Download as ODP, PPTX











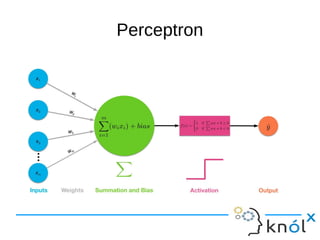

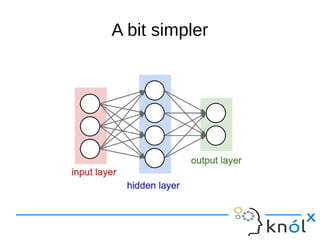






























The document provides an overview of machine learning and artificial neural networks, detailing concepts such as perceptrons, activation functions, training and error, and backpropagation. It highlights the importance of these components in creating effective neural networks and discusses various machine learning techniques. Additionally, it addresses the limitations and potential biases present in machine learning applications.




































![AI-Lecture-11[Neural Network] updated.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/ai-lecture-11neuralnetworkupdated-251220065329-186ba89b-thumbnail.jpg?width=640&height=640&fit=bounds)


















































