Downloaded 11 times






![Understanding
performance
of
computer
programs
Insight.
[Knuth]
Use
scien'fic
method
to
understand
performance
5](https://image.slidesharecdn.com/lyon2013v1-131105173619-phpapp02/85/Predicting-SPARQL-query-execution-time-and-suggesting-SPARQL-queries-based-on-query-history-6-320.jpg)


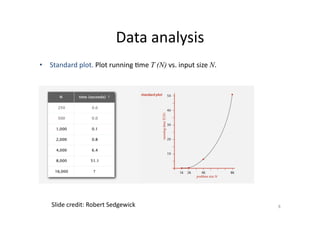
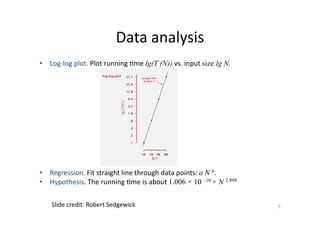





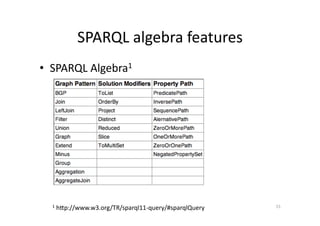
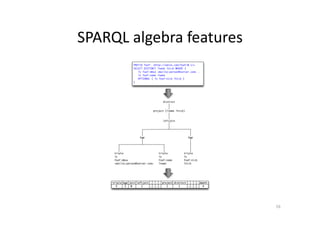

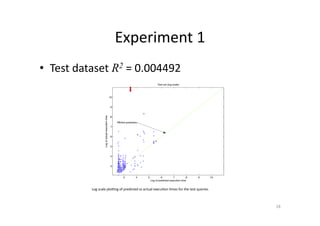






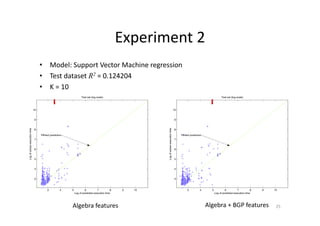




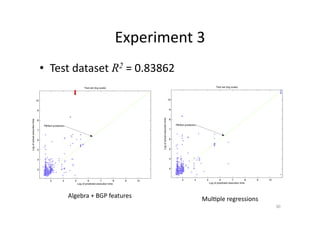


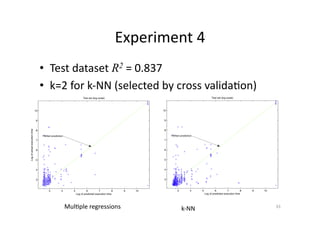







This document discusses predicting SPARQL query execution time using machine learning techniques. It first provides context on assisting users and agents in querying and consuming semantic web data. It then outlines predicting query times and suggesting similar queries from history. The document discusses applying the scientific method used for analyzing algorithms to understand query performance. It describes using machine learning to represent SPARQL queries as feature vectors to predict execution times, with the key challenge being effective feature engineering. An experiment uses support vector machine regression to predict times for test queries from DBpedia with mixed results.































































![Getting Started with Apache Spark: Big Data Made Simple [Free Meetup]](https://cdn.slidesharecdn.com/ss_thumbnails/apachesparkgettingstarted-260203175547-8361bcc3-thumbnail.jpg?width=640&height=640&fit=bounds)



