Downloaded 12 times













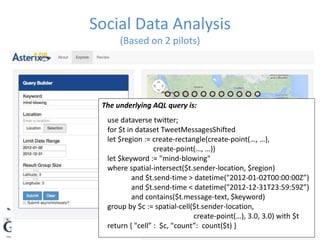
![create dataverse TinySocial;
use dataverse TinySocial;
create type MugshotUserType as {
id: int32,
alias: string,
name: string,
user-since: datetime,
address: {
street: string,
city: string,
state: string,
zip: string,
country: string
},
friend-ids: {{ int32 }},
employment: [EmploymentType]
}
ASTERIX Data Model (ADM)
13
create dataset MugshotUsers(MugshotUserType)
primary key id;
Highlights include:
• JSON++ based data model
• Rich type support (spatial, temporal, …)
• Records, lists, bags
• Open vs. closed types
create type EmploymentType as open {
organization-name: string,
start-date: date,
end-date: date?
}](https://image.slidesharecdn.com/chenli-asterixdb-160616080628/85/Chen-li-asterix-db-14-320.jpg)
![create dataverse TinySocial;
use dataverse TinySocial;
create type MugshotUserType as {
id: int32,
alias: string,
name: string,
user-since: datetime,
address: {
street: string,
city: string,
state: string,
zip: string,
country: string
},
friend-ids: {{ int32 }},
employment: [EmploymentType]
}
create dataverse TinySocial;
use dataverse TinySocial;
create type MugshotUserType as {
id: int32
}
ASTERIX Data Model (ADM)
14
create dataset MugshotUsers(MugshotUserType)
primary key id;
Highlights include:
• JSON++ based data model
• Rich type support (spatial, temporal, …)
• Records, lists, bags
• Open vs. closed types
create type EmploymentType as open {
organization-name: string,
start-date: date,
end-date: date?
}](https://image.slidesharecdn.com/chenli-asterixdb-160616080628/85/Chen-li-asterix-db-15-320.jpg)
![create dataverse TinySocial;
use dataverse TinySocial;
create type MugshotUserType as {
id: int32,
alias: string,
name: string,
user-since: datetime,
address: {
street: string,
city: string,
state: string,
zip: string,
country: string
},
friend-ids: {{ int32 }},
employment: [EmploymentType]
}
create dataverse TinySocial;
use dataverse TinySocial;
create type MugshotUserType as {
id: int32
}
create type MugshotMessageType
as closed {
message-id: int32,
author-id: int32,
timestamp: datetime,
in-response-to: int32?,
sender-location: point?,
tags: {{ string }},
message: string
}
ASTERIX Data Model (ADM)
15
create dataset MugshotUsers(MugshotUserType)
primary key id;
create dataset
MugshotMessages(MugshotMessageType)
primary key message-id;
Highlights include:
• JSON++ based data model
• Rich type support (spatial, temporal, …)
• Records, lists, bags
• Open vs. closed types
create type EmploymentType as open {
organization-name: string,
start-date: date,
end-date: date?
}](https://image.slidesharecdn.com/chenli-asterixdb-160616080628/85/Chen-li-asterix-db-16-320.jpg)
![16
{ "id":1, "alias":"Margarita", "name":"MargaritaStoddard", "address”:{
"street":"234 Thomas Ave", "city":"San Hugo", "zip":"98765",
"state":"CA", "country":"USA" }
"user-since":datetime("2012-08-20T10:10:00"),
"friend-ids":{{ 2, 3, 6, 10 }}, "employment":[{
"organization-name":"Codetechno”, "start-date":date("2006-08-06") }] }
{ "id":2, "alias":"Isbel", "name":"IsbelDull", "address":{
"street":"345 James Ave", "city":"San Hugo", "zip":"98765”,
"state":"CA", "country":"USA" },
"user-since":datetime("2011-01-22T10:10:00"),
"friend-ids":{{ 1, 4 }}, "employment":[{
"organization-name":"Hexviafind”, "start-date":date("2010-04-27") }] }
{ "id":3, "alias":"Emory", "name":"EmoryUnk", "address":{
"street":"456 Jose Ave", "city":"San Hugo", "zip":"98765",
"state":"CA", "country":"USA" },
"user-since”: datetime("2012-07-10T10:10:00"),
"friend-ids":{{ 1, 5, 8, 9 }}, "employment”:[{
"organization-name":"geomedia”,
"start-date":date("2010-06-17"), "end-date":date("2010-01-26") }] }
...
Ex: MugshotUsers Data](https://image.slidesharecdn.com/chenli-asterixdb-160616080628/85/Chen-li-asterix-db-17-320.jpg)




![Updates (and Transactions)
21
• Key-value store-
like transaction
semantics
• Insert/delete ops
with indexing
• Concurrency
control (locking)
• Crash recovery
• Backup/restore
• Ex: Add a new user to Mugshot.com:
insert into dataset MugshotUsers
( {
"id":11, "alias":"John", "name":"JohnDoe",
"address":{
"street":"789 Jane St", "city":"San Harry",
"zip":"98767", "state":"CA", "country":"USA"
},
"user-since":datetime("2010-08-15T08:10:00"),
"friend-ids":{ { 5, 9, 11 } },
"employment":[{
"organization-name":"Kongreen",
"start-date":date("20012-06-05")
}] } );](https://image.slidesharecdn.com/chenli-asterixdb-160616080628/85/Chen-li-asterix-db-22-320.jpg)




![LSM-Based Filters
Memory
Disk
T1, T2, T3,
T4, T5, T6
T7, T8, T9,
T10, T11
T12, T13,
T14, T15
T16, T17
Oldest Component
[ T12, T15 ] [ T7, T11 ] [ T1, T6 ]
Intuition: Do NOT touch unneeded records
Idea: Utilize LSM partitioning to prune disk components
Q: Get all tweets > T14
26](https://image.slidesharecdn.com/chenli-asterixdb-160616080628/85/Chen-li-asterix-db-27-320.jpg)





AsterixDB is an open source "Big Data Management System" (BDMS) that provides flexible data modeling, efficient query processing, and scalable analytics on large datasets. It uses a native storage layer built on LSM trees with indexing and transaction support. The Asterix Data Model (ADM) supports semistructured data types like records, lists, and bags. Queries are written in the Asterix Query Language (AQL) which supports features like spatial and temporal predicates. AsterixDB is being used for applications like social network analysis, education analytics, and more.

































































































