Download to read offline






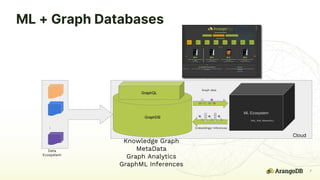





























The document discusses the integration of machine learning and graph databases for improving recommendation systems, particularly through the ArangoDB and its Arangoflix project. It covers various techniques including collaborative filtering, content-based recommendations, and the use of graph neural networks. It outlines the advantages of graph databases in handling complex relationships and offers practical applications across diverse domains such as product recommendations and customer analysis.



































































