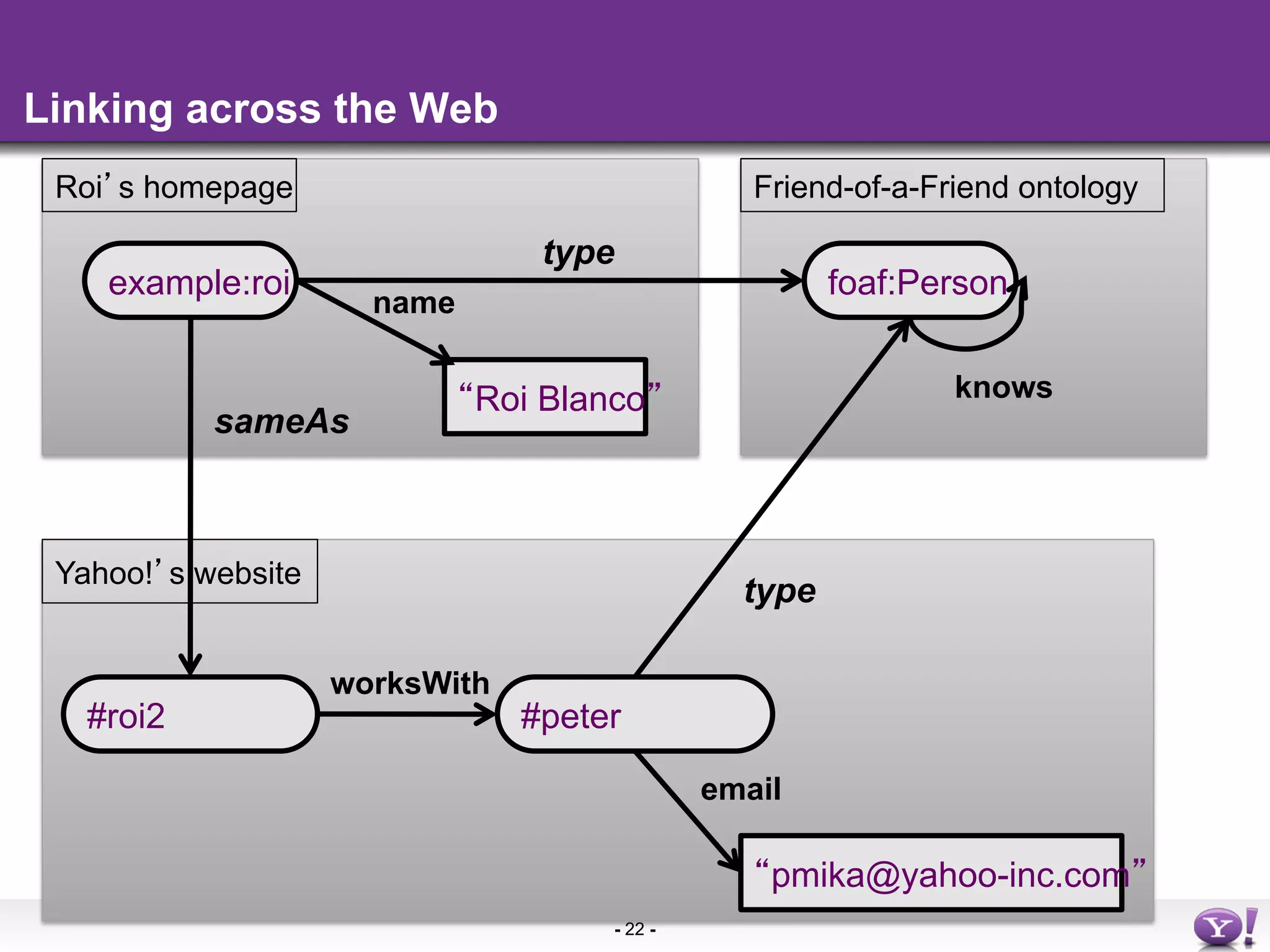












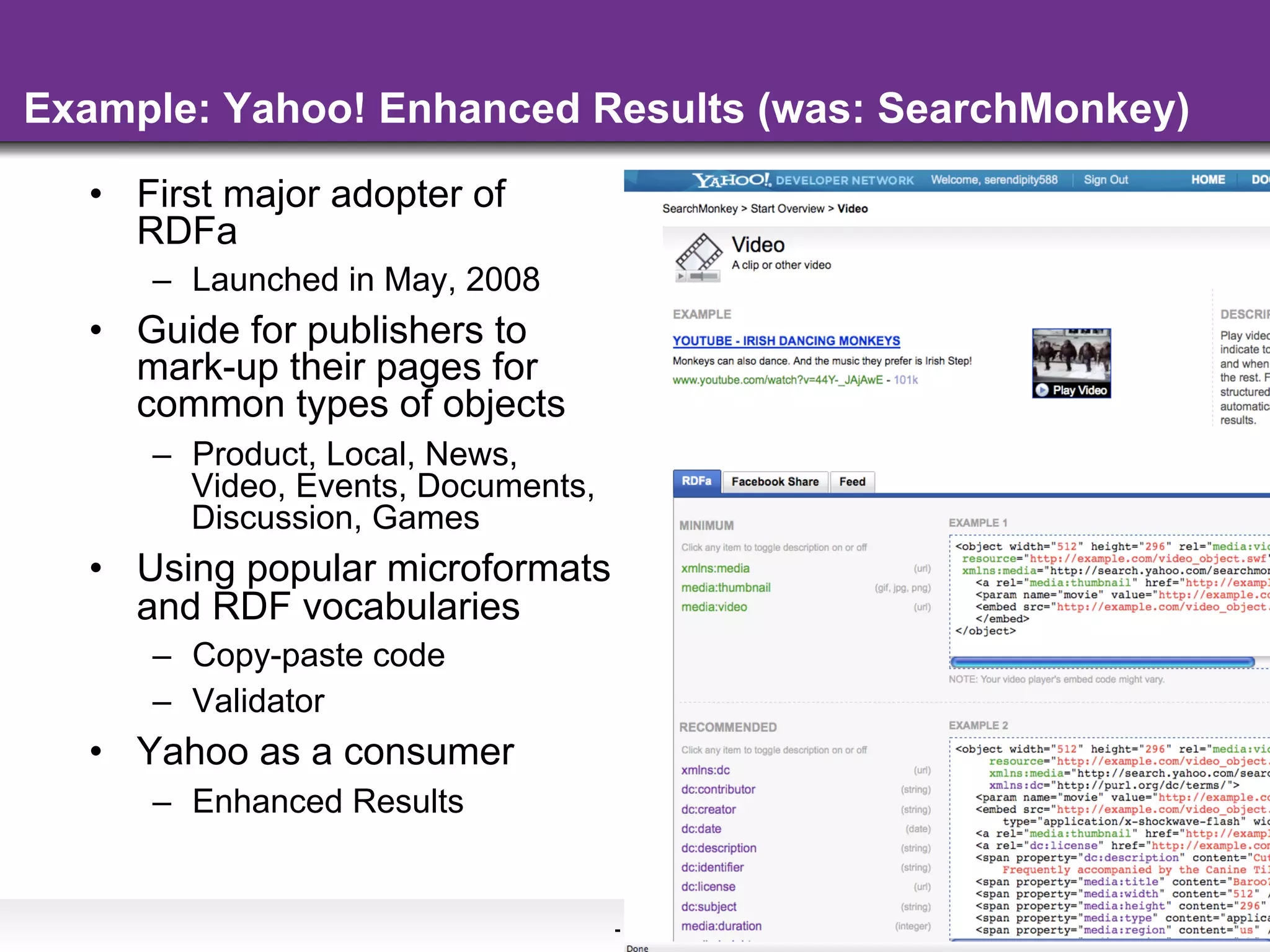
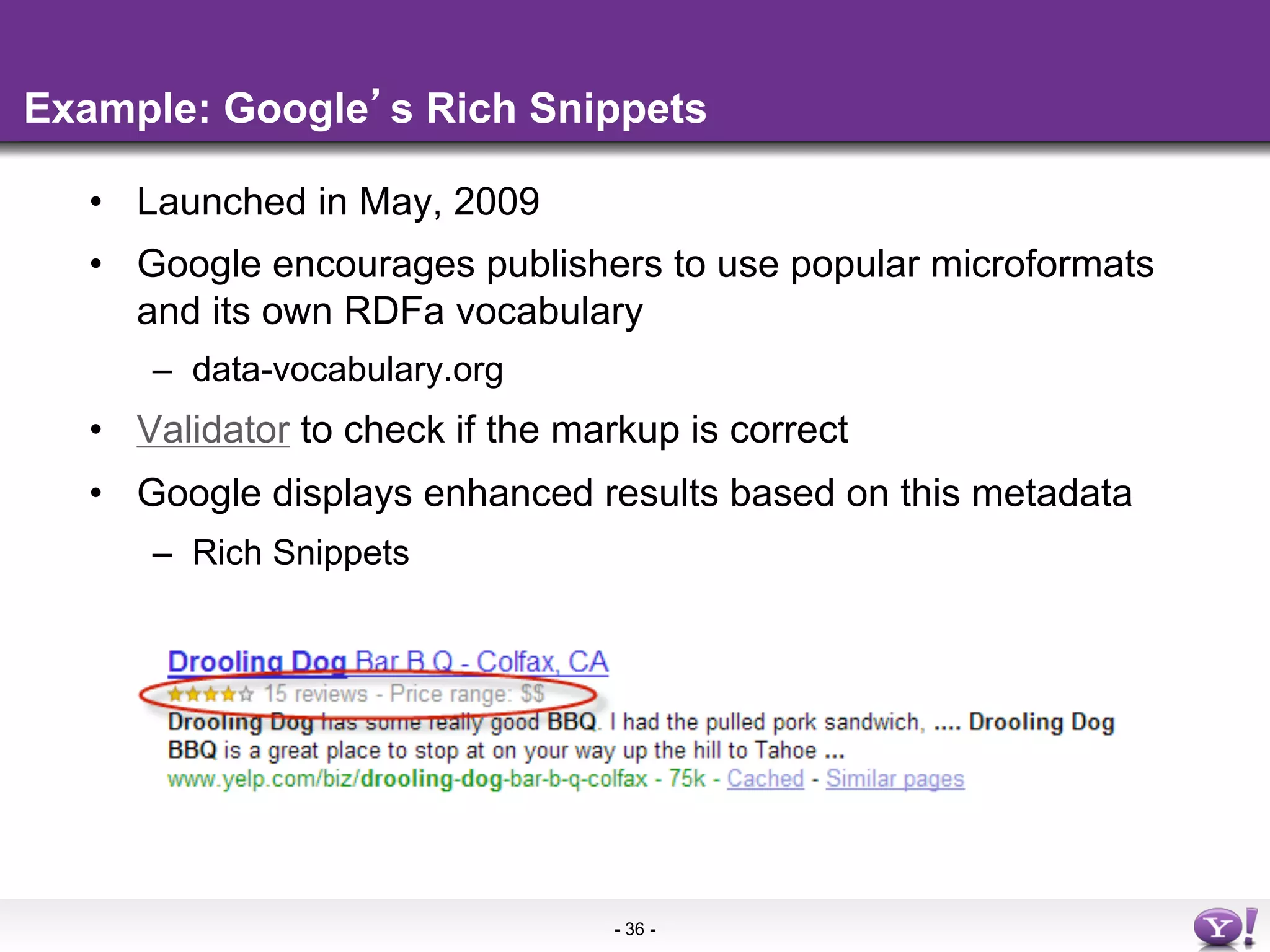
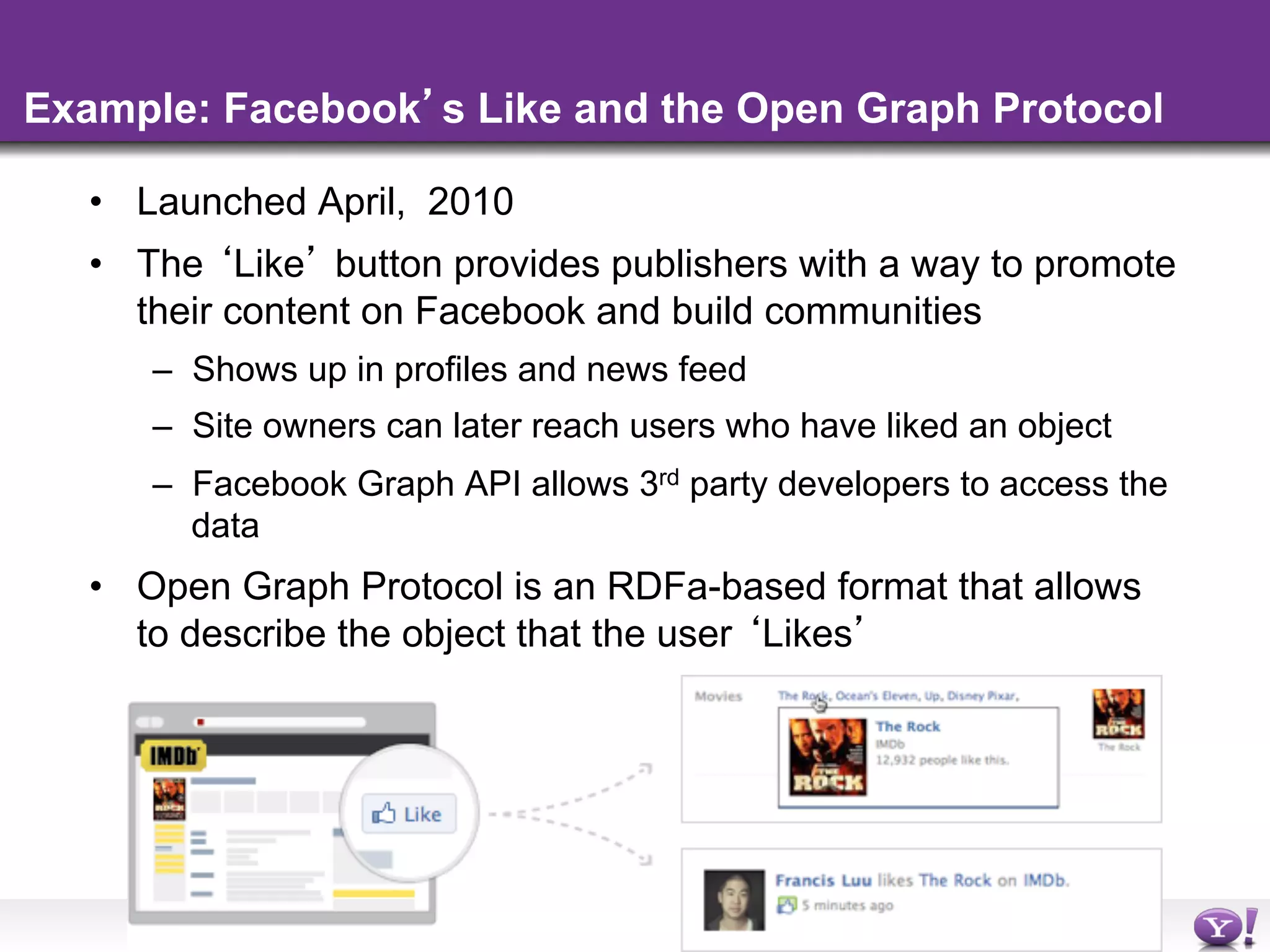






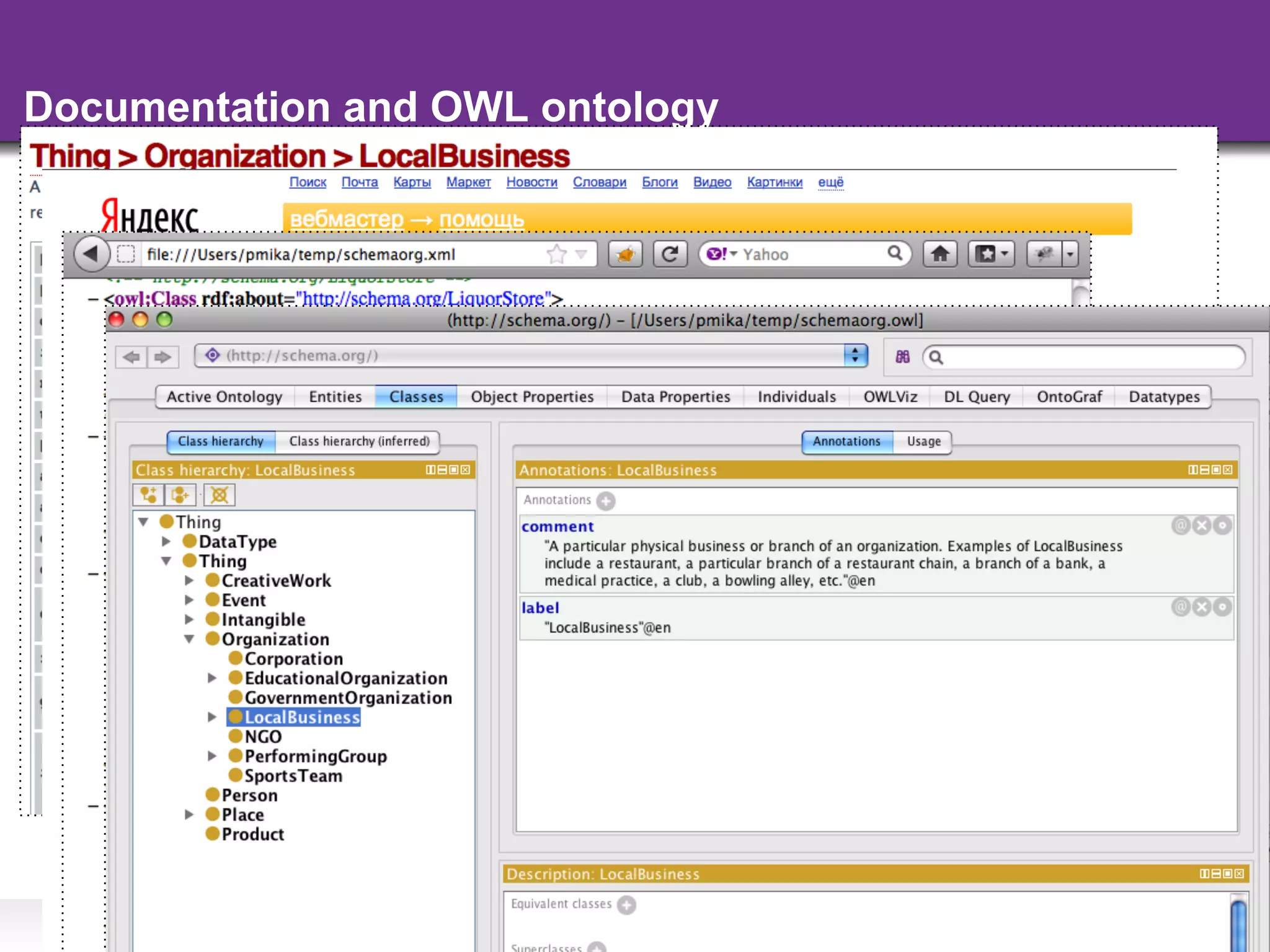



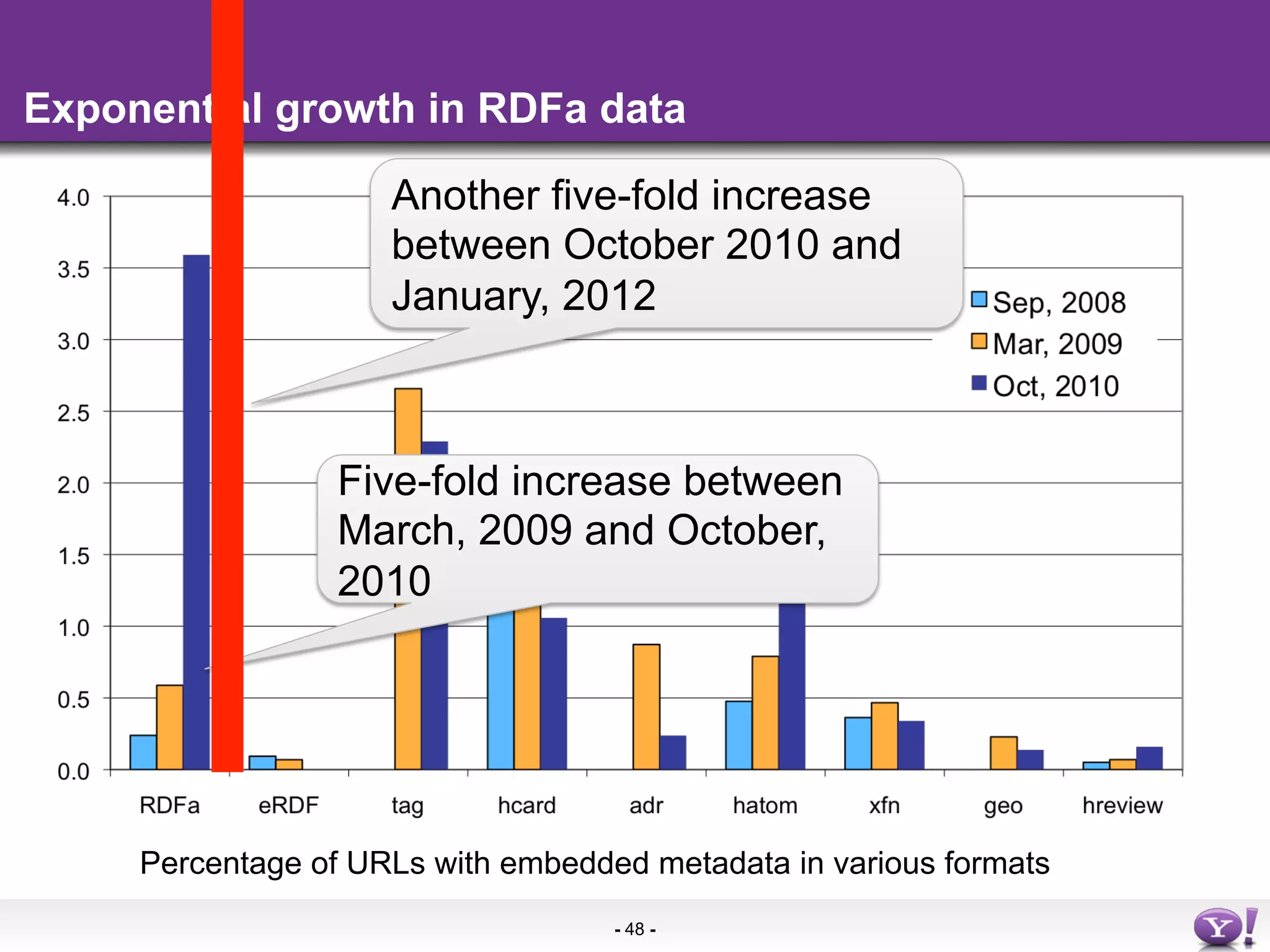


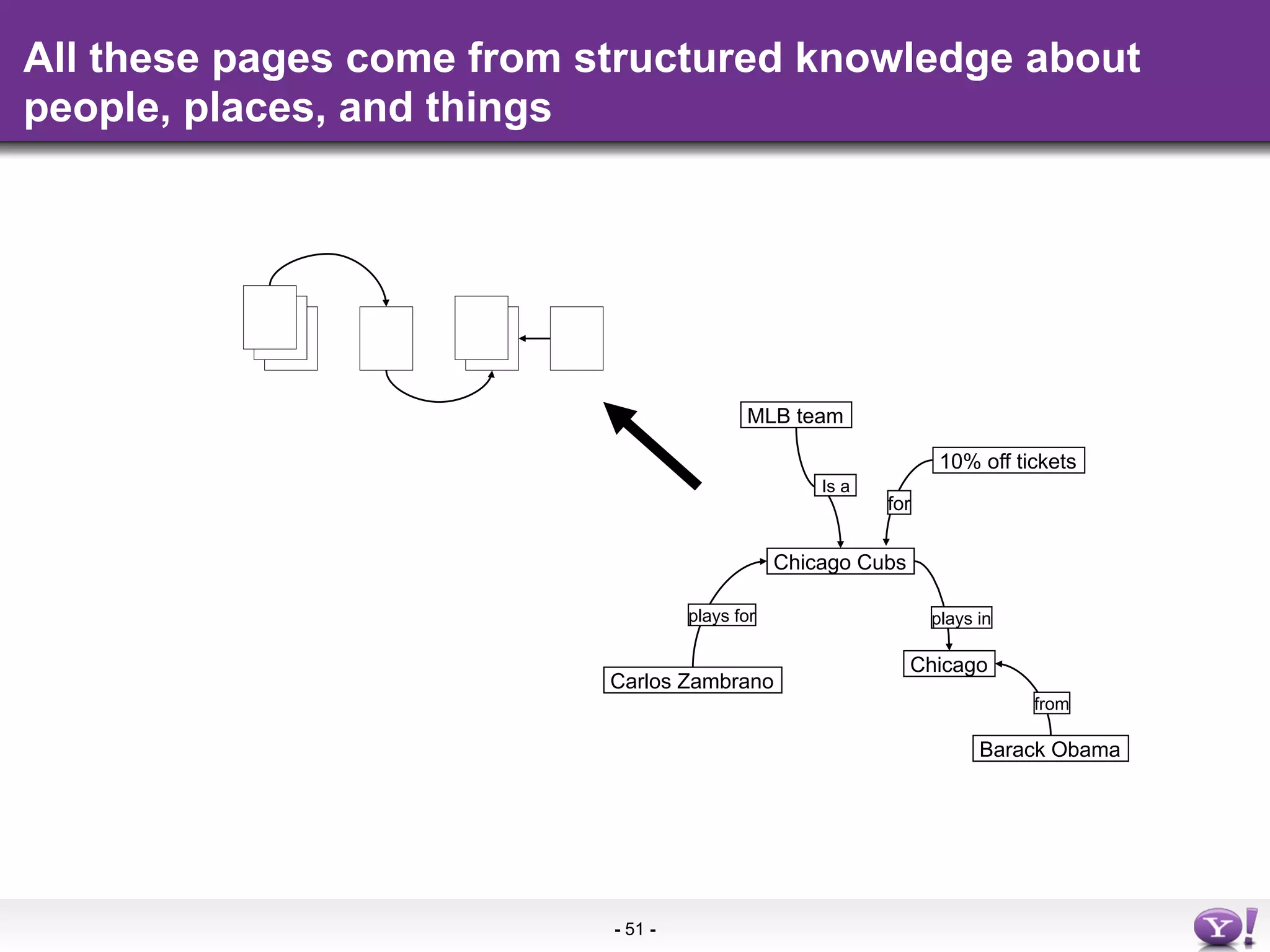
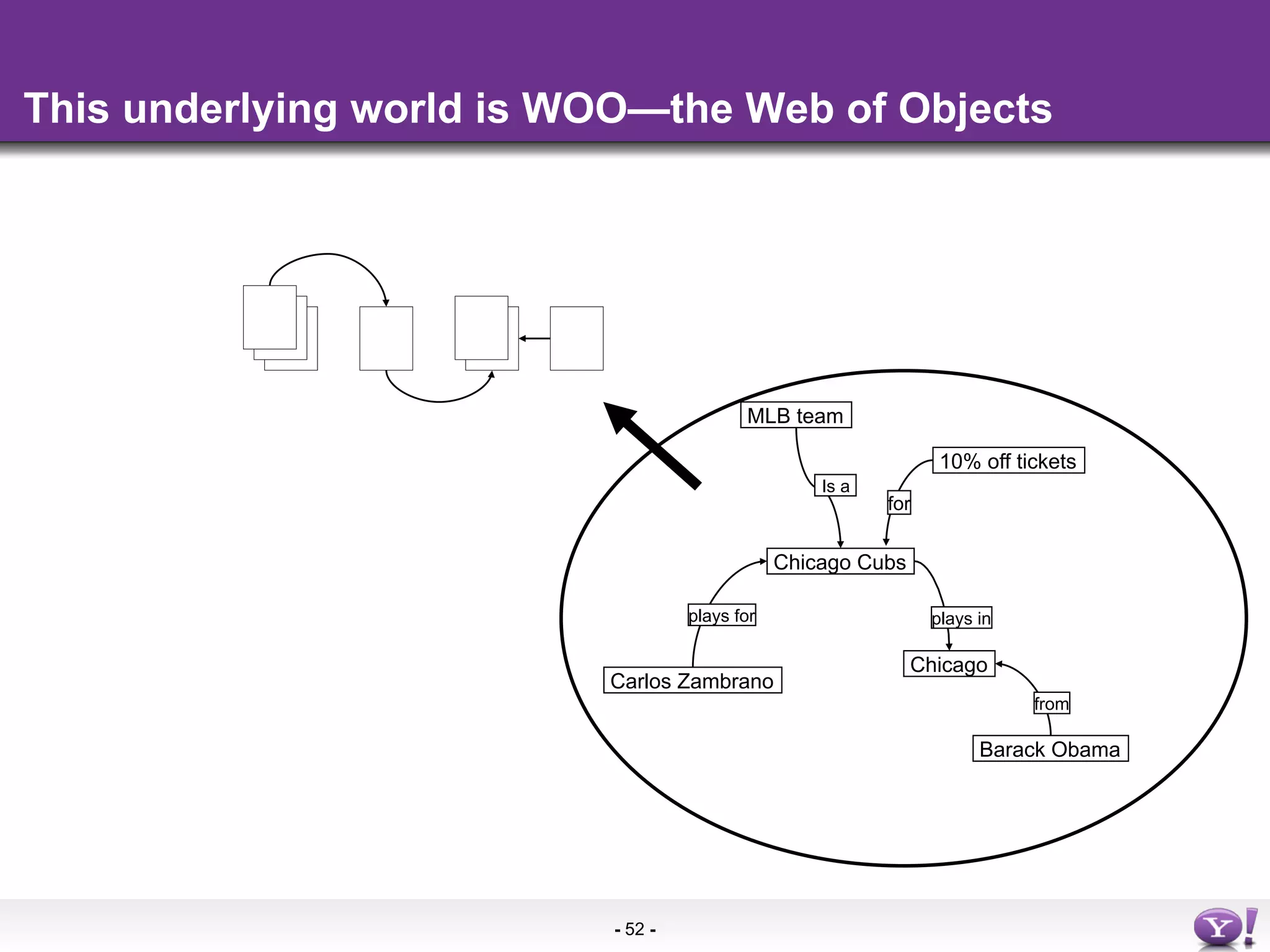
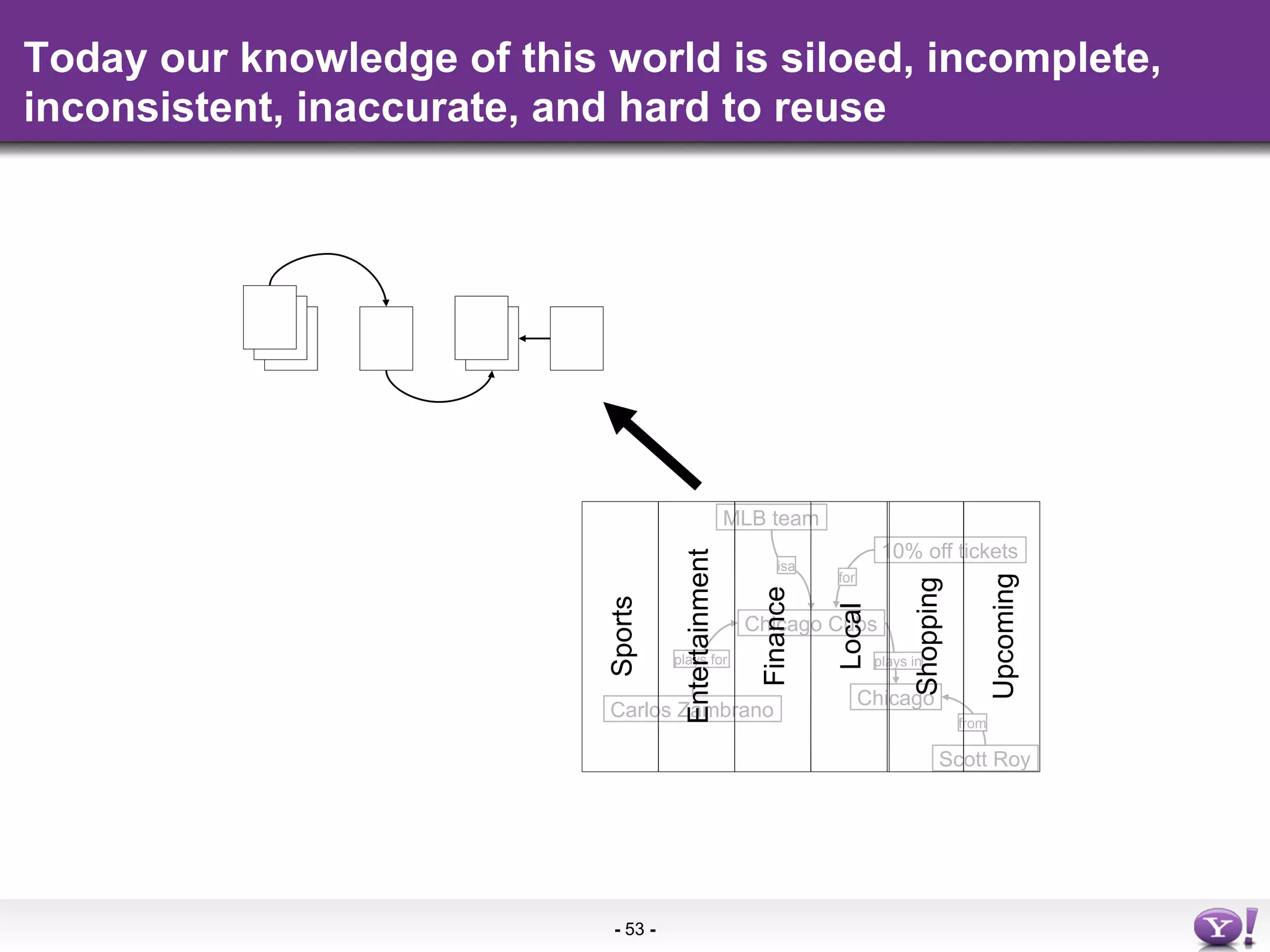
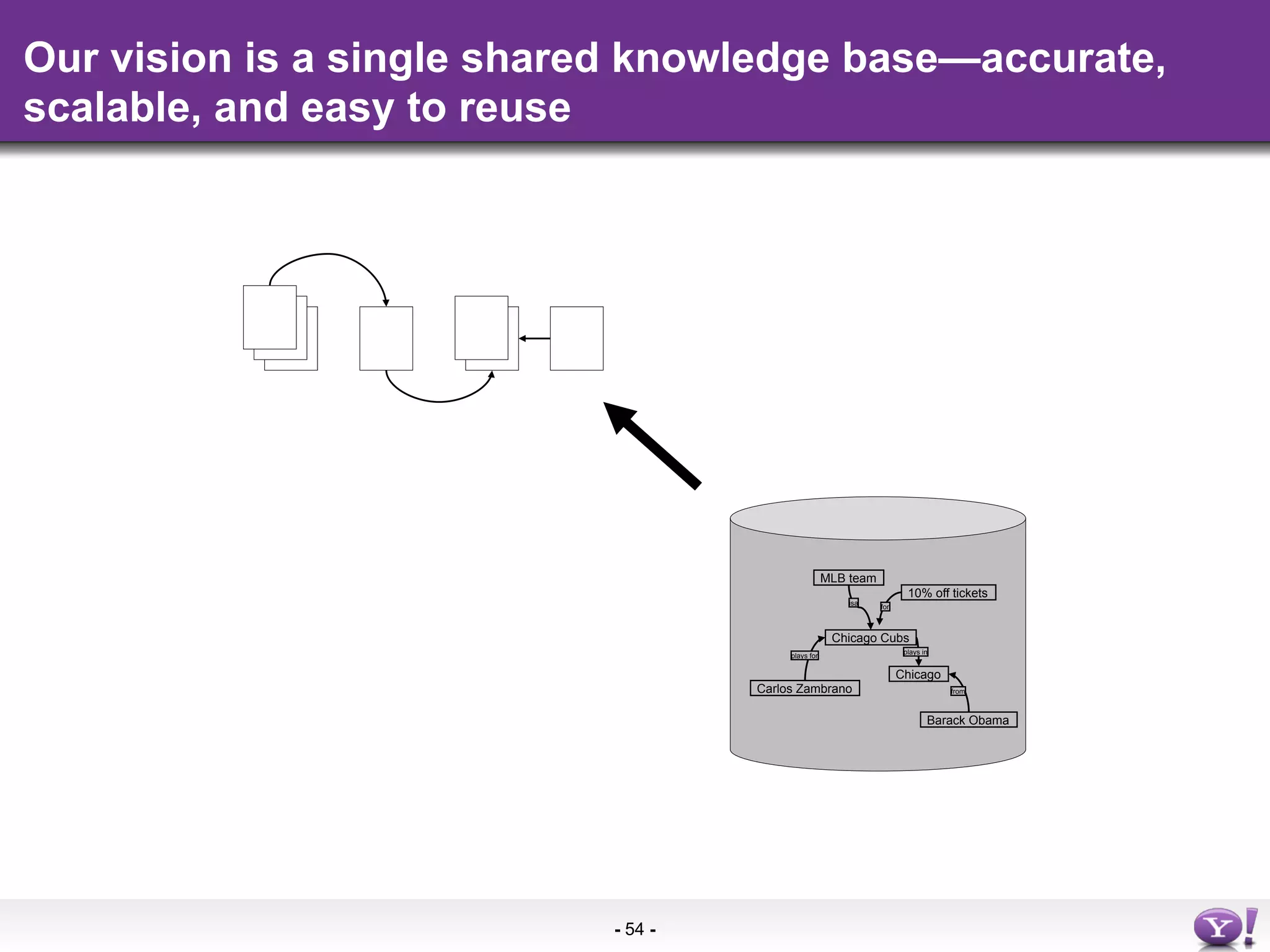
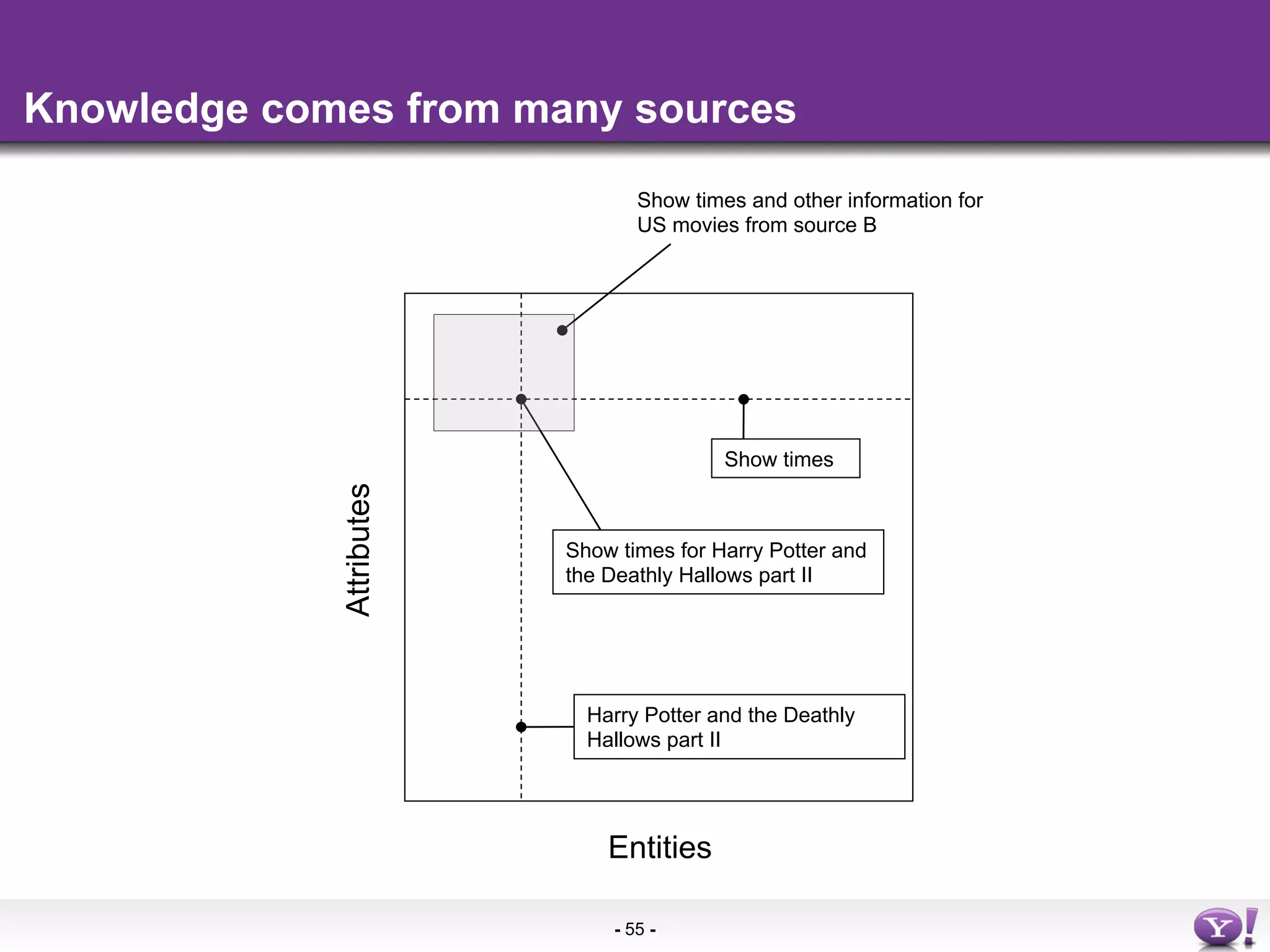
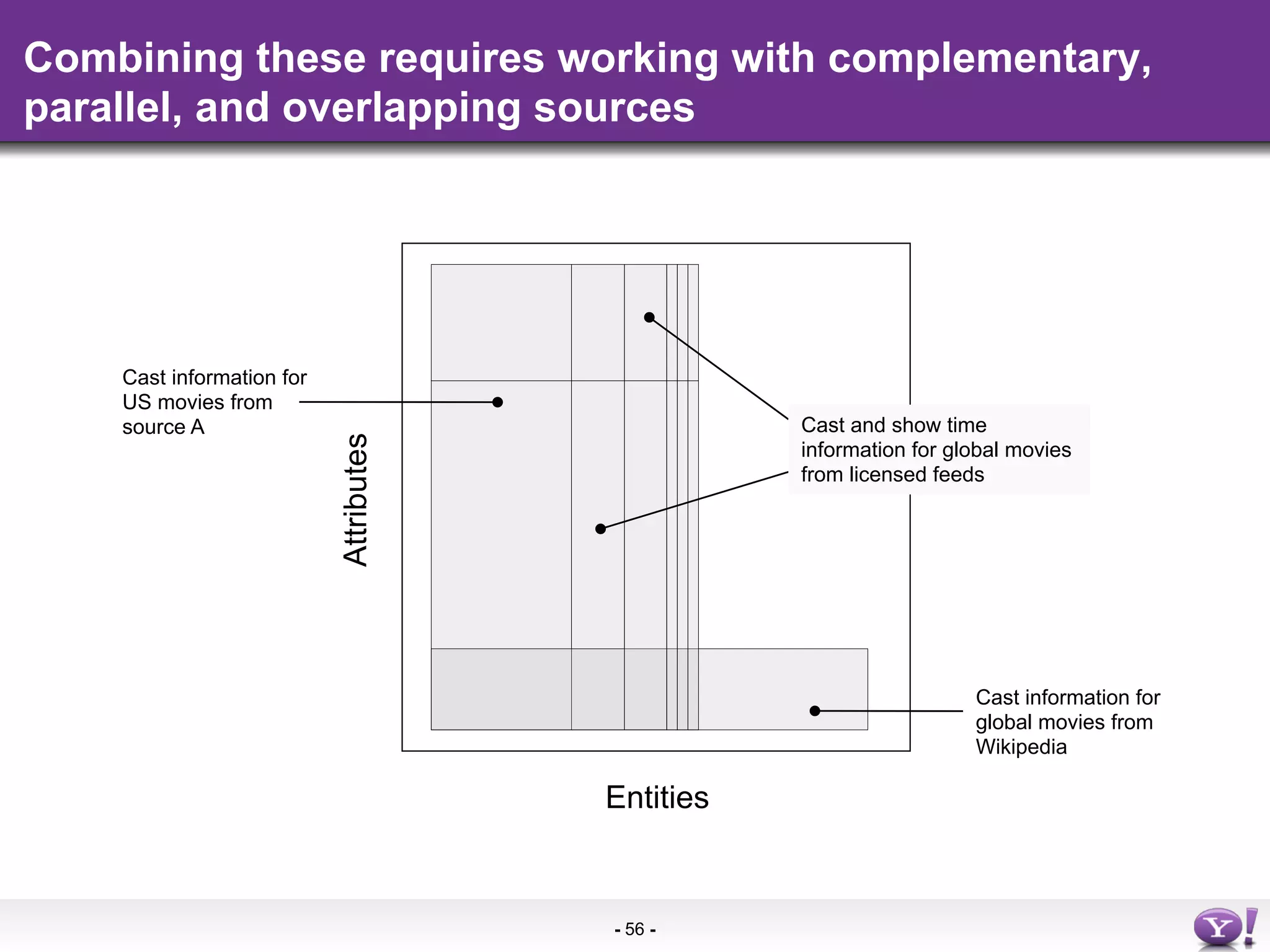
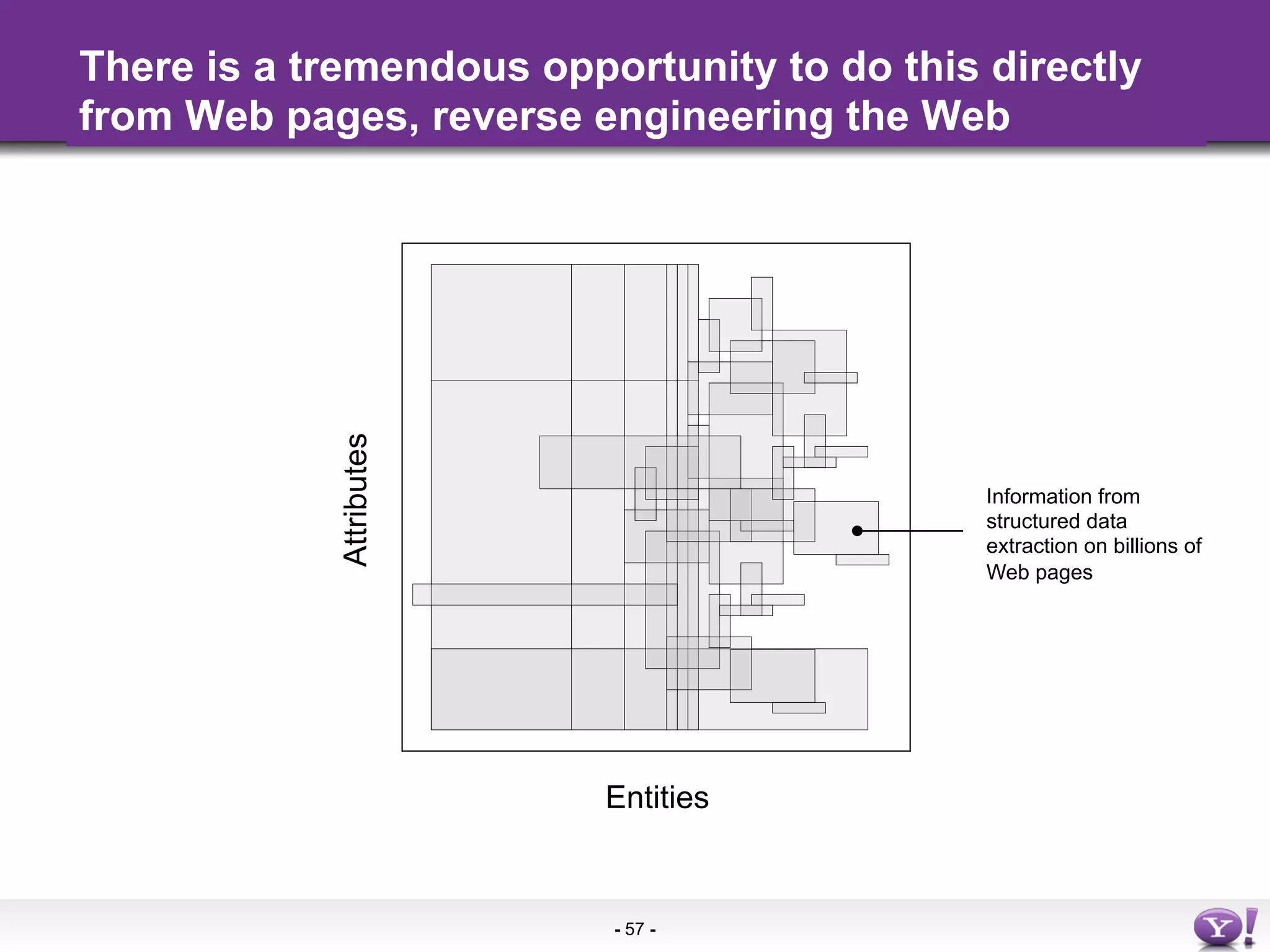



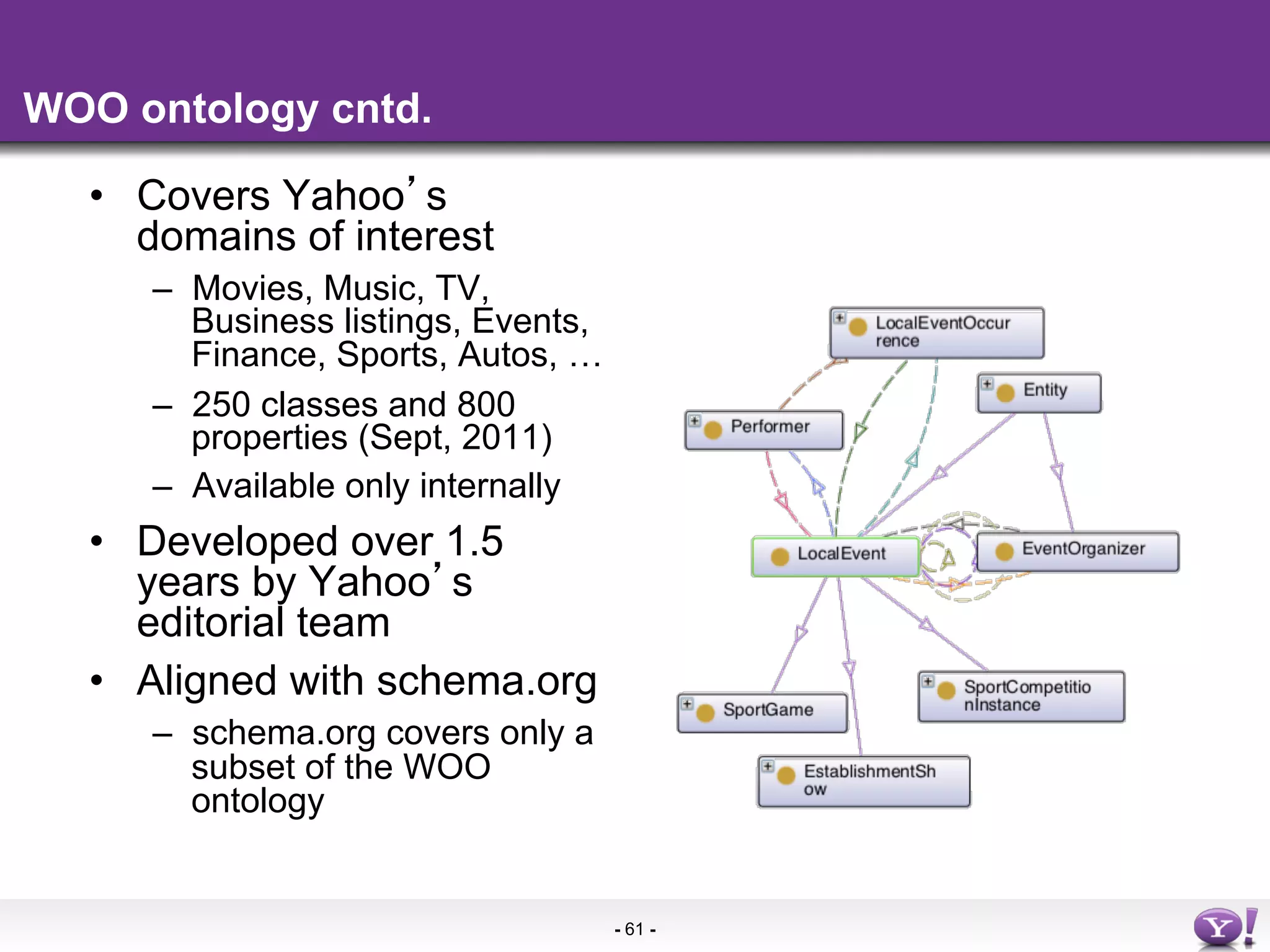
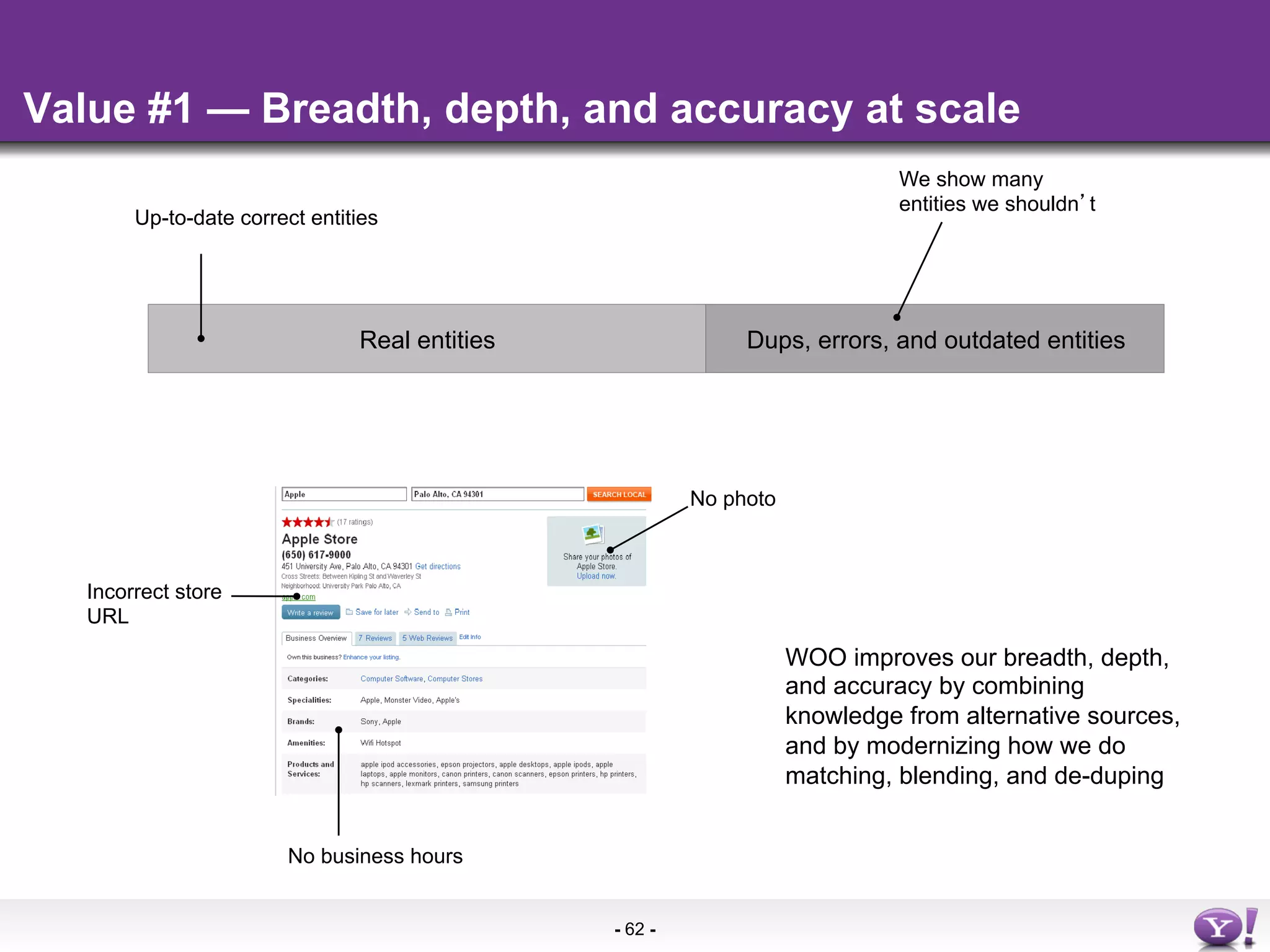
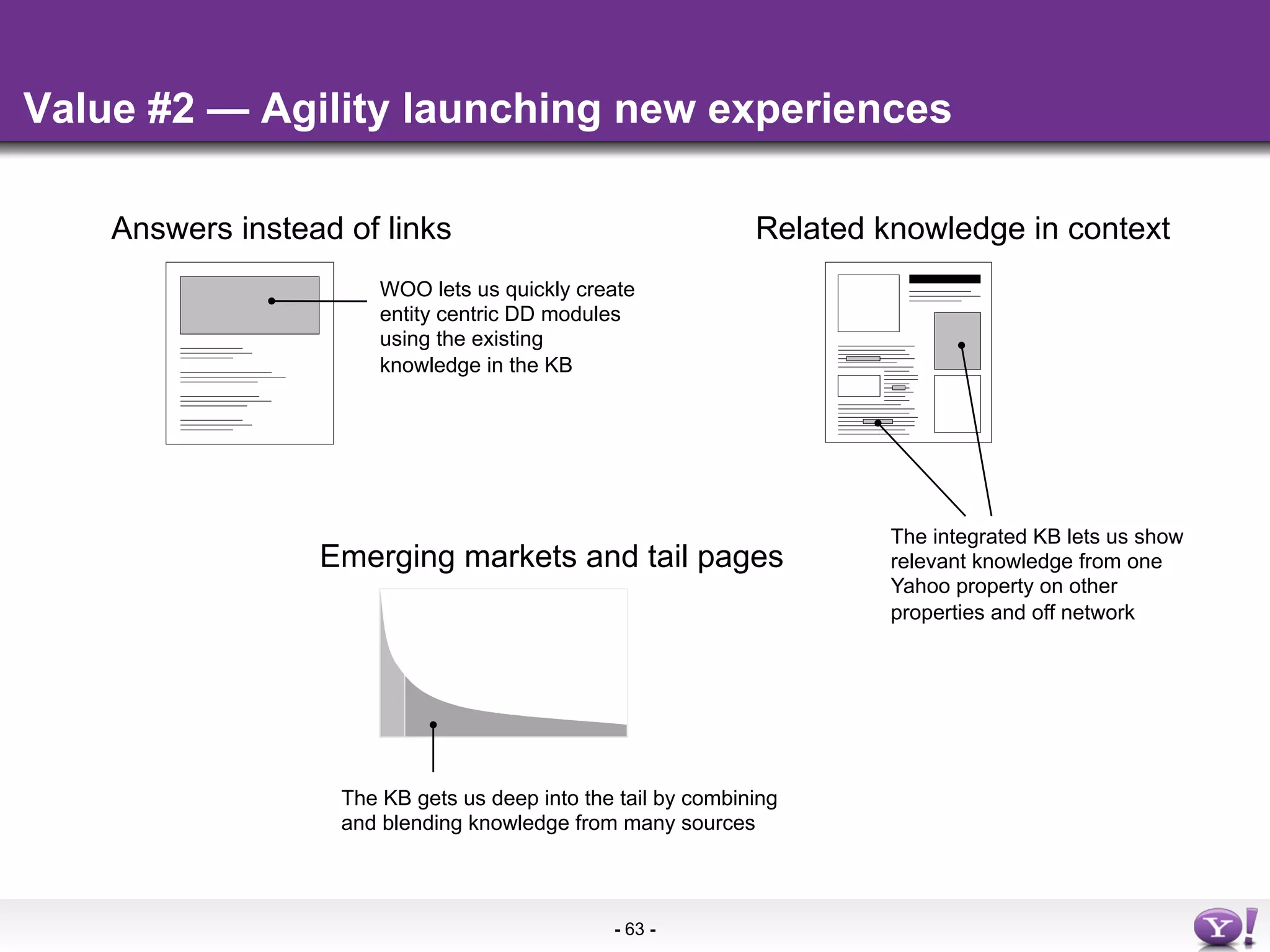

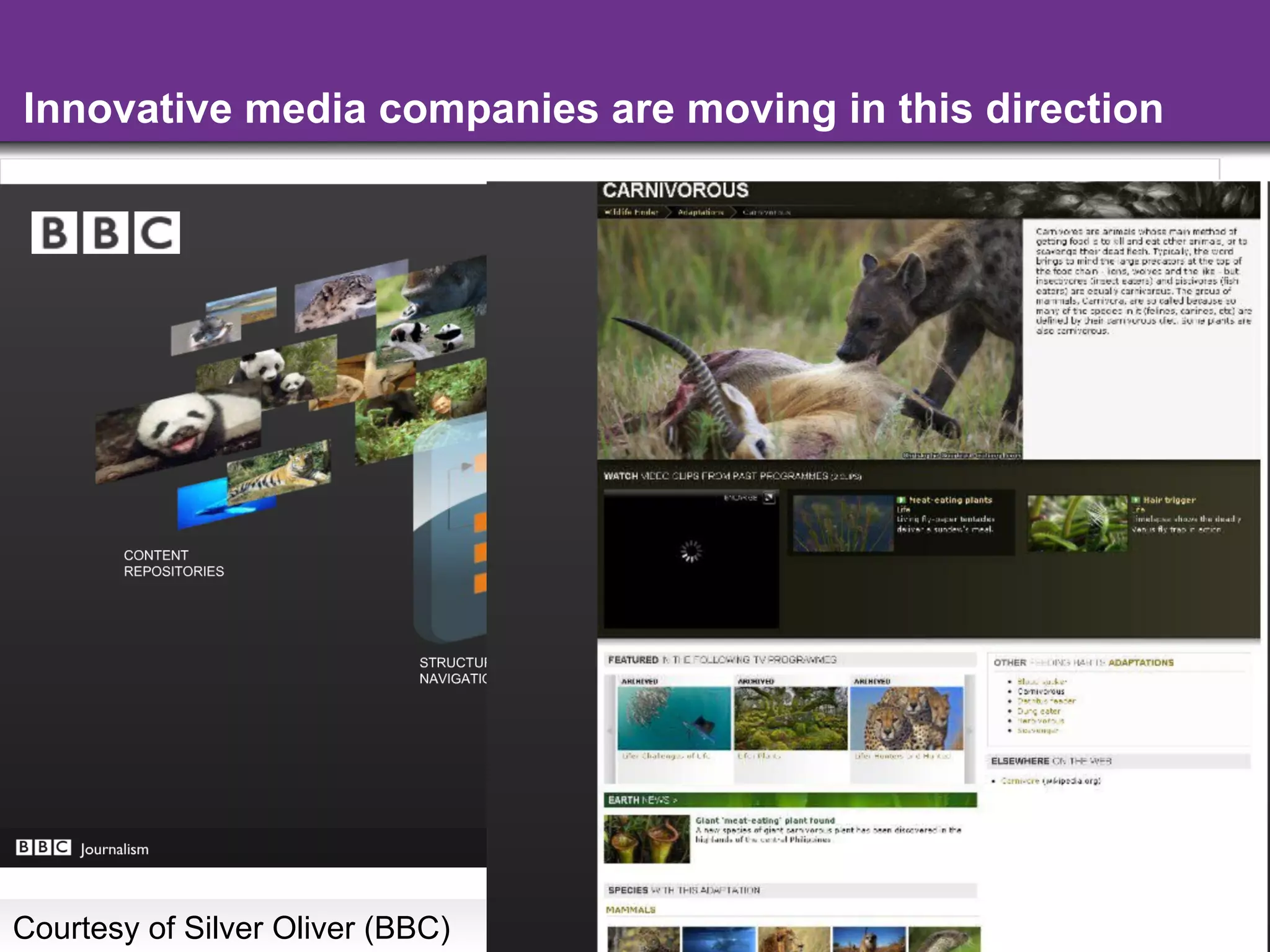
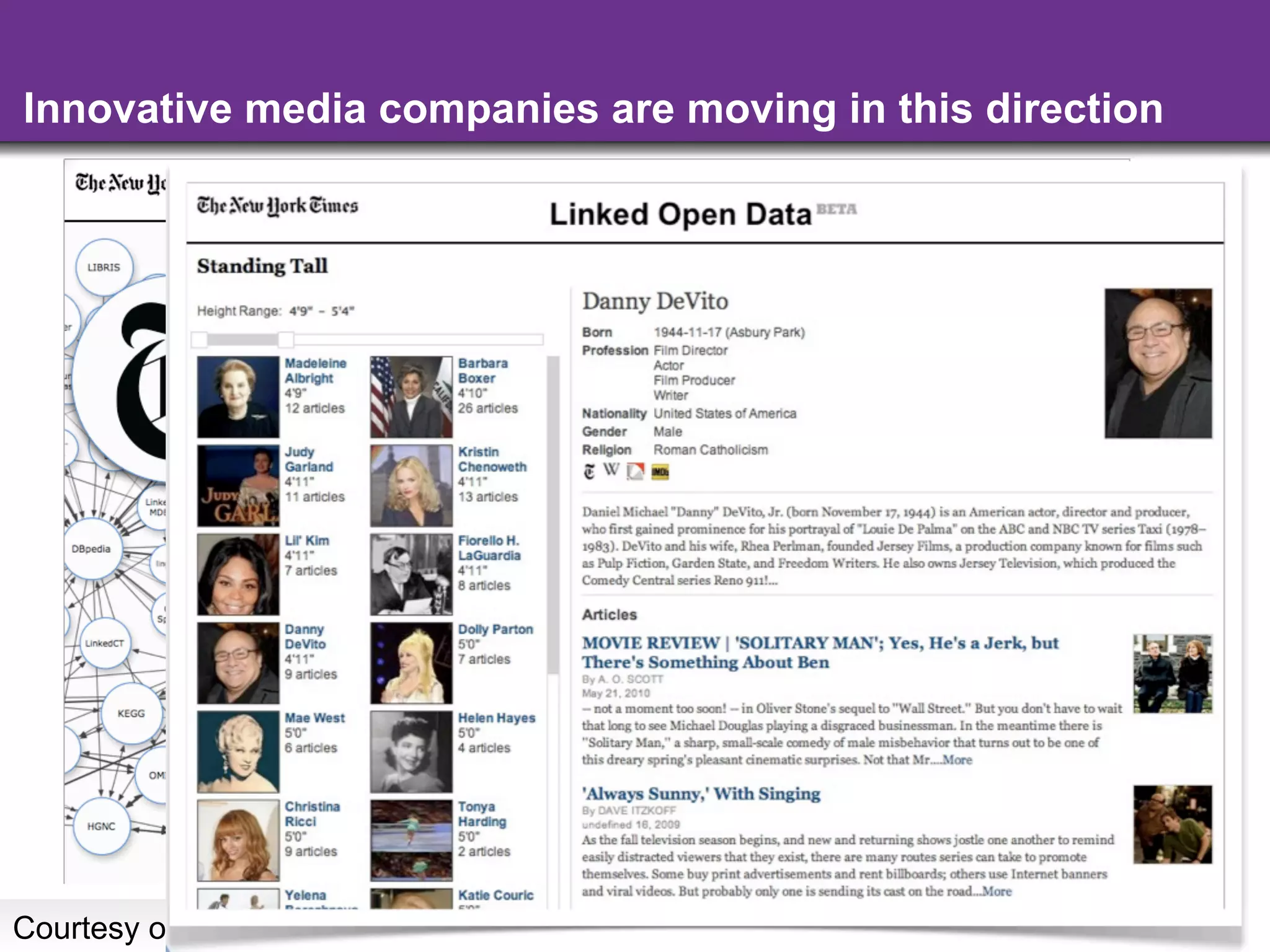


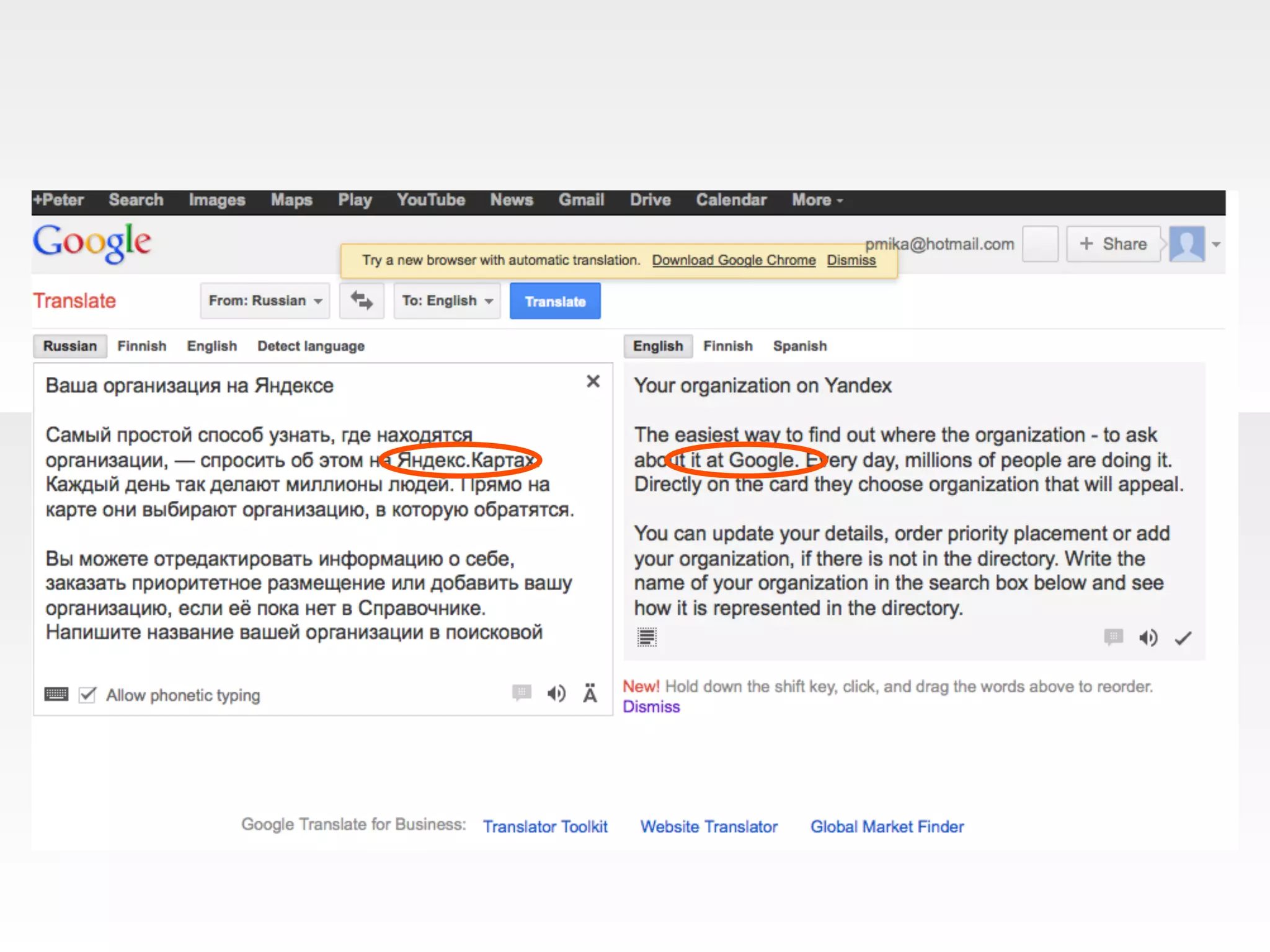

The document discusses the evolution and importance of integrating semantic technologies into search mechanisms and online media. It covers various techniques for improving search relevance, such as RDF, RDFa, and microdata, highlighting their roles in data integration and enhancing user interaction. The document emphasizes the need for a shared understanding of data representation to optimize search experiences and behavior personalization.






















































































![Vibe Coding vs. Spec-Driven Development [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/vibecodingvsspecdrivendevelopment-251209105622-43f455e7-thumbnail.jpg?width=640&height=640&fit=bounds)







![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)