Download as PDF, PPTX





















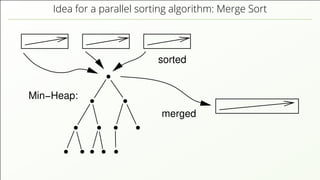
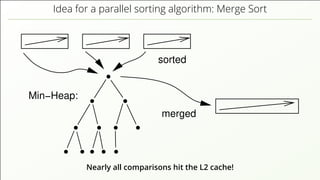


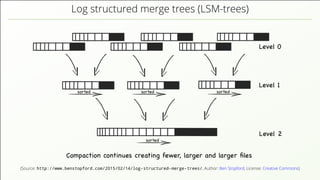









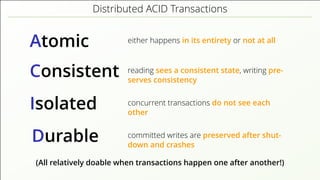

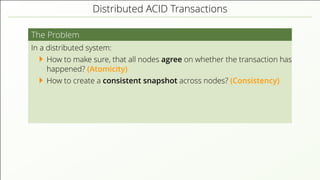





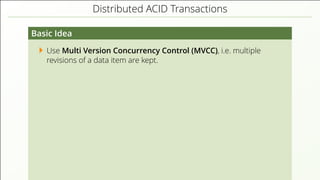
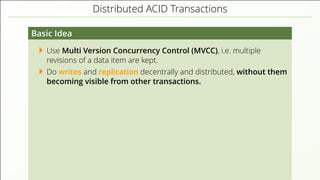





The document discusses the complexities of implementing modern distributed databases, focusing on concepts such as resilience, consensus protocols (Paxos and Raft), sorting algorithms, log-structured merge trees (LSM-trees), hybrid logical clocks (HLC), and distributed ACID transactions. It emphasizes the importance of understanding these computer science principles to ensure data consistency and performance in distributed systems. Several methodologies and their challenges are outlined, as well as various databases that implement these concepts.




















































































