This document discusses machine learning techniques for diagnosing cardiac disease. It evaluates three datasets using different machine learning algorithms and proposes a custom convolutional neural network and extreme gradient boosting hybrid model that shows better accuracy. It also proposes a custom sequential dense neural network model with seven layers that achieves 92.3% accuracy on a modified Cleveland dataset for diagnosing cardiac disease. Previous related work applying machine learning methods like decision trees, K-nearest neighbors, and neural networks to cardiac disease diagnosis is also reviewed.
![Vol.:(0123456789)
SN Computer Science (2023) 4:673
https://doi.org/10.1007/s42979-023-02081-9
SN Computer Science
ORIGINAL RESEARCH
Diagnosis of Cardiac Disease Utilizing Machine Learning Techniques
and Dense Neural Networks
K. Prabhavathi1,2
· V. Mareeswari3
Received: 7 June 2023 / Accepted: 24 June 2023
© The Author(s), under exclusive licence to Springer Nature Singapore Pte Ltd 2023
Abstract
In numerous different polls, heart illnesses constantly rank among the leading causes of death. The reason behind is the
complexity of these diseases and the high prevalence of incorrect diagnoses. This is a huge obstacle for those who work in
the medical field. Since machine learning (ML) has been shown to be incredibly excellent at estimate and decision-making,
it is necessary to develop a system that can identify cardiac disease. A heart disease diagnosed in its initial phases not only
makes it possible for patients to avoid having one, but it also makes it possible for medical professionals to gain knowledge
about the primary risk factors for heart attacks and take precautions against them before they happen to a patient. In this study,
we experimented on three different datasets with different ML algorithms to diagnose heart disease. These datasets have
various medical and customary information about the patients, which are necessary elements to determine whether a patient
has heart disease or not. Hybrid model proposed by combining custom convolution neural network and extreme gradient
boosting shows better accuracy in finding heart diseases among all standard machine-learning methods. We also proposed
a custom sequential model formed with seven dense layers to diagnose a patient with cardiac disease. This proposed model
performed well, with an accuracy of 92.3% when applied to the modified Cleveland dataset.
Keywords Machine learning · Coronary heart disease (CHD) · Myocardial infarction (MI) · DT · KNN · SVM
Introduction
Heart disease is the most common, most lethal and complex
of all life-threatening conditions and can affect anyone and
primarily shows up after age 40. Several factors contribute
to heart disease, and age is only one of them, making the
possibility of heart disease seem almost arbitrary. This calls
for models that can detect abnormalities in physiological
factors that can indicate dysfunction in the behavior of the
human heart [1].
Currently, with more and more people making lifestyle
choices that are not well suited to them for the sake of their
professions or otherwise, heart disease has become more
prevalent than before [2, 3]. Heart diseases can comprise
a range of afflictions that affect the heart and can also be
called cardiovascular diseases or CVD. As per the recent
statistics of the World Health Organization, heart diseases
are prominent reason of demise worldwide. Many factors
can indicate the possibility of heart disease, and they have
been concisely depicted in Fig. 1.
Strokes are commonly caused by bleeding blood ves-
sels (hemorrhagic stroke) or the blockage of a blood vessel
with a blood clot (ischemic stroke). Most strokes are caused
by high blood pressure. Strokes are closely linked to heart
attacks, and they have similar risk factors [4].
A family history of cardiovascular diseases can also
increase an individual’s risk of developing heart diseases.
There does not exist an individual gene that causes heart
disease, but several genes coming together might be a cause
for concern [5].
This article is part of the topical collection “Advances in
Computational Approaches for Image Processing, Wireless
Networks, Cloud Applications and Network Security” guest edited
by P. Raviraj, Maode Ma and Roopashree H R.
* K. Prabhavathi
prabhavathi5218@gmail.com
V. Mareeswari
mareesh.prasanna@gmail.com
1
Department of CSE, ACSCE, Bengaluru, India
2
Department of CSE, RVITM, Bengaluru, India
3
Department of CSE, AMC Engineering College, Bengaluru,
India](https://image.slidesharecdn.com/s42979-023-02081-9-240417172349-f54053d2/75/Diagnosis-of-Cardiac-Disease-Utilizing-Machine-Learning-Techniques-and-Dense-Neural-Networks-1-2048.jpg)
![SN Computer Science (2023) 4:673
673 Page 2 of 14
SN Computer Science
Excessive consumption of liquor is unquestionably
harmful and can lead to severe heart disorders; however,
consuming alcohol moderately has been associated with
a lowered probability of cardiovascular events occurring.
However, high alcohol consumption is proven to be injuri-
ous, and therefore, alcohol should be consumed in mod-
eration [6, 7].
Moderate to vigorous physical activity has been associ-
ated with increased cardiovascular health [8], whereas sed-
entary behavior is emerging as a factor that has a negative
impact on the cardiovascular system. Any awake habit that
involves spending fewer than 1.5 metabolic units sitting,
lying down, or otherwise reclined is considered sedentary
[9]. A study reported robust evidence that daily sitting time
was proportional and increased the risk of CVD mortality. In
order to lower the risk of getting a cardiac disease, physical
health is also crucial.
There are several complicated investigative ways to fore-
tell heart disease, which has a diverse nature and is a sig-
nificant reason that affects human life today. As a result,
heart disease therapy is particularly complicated, especially
in underdeveloped countries, due to the limited availability
of a working framework and a scarcity of doctors and other
resources that influence the expectations and treatment.
Therefore, a vast amount of information that medical ser-
vices businesses possess, some of which are veiled, is help-
ful in deciding on robust options to provide accurate results
to make practical judgments based on information. This is
where the machine-learning methods come in the picture.
Machine learning ultimately proves to be convincing in aid-
ing decision-making and anticipation from the abundance
of data provided by the medical services sector to decide on
contrary-based heart disease diagnosis.
In this study, we implemented various machine-learning
techniques on three different datasets based on historical
data collected from patients to foretell relating to a patient’s
heart condition. We also proposed a custom model based
on a sequential system made of dense layers, which yields
notable accuracy, making it an efficient model for heart dis-
ease prediction.
Related Works
For categorizing and predicting cardiac illness, a number
of machine-learning models have been used in numerous
studies. Peter et al. suggested a technique for assessing the
results of several classification methods, including DT, NB,
KNN, NNon a dataset pertaining to heart disease [10]. They
categorize patient data and forecast who may develop cardio-
vascular problems. Melillo et al. [11] used a machine-learn-
ing method called CART, which stands for classification
and regression, to design an autonomous classifier that can
identify between patients who are at high risk of developing
congestive heart failure and patients who are at low risk.
This classifier has a sensitivity of 93.3% and a specificity of
63.5%. To enhance performance, Al Rahhal et al. [12] sug-
gested a method for analyzing electrocardiograms (ECGs)
that used deep neural networks to find the best qualities and
then apply them. Later, Dun et al. [13] experimented with
different algorithm approaches to identify heart illnesses
and hyperparameter tinkering to increase the accuracy of
the results. Using Cleveland dataset and the random forest
Fig. 1 Indicators of cardiovas-
cular disease](https://image.slidesharecdn.com/s42979-023-02081-9-240417172349-f54053d2/75/Diagnosis-of-Cardiac-Disease-Utilizing-Machine-Learning-Techniques-and-Dense-Neural-Networks-2-2048.jpg)
![SN Computer Science (2023) 4:673 Page 3 of 14 673
SN Computer Science
method, Javeed et al. conducted research on cardiovascular
disease [14]. For the study, the author employed the Chi-
Square feature selection model in addition to the genetic
algorithm (GA)-based feature selection model. They dem-
onstrated in their experiments that their suggested model,
which uses genetic algorithms to pick features, is more accu-
rate than the models already in use. However, these find-
ings are compared to previously developed machine-learn-
ing models for evaluation. Uma et al. developed particular
criteria for identifying heart illness depending on this PSO
algorithm and then assessed various rules to arrive at a more
accurate practice [15]. Following an analysis of the criteria,
the C 5.0 system was chosen as the basis for categorizing
diseases using a binary system. In the implementation, the
author made use of data from the UCI repository, and they
assessed the high accuracy achieved by employing PSO and
the decision tree method.
It was addressed by Desai et al. how a back propaga-
tion neural network may be used to forecast cardiac disease
[16]. During the research, the authors utilized the Cleveland
dataset and Matlab to carry out the simulation. Nevertheless,
the task may be accomplished using deep learning models,
which are exceedingly precise, and this capability can be
expanded to include applications in the real world. Enriko
et al. suggested the use of data mining techniques to make
predictions regarding heart disease [17]. They used a range
of techniques and methodologies for their study and analysis,
including the KNN algorithm, the decision tree algorithm,
classifications based on neural networks, and Bayesian clas-
sification algorithms. They conducted their own experiments
using the paper, finding that the decision tree model had a
high level of accuracy.
Employed a variety of classification algorithms to identify
severe cardiac syndromes based on risk rate by the author
was used a method known as data mining utilized an artifi-
cial neural network in conjunction with a genetic algorithm
in order to forecast illnesses affecting the human body [18,
19]. The authors of this reference worked together to com-
bine the data mining approach using association rules and
classification strategies. In this aspect, the author’s model
effectively makes accurate predictions regarding cardiac ail-
ment. An in-depth discussion provided on cardiovascular
illness as well as the many signs of a heart attack. In this
study, many distinct classification and clustering approaches,
as well as the associated algorithms and tools, were utilized
[20].
An analysis utilizing data mining has been discussed.
According to the study’s findings, the accuracy of the pre-
diction of cardiac disorders varies depending on the meth-
odology utilized and the number of characteristics taken into
consideration [21, 22]. Some of the researchers examined
the findings and analyses of the UCI Machine Learning
Heart Disease dataset using a number of machine-learning
and deep learning approaches. When data pre-processing is
added to the dataset’s 13 features, the K-Neighbors classifier
fared better in the ML technique [23]. Using smartphone
technology, More et al. [24] proposed a risk factor-based
method to predict the possibility of experiencing a heart
attack. They built an android application that is connected
with bioinformatics tools comprised of the final diagnoses of
more than 500 patients hospitalized in a cardiology hospital.
Scientists have utilized a k-means clustering technique to
integrate a repository for cardiac disorders. MAFIA (Maxi-
mal Frequent Itemset Algorithm) was used to determine the
standard relevance of the most prevalent patterns that led to
heart attacks [25, 26].
Nashif et al. [27] used a cognitive method to assess a
patient’s chance of having heart disease. In this study, five
different ML algorithms were assessed for their ability to
make accurate predictions, and the results are presented. In
order to get more accurate results in prediction, a logistic
model tree was developed. This model, which employed an
ADA boost and bagging model, was used to forecast heart
disease. The findings of their investigations have shown that
random forests may attain a high level of accuracy when
making predictions. Another study with a similar approach
was done by Angraal et al. [28]. This research used classifi-
cation and regression models, namely the decision tree, the
KNN algorithm, the SVM, and the linear regression process,
to make predictions. The findings of the experiment demon-
strated that the KNN algorithm had the best degree of preci-
sion. On the other hand, this model is adaptable enough to
be used in real-time environments or applications.
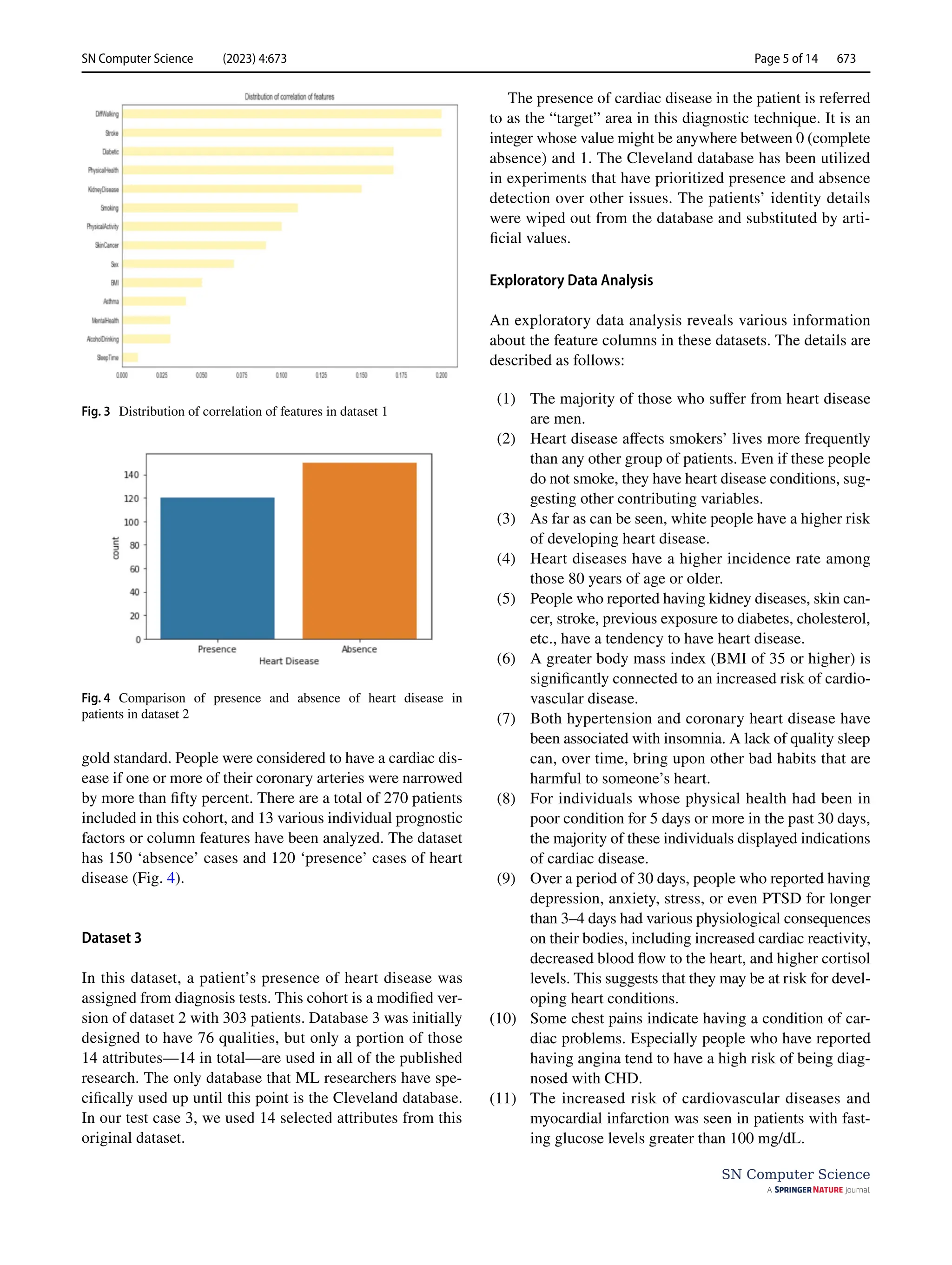
Datasets and Exploratory Data Analysis
According to the Centres for Disease Control and Prevention
(CDC), heart disease affects the majority of racial and ethnic
groups in the United States [29]. Hypertension and smok-
ing are three most important risk factors for heart disease
[30], yet about half of all Americans are affected by at least
one of these risk factors. Other critical indicators include
having diabetes, having a high body mass index (BMI),
being overweight, and either not getting enough exercise
or drinking too much alcohol [31]. In medicine, it is of the
utmost importance to identify the risk factors for cardiovas-
cular disease and take preventative measures against them.
In turn, improvements in computational technology make it
possible to apply machine-learning methods to analyze data
to identify ‘patterns’ that can be used to anticipate a patient’s
status [32, 33].
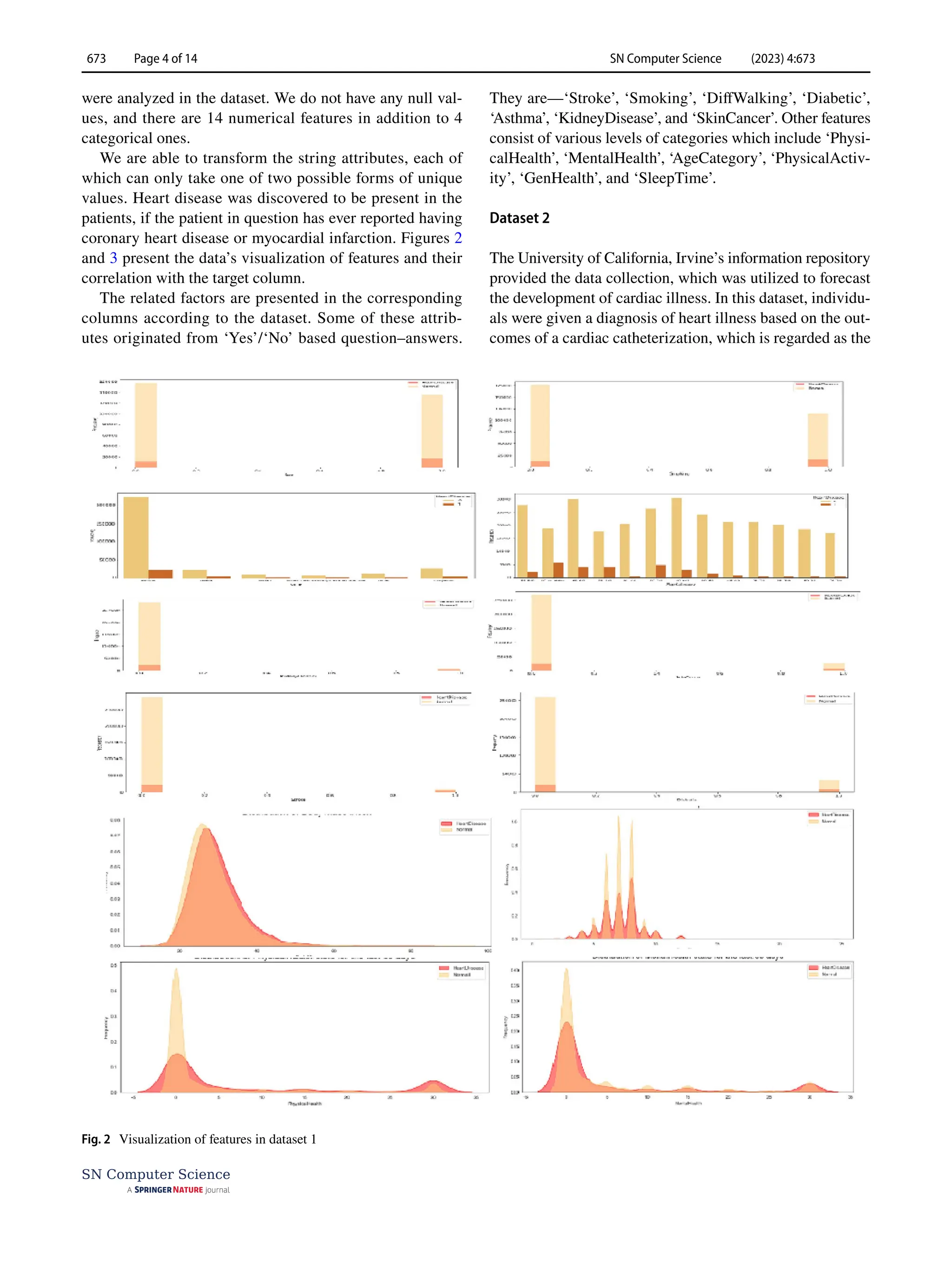
Dataset 1
This dataset was comprised of data accumulated from
319,795 numbers of patients. Here, 18 different features](https://image.slidesharecdn.com/s42979-023-02081-9-240417172349-f54053d2/75/Diagnosis-of-Cardiac-Disease-Utilizing-Machine-Learning-Techniques-and-Dense-Neural-Networks-3-2048.jpg)


![SN Computer Science (2023) 4:673
673 Page 10 of 14
SN Computer Science
gets terminated immediately whenever an observed metric
ceases progressing.
Extreme Gradient Boosting (XGBoost)‑Proposed
Model
Gradient boosting algorithm is utilized to anticipate the
target by combining evaluations of a lot of less complex
models. It maps the information highlight to its leaves which
possess a nonstop score. XGBoost limits a regularized target
work that joins a curved misfortune in particular multifac-
eted nature. The preparation continues repetitively by includ-
ing new set of trees to foresee the mistakes in earlier ones in
order to join them with the prior ones. Henceforth termed as
angle boosting on the grounds that it utilizes an inclination
plunge calculation to limit the loss. In order to minimize the
next goal, we must add ft to the formal forecast made by y
_i((t)) for the i-th instance at the t-th iteration:
This suggests that we incorporate
ft, which enhances our
model. In the generic setting, the aim can be quickly opti-
mized using second-order approximation:
The loss function’s first- and second-order gradient sta-
tistics are g_i = _(y_i((t−1))) l(y_i,y_i((t−1))) and h_i = _
(y_i((t−1))))2. We can remove the constant terms at step t
to accomplish the more direct objective described as follows:
The instance set of leaf j is defined as Ij ={i|q(xi)=j} By
expanding, we can reformat Eq. (1) as follows:
(5)
L(t)
=
n
∑
i=1
l(yi, ̂
y(t−1)
i
+ ft(xi)) + Ω(ft)
(6)
L(t)
≃
n
∑
i=1
[
l
(
yi, ̂
y(t−1)
i
)
+ gift(xi) +
1
2
hif2
t
(xi)
]
+ Ω (ft)
(7)
̃
L
(t)
=
n
∑
i=1
[
gift(xi) +
1
2
hif2
t
(xi)
]
+ Ω(ft)
(8)
̃
L
(t)
=
n
�
i=1
�
gift(xi) +
1
2
hif2
t
(xi)
�
+ 𝛾 T +
1
2
𝜆
T
�
j=1
w2
j
=
T
�
j=1
⎡
⎢
⎢
⎢
�
�
i∈Ij
gi
�
wj +
1
2
⎛
⎜
⎜
⎝
�
i∈Ij
hi + 𝜆
⎞
⎟
⎟
⎠
w2
j
⎤
⎥
⎥
⎥
+ 𝛾T
For a fixed structure q(x), we find the optimum weight
w_j* of leaf j by
and determine the associated value by
We combined weighted CNN and XGBoost and for pre-
dicting the heart disease presence and absence classes.
Results and Discussion
This study aims to identify the presence or absence of a
cardiac disease issue. Various classification techniques such
as DT classifier, RF classifier, LR, KNN, and SVM were
utilized to classify the heart disease condition (‘Yes’/‘No’
or ‘present’/‘absent’) in patients.
The Performance of the Models
We used various equations to determine the performance
of the models used in this study. Usually, a classification
algorithm’s performance is evaluated using a table called
a confusion matrix (Table 1). In a confusion matrix, each
row denotes a real class, whereas each column indicates a
predicted class.
From the confusion matrix, we get various parameters to
measure the performance and efficiency of a model. They
are presented in Eqs. (10–16):
(9)
w∗
j
= −
∑
i∈Ij
gi
∑
i∈Ij
hi + 𝜆
,
(10)
̃
L
(t)
= −
1
2
T
�
i=1
�∑
i∈Ij
gi
�
∑
i∈Ij
hi + 𝜆
+ 𝛾T
(11)
Total Predicted Positive = True Positive + False Positive
(12)
Total Actual Positive = True Positive + False Negative
(13)
Precision =
True Positive
Total Predicted Positive
(14)
Recall =
True Positive
Total Active Positive
(15)
F1score = 2
(
Precision × Recall
Precision + Recall
)
(16)
Accuarcy =
True Positive + TrueNegative
(True Positive + True Negative + False Positive + False Negative)](https://image.slidesharecdn.com/s42979-023-02081-9-240417172349-f54053d2/75/Diagnosis-of-Cardiac-Disease-Utilizing-Machine-Learning-Techniques-and-Dense-Neural-Networks-10-2048.jpg)
![SN Computer Science (2023) 4:673 Page 11 of 14 673
SN Computer Science
Here p0 and pe indicate observed and expected agreement,
respectively.
(17)
Cohen’s kappa score =
p0 − pe
1 − pe
Another performance parameter is the ROC curve
which is the graph of receiver operating characteristics.
This graph is plotted using a true-positive rate and a false-
positive rate. Figure 11 presents the evaluation metrics and
ROC curve plots for the decision tree and KNN models
[34]. From the evaluation metrics (Table 2) of the deci-
sion tree and KNN model employed on dataset 1, it is seen
that custom CNN with combination of weighted XGBoost
gives better result when employed on dataset 1.
In Experiment 2, three different models were employed
on dataset 2. They were supporting vector machine, KNN,
and decision tree classifier. These models accurately pre-
dicted 95 heart disease conditions, but all of their other per-
formance parameters differed (Table 3). Both support vector
machine and KNN models were close enough in the cases of
Fig. 12 Model comparison for heart disease detection for decision tree and KNN models: evaluation metrics plot (left) and ROC curve (right)
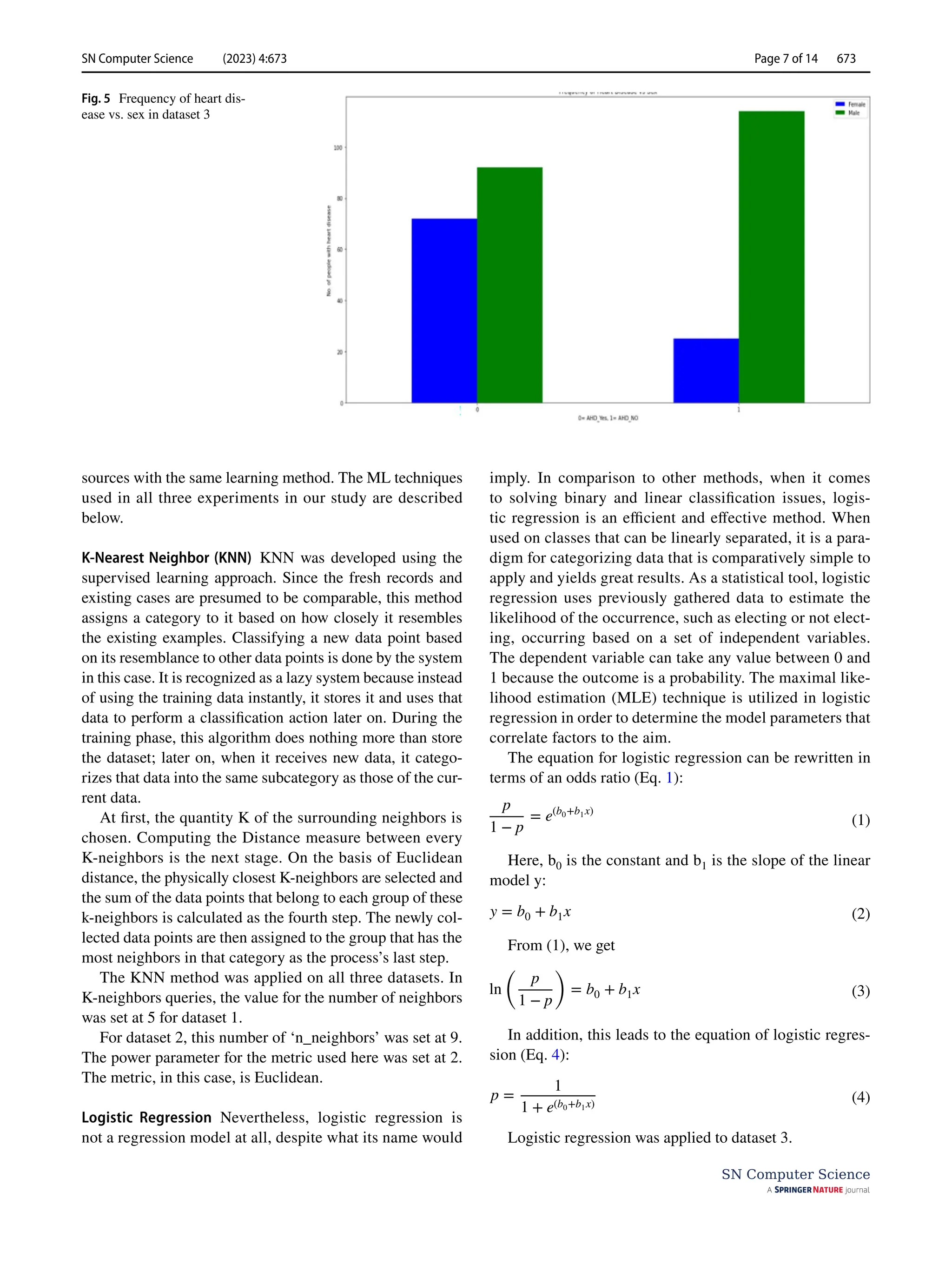
Fig. 13 Graphical representa-
tion of accuracy, loss, validation
accuracy, and validation loss
for the custom model when
employed on dataset 3
Table 1 The confusion matrix
Actual Predicted
Negative Positive
Negative True negative False positive
Positive False negative True positive](https://image.slidesharecdn.com/s42979-023-02081-9-240417172349-f54053d2/75/Diagnosis-of-Cardiac-Disease-Utilizing-Machine-Learning-Techniques-and-Dense-Neural-Networks-11-2048.jpg)
![SN Computer Science (2023) 4:673
673 Page 12 of 14
SN Computer Science
precision, recall, and F1-scores. The support vector machine
shows an accuracy of 77%, which is greater than the other
two classifiers.
In Experiment 3, we employed four different machine-
learning classifier models on dataset 4. The first three were
logistic regression, random forest, and k-nearest neighbor
classification techniques. Two new performance parameters
which are called the R2 score and the AUC score, respec-
tively, were used in this experiment for comparison of model
performances [35, 36]. The R2 score works by figuring out
how much of the variation in predictions the dataset can
account for. Simply put, it is the difference between the pre-
dictions made by the model and the dataset’s samples. These
three models show R2 scores of 26.91%, 13.62%, and 6.97%.
The efficiency of a classifier to differentiate among classes
is measured by the Area-Under-the-Curve (AUC), which is
used as a synopsis of the ROC curve. The model is doing
better when it comes to differentiating between the positive
and unfavorable categories when the AUC value is larger.
These various performance metric values are presented in
Table 3 for the performance comparison of classifier models
used in Experiment 3.
The fourth model in Experiment 3 is a custom sequen-
tial model prepared by us. This model shows an accu-
racy of 80%, making itself an efficient classifier. The
performance metrics details of this model are presented
in Table 4. This model accurately predicts 61 instances.
Thirty-four of these predictions belonged to the ‘0’ class
Table 2 Comparison of
evaluation metrics for different
models in experiment 1
Build models Class Precision Recall F1-score Accuracy
Logistic regression 0 0.67 0.70 0.69 67.58
1 0.66 0.68 0.67
Random forest 0 0.76 0.77 0.77 75.72
1 0.75 0.76 0.76
KNN 0 0.80 0.78 0.79 76%
1 0.71 0.72 0.72
DT 0 0.73 0.65 0.69 77%
1 0.59 0.68 0.63
SVM 0 0.80 0.80 0.80 66%
1 0.72 0.72 0.73
Simple XGBoost 0 0.93 0.81 0.86 86.75
1 0.82 0.93 0.87
Weighted XGBoost 0 0.93 0.83 0.87 87.73
1 0.83 0.93 0.88
Simple CNN 0 0.86 0.83 0.84 84.58
1 0.83 0.87 0.85
Weighted CNN 0 0.86 0.88 0.87 87.24
1 0.89 0.87 0.88
Simple CNN+simple XGBoost 0 0.87 0.88 0.88 88.06
1 0.89 0.88 0.88
Simple CNN+weighted XGBoost 0 0.90 0.86 0.88 88.36
1 0.87 0.91 0.89
Custom CNN+weighted XGBoost 0 0.93 0.91 0.92 92.30
1 0.92 0.93 0.93
Table 3 Comparison of
evaluation metrics for different
models in experiment 3
Accuracy (%) Precision (%) Recall (%) F1 Score AUC score (%)
Logistic regression 81.97 80.77 77.78 0.7925 81.54
Random forest 78.69 76.92 74.07% 0.7547 78.21
KNN 77.05 76.00 70.37% 0.7308 76.36
Table 4 Evaluation metrics for custom sequential model
Model Accuracy Precision Recall (%) F1 score Support
Custom
sequential
80% 0 82 0.82 34
model 1 78 0.78 27](https://image.slidesharecdn.com/s42979-023-02081-9-240417172349-f54053d2/75/Diagnosis-of-Cardiac-Disease-Utilizing-Machine-Learning-Techniques-and-Dense-Neural-Networks-12-2048.jpg)









































![Understanding Parkinson’s Disease: Causes, Symptoms, and Treatment [2025]](https://cdn.slidesharecdn.com/ss_thumbnails/understandingparkinson-251208102525-80ba3223-thumbnail.jpg?width=640&height=640&fit=bounds)















