Downloaded 103 times


















![Data Transformation
• Before classification data has to be prepared
• Data transformation:
– Discretization of continuous data
– Normalization to [-1..1] or [0..1]
• Data Cleaning:
– Smoothing to reduce noise
• Relevance Analysis:
– Feature selection to eliminate irrelevant attributes
• We finally get patterns/points/samples in the feature space that
represent out data
23Neural Networks Dr. Randa Elanwar](https://image.slidesharecdn.com/lecture8-150201050529-conversion-gate01/85/Introduction-to-Neural-networks-under-graduate-course-Lecture-8-of-9-23-320.jpg)




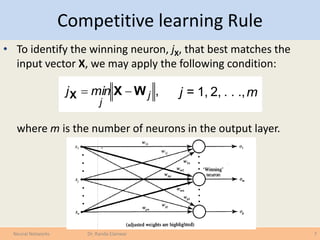
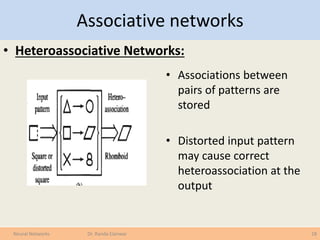
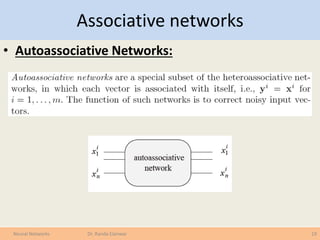
The document covers various learning laws in neural networks, particularly focusing on the competitive learning rule where neurons compete to activate one winner at a time, adjusting weights based on input patterns. It also discusses associative networks, classification processes, data transformation, and the importance of preparing data for effective classification and prediction tasks. Additionally, it explains different types of associative networks and their applications in pattern recognition and data classification.