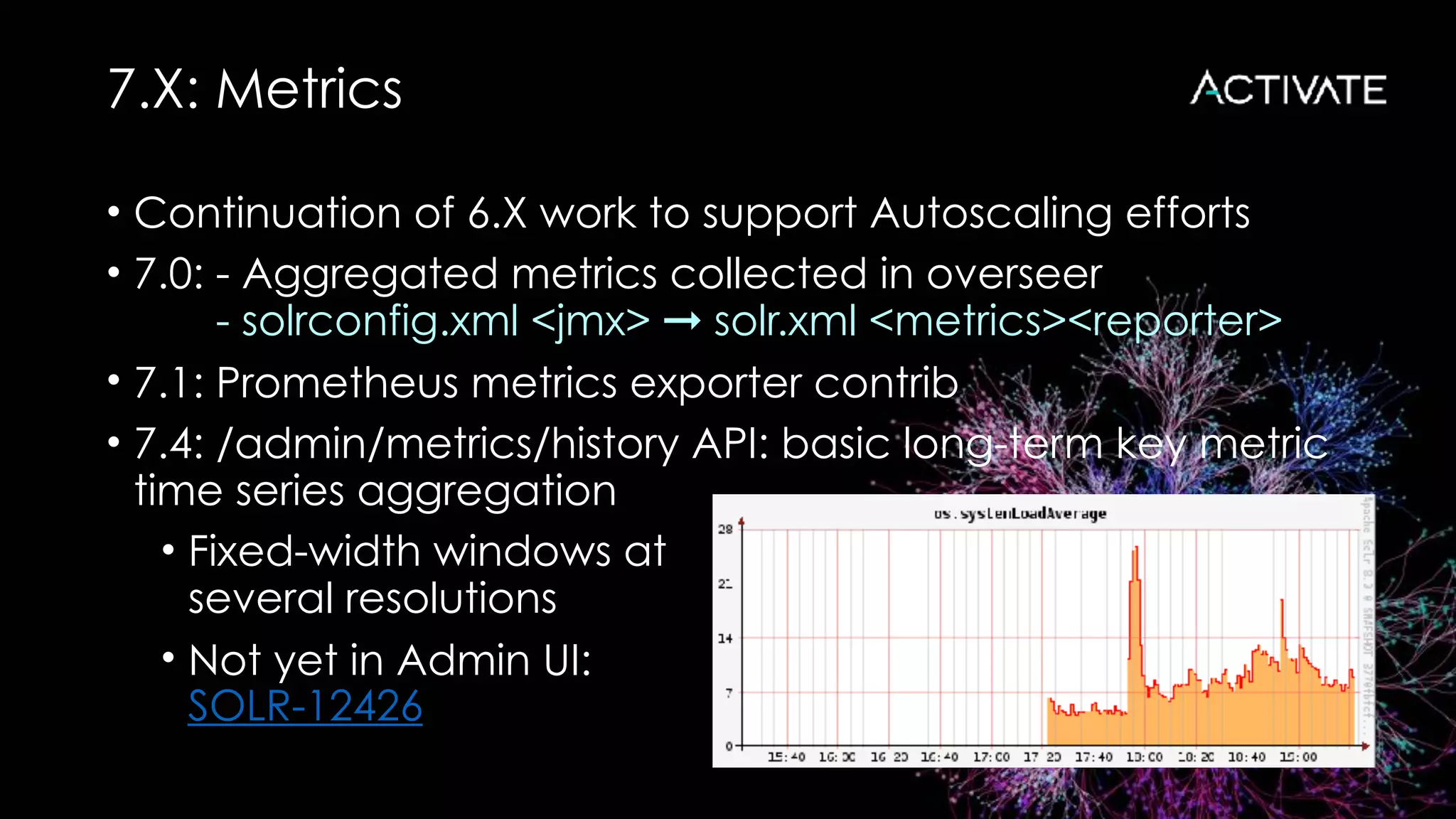
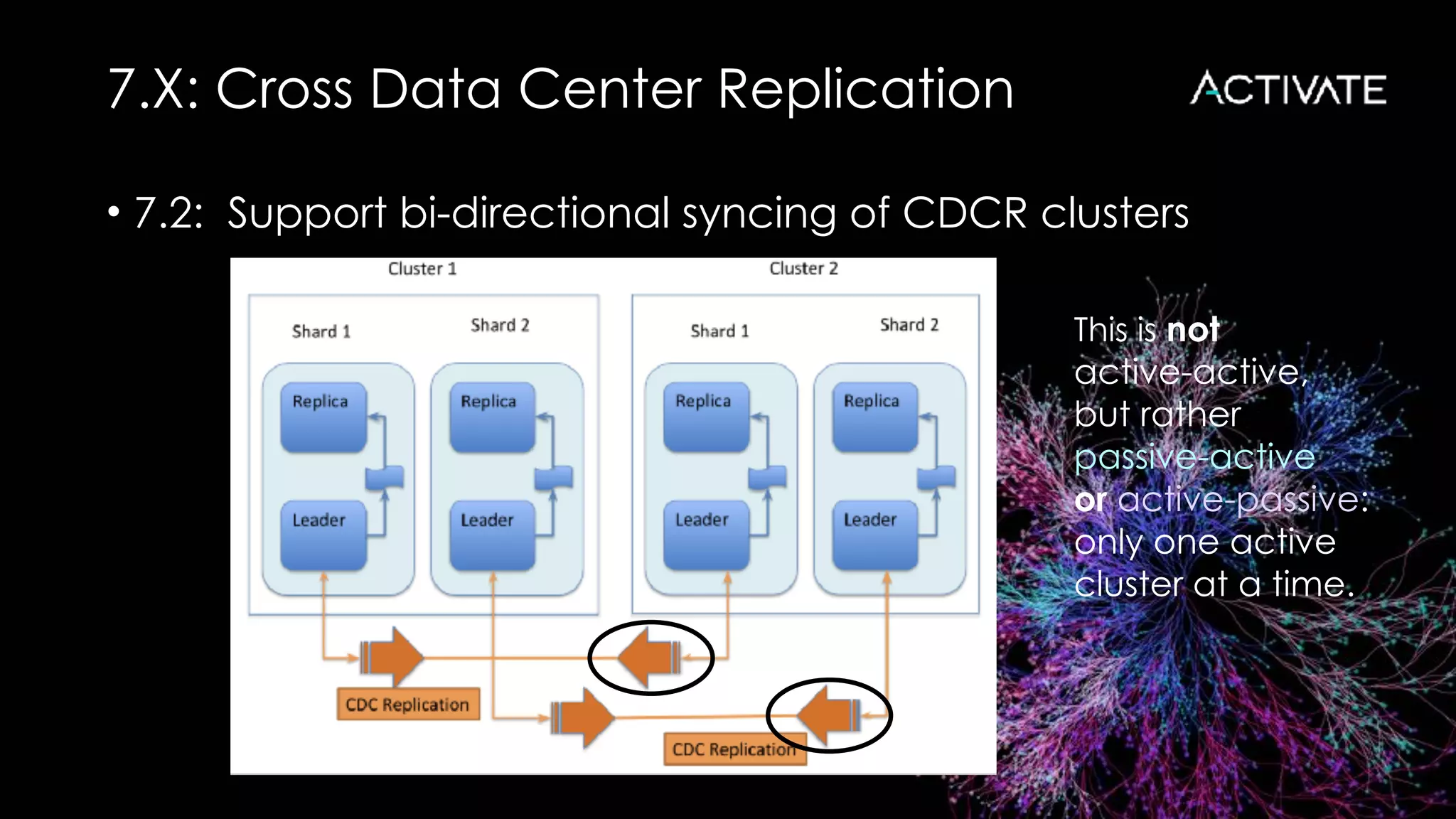
Download as PDF, PPTX




![7.X: Autoscaling
• 7.0: - Preferences and policy DSL: flexible replica placement
[ { minimize: cores }, { maximize: freedisk } ]
{ replica: "<2", shard: "#EACH", node: "#ANY" }
- Diagnostics API: return sorted nodes, policy violations
• 7.1: - autoAddReplicas ported to autoscaling framework
- Add/remove/suspend/resume triggers and listeners
- Triggers for added and lost nodes
- ComputePlanAction / ExecutePlanAction
- /autoscaling/history API: cluster events and actions
• 7.2: - Search rate trigger
- /autoscaling/suggestions API
- UTILIZENODE collections API command](https://image.slidesharecdn.com/roweactivate18-181022173202/75/Lucene-Solr-8-The-next-major-release-6-2048.jpg)









![7.X: Queries
• 7.1: JSON
query
DSL
curl http://localhost:8983/solr/books/query -d '
{
query: {
bool: {
must: [
"title:solr",
{lucene: {df: content, query: "lucene solr"}}
],
must_not: [
{frange: {u: 3.0, query: ranking}}
]}}}'](https://image.slidesharecdn.com/roweactivate18-181022173202/75/Lucene-Solr-8-The-next-major-release-17-2048.jpg)

















The document outlines the advancements and features in the upcoming Lucene/Solr 8 release, including improvements in autoscaling, metrics, cross data center replication, and new APIs like JSON facet and collections API. It highlights changes from previous versions, such as stricter index upgrades and the introduction of HTTP/2 for better performance. Overall, it discusses major enhancements aimed at scalability, efficiency, and usability in managing large datasets.



































































