Downloaded 12 times

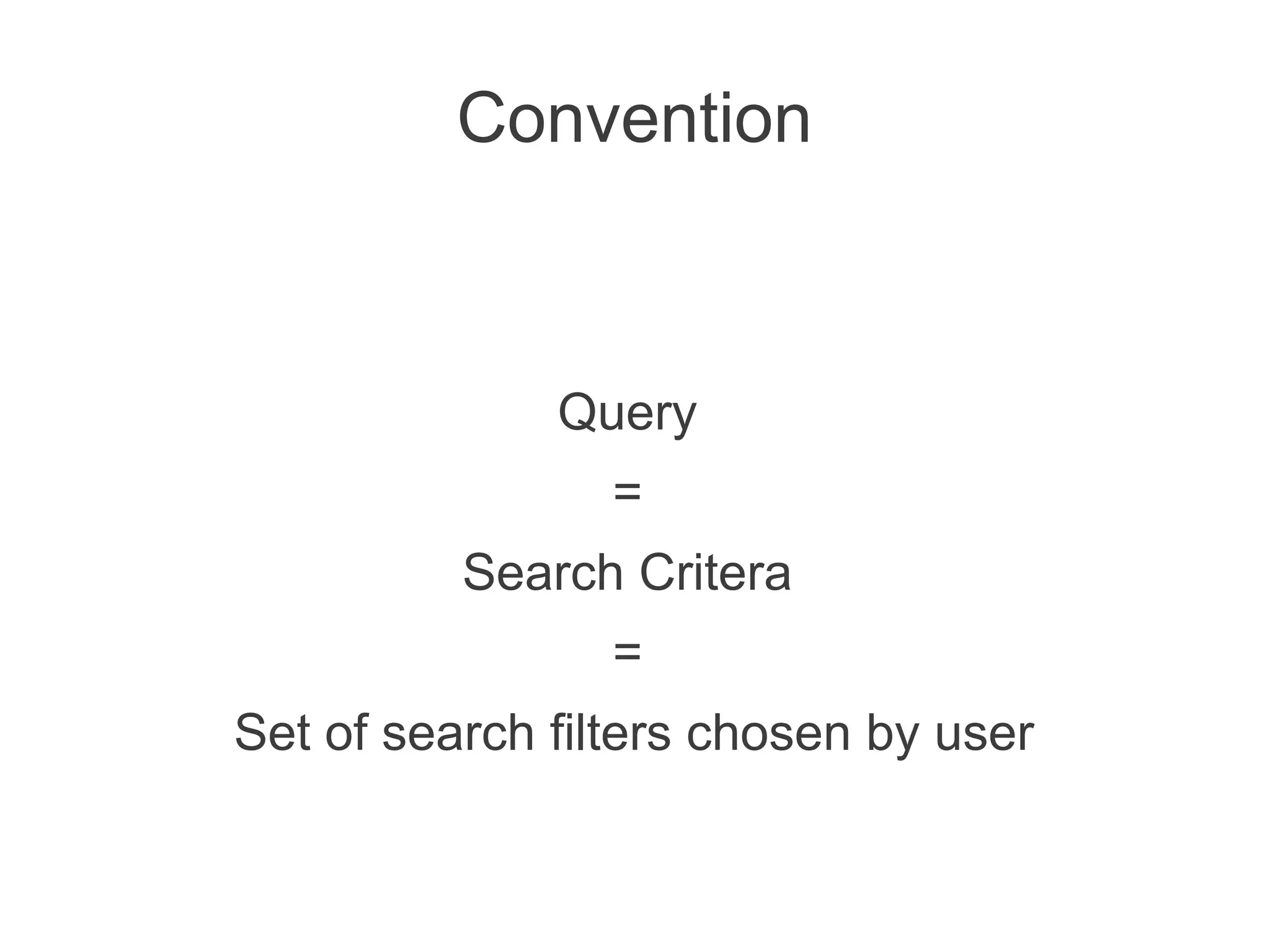
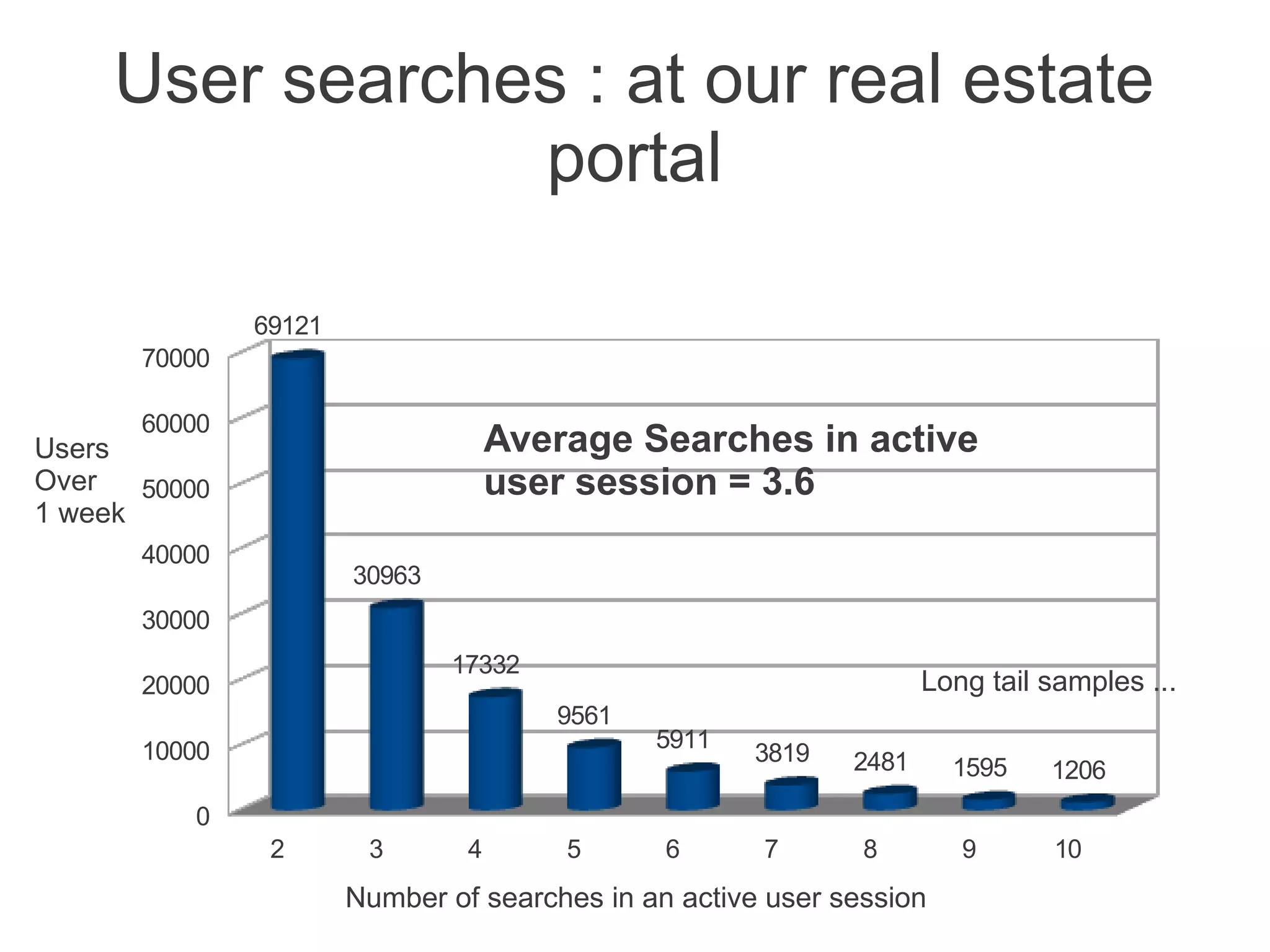


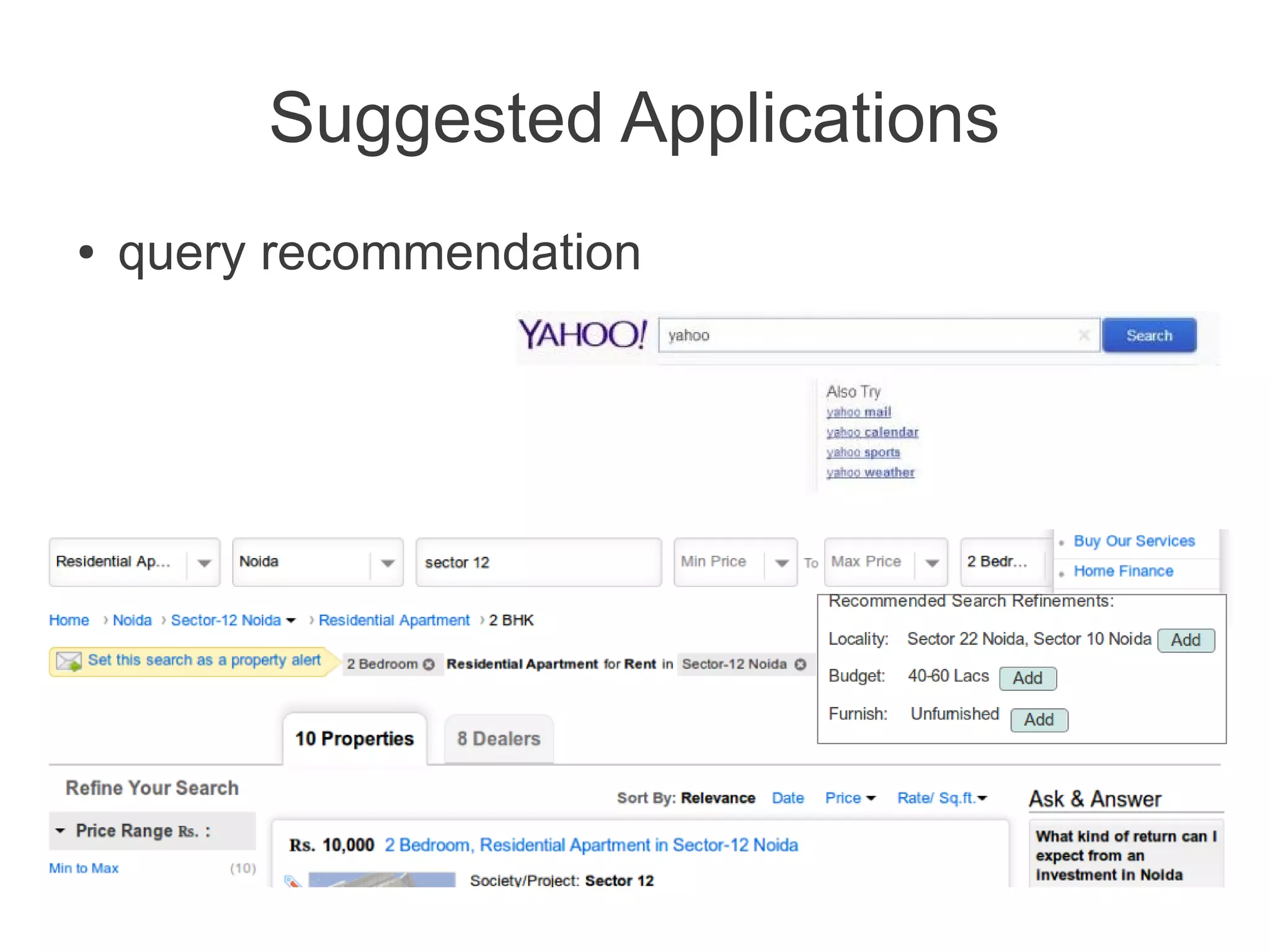
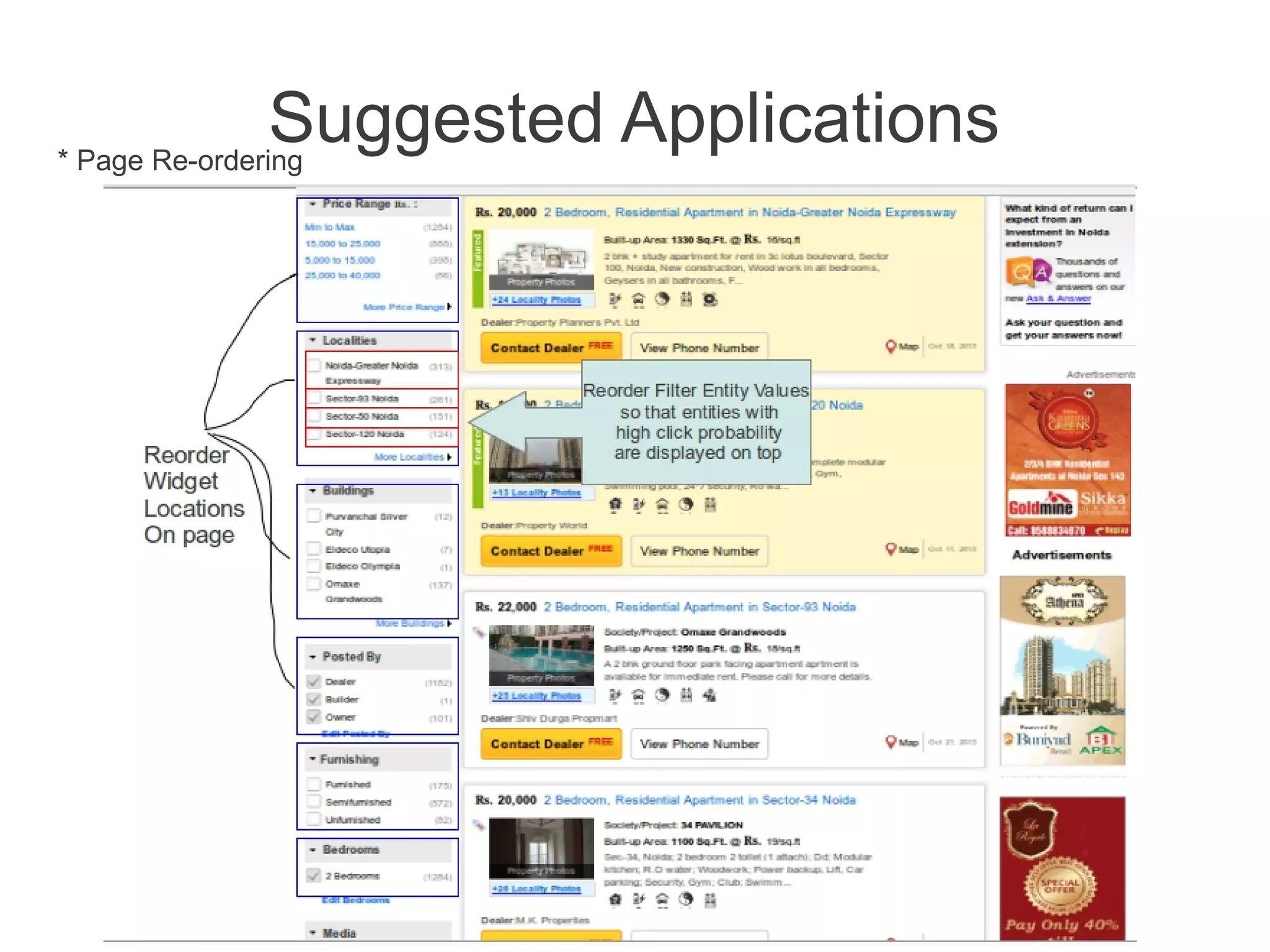
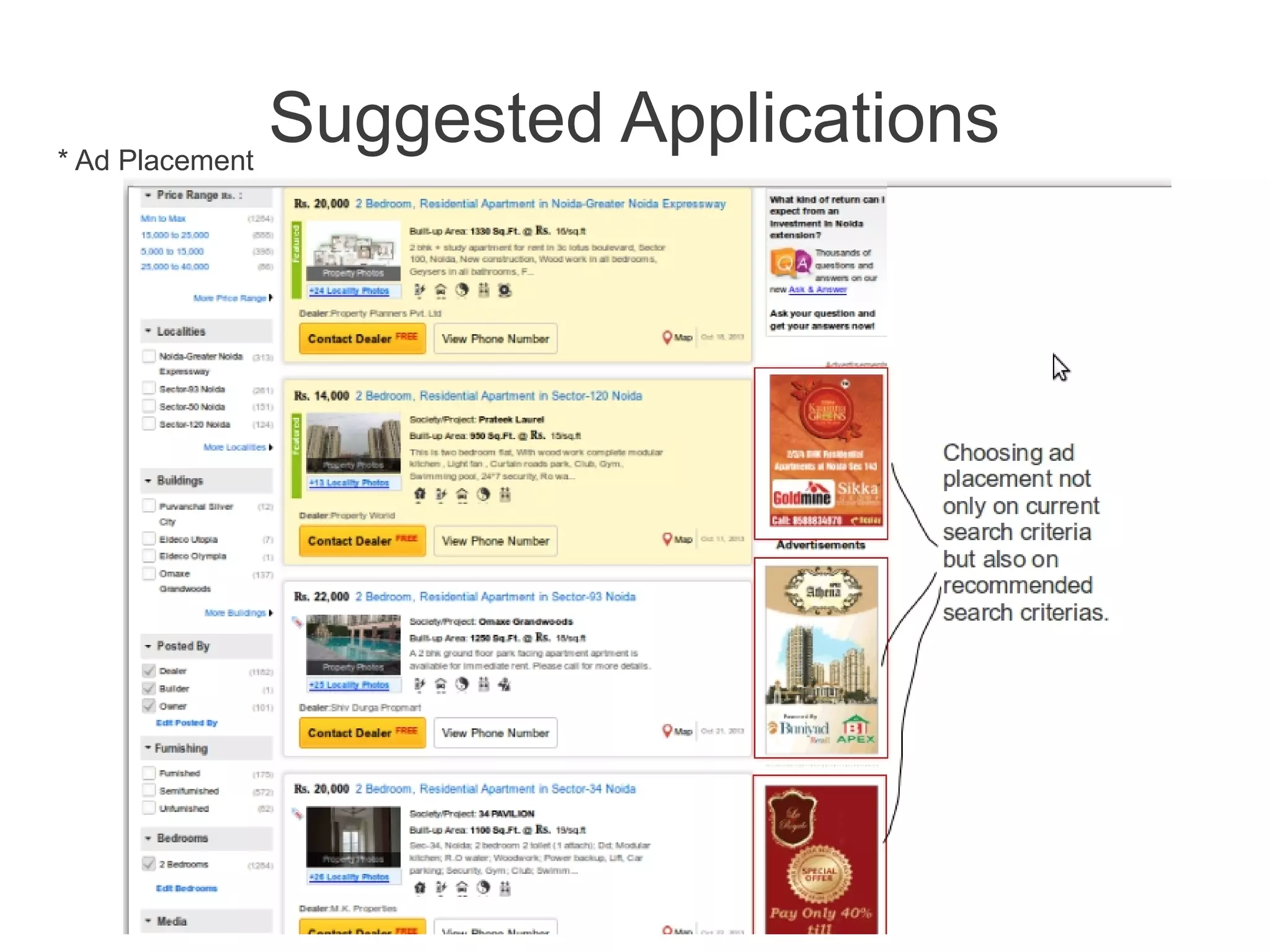














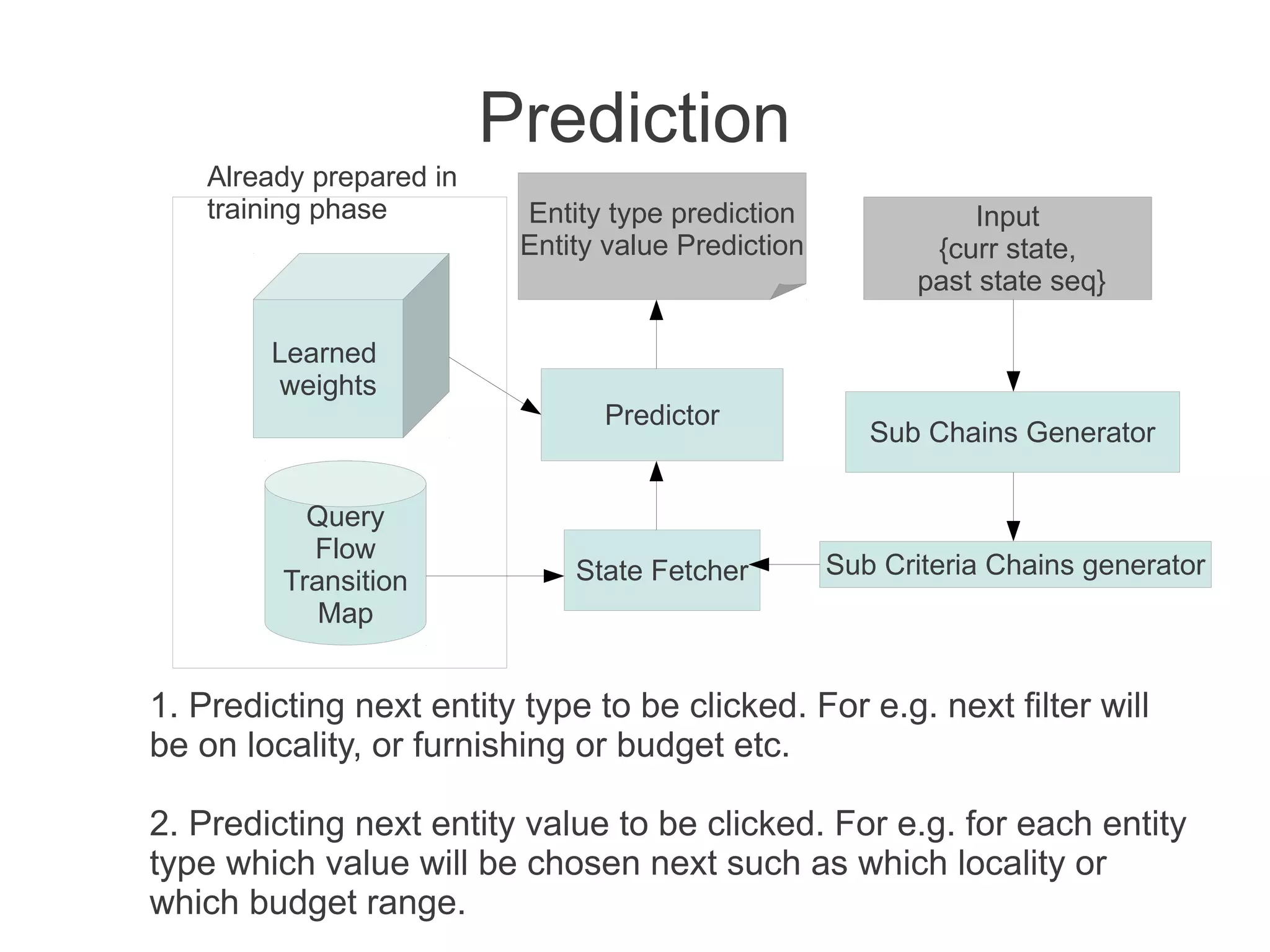




This document discusses using machine learning to predict a user's future search queries based on their search history. It proposes building a query flow graph using conditional probabilities calculated from historical query chains. This graph would be stored efficiently and queried to provide query recommendations. Testing on real estate search log data achieved 67-79% accuracy in predicting a user's next search criteria. The technique could benefit applications like query suggestions, page re-ordering, and ad placement.












































![Coded Agents – with UiPath SDK + LangGraph [Virtual Hands-on Workshop]](https://cdn.slidesharecdn.com/ss_thumbnails/codedagentsdeck-251215155422-5497c599-thumbnail.jpg?width=640&height=640&fit=bounds)


