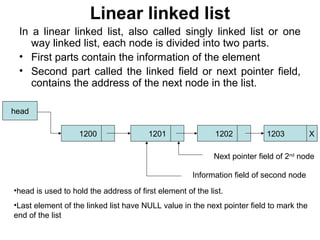
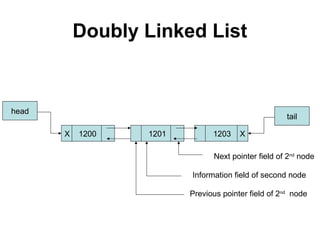
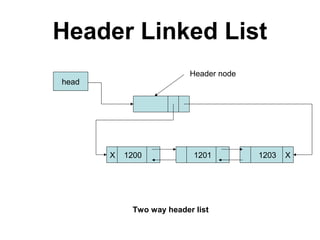
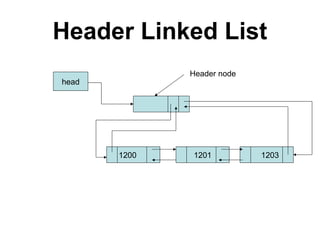
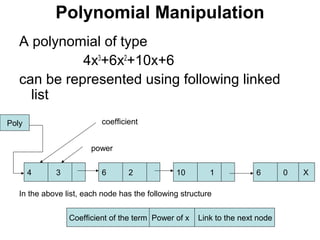
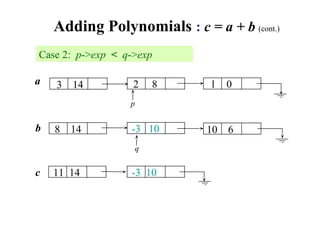
The document discusses lists and linked lists. It begins by describing lists and their implementations using arrays and linked lists. It then focuses on linked list implementations, describing linear linked lists and their representation, operations like traversal, search, insert, and delete. Doubly linked lists are also covered, along with their representation and similar operations. The document provides detailed code examples for many of the linked list operations.


![Array implementation of lists
• The linear array can be created at the compilation time by
using type declaration statement of type
int a[100];
• Which create linear array with 100 elements
• Since each elements takes two bytes of memory, the
compiler allocates 200 bytes for the array.
• The above array can be created at run time with the
following declaration statement
int *a;
a=(int*)malloc(100*sizeof(int));
In the above declaration, the malloc() function allocates 200
bytes of memory and assign the address of the first byte to
the pointer variable a.](https://image.slidesharecdn.com/cv0vlctbkk3astree1tw-signature-d9097abeae3fc5501630373cf3f9db62dd763c144c2d0bbd0568a6cb132602fe-poli-160427173638/85/Linked-list-3-320.jpg)





















































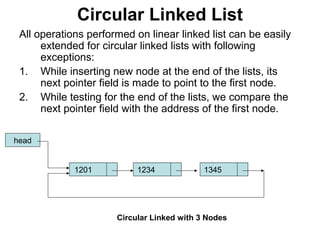


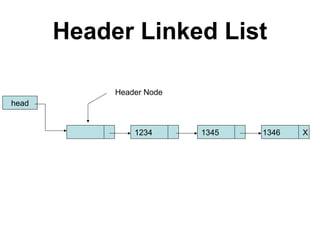

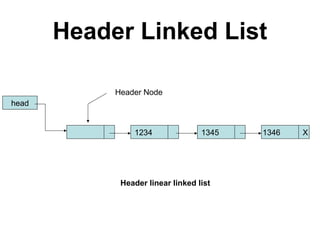
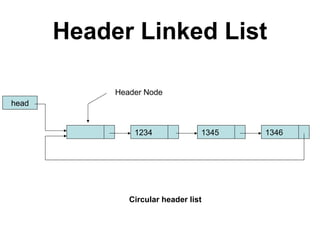






















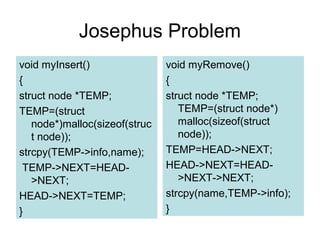
![Josephus Problem
#include <stdio.h>
#include <conio.h>
#include <stdlib.h>
#include <string.h>
struct node
{
char info[25];
struct node *NEXT;
};
struct node *HEAD;
struct node *TAIL;
char name[25];
void myInit()
{
HEAD=(struct node *)
malloc(sizeof(struct node));
TAIL=(struct node *)
malloc(sizeof(struct node));
HEAD->NEXT=TAIL;
TAIL->NEXT=HEAD;
}](https://image.slidesharecdn.com/cv0vlctbkk3astree1tw-signature-d9097abeae3fc5501630373cf3f9db62dd763c144c2d0bbd0568a6cb132602fe-poli-160427173638/85/Linked-list-96-320.jpg)