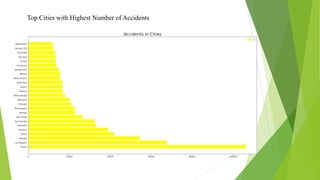
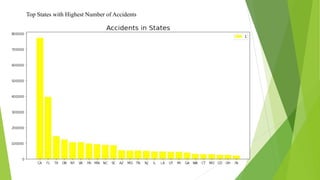
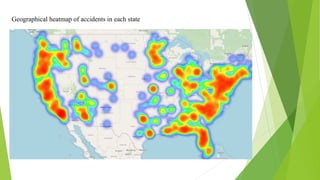
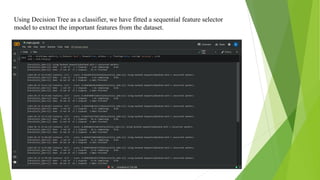
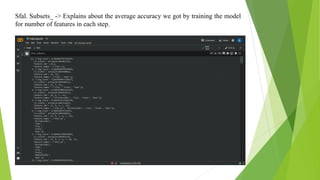
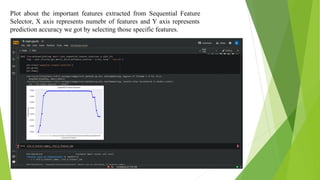
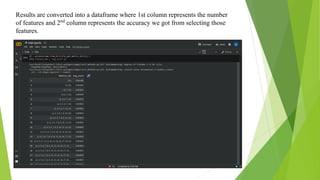
The document discusses a machine learning statistical model developed using transportation data, specifically focusing on road accidents in the US from 2016 to 2021. It describes the dataset from Kaggle, including its structure, key features, data preprocessing steps, and predictive analysis techniques such as decision trees, random forest, and k-nearest neighbors for predicting accident severity. The project emphasizes the importance of variable selection methods and the application of machine learning algorithms to enhance insights into road transportation safety.