Downloaded 27 times










![14
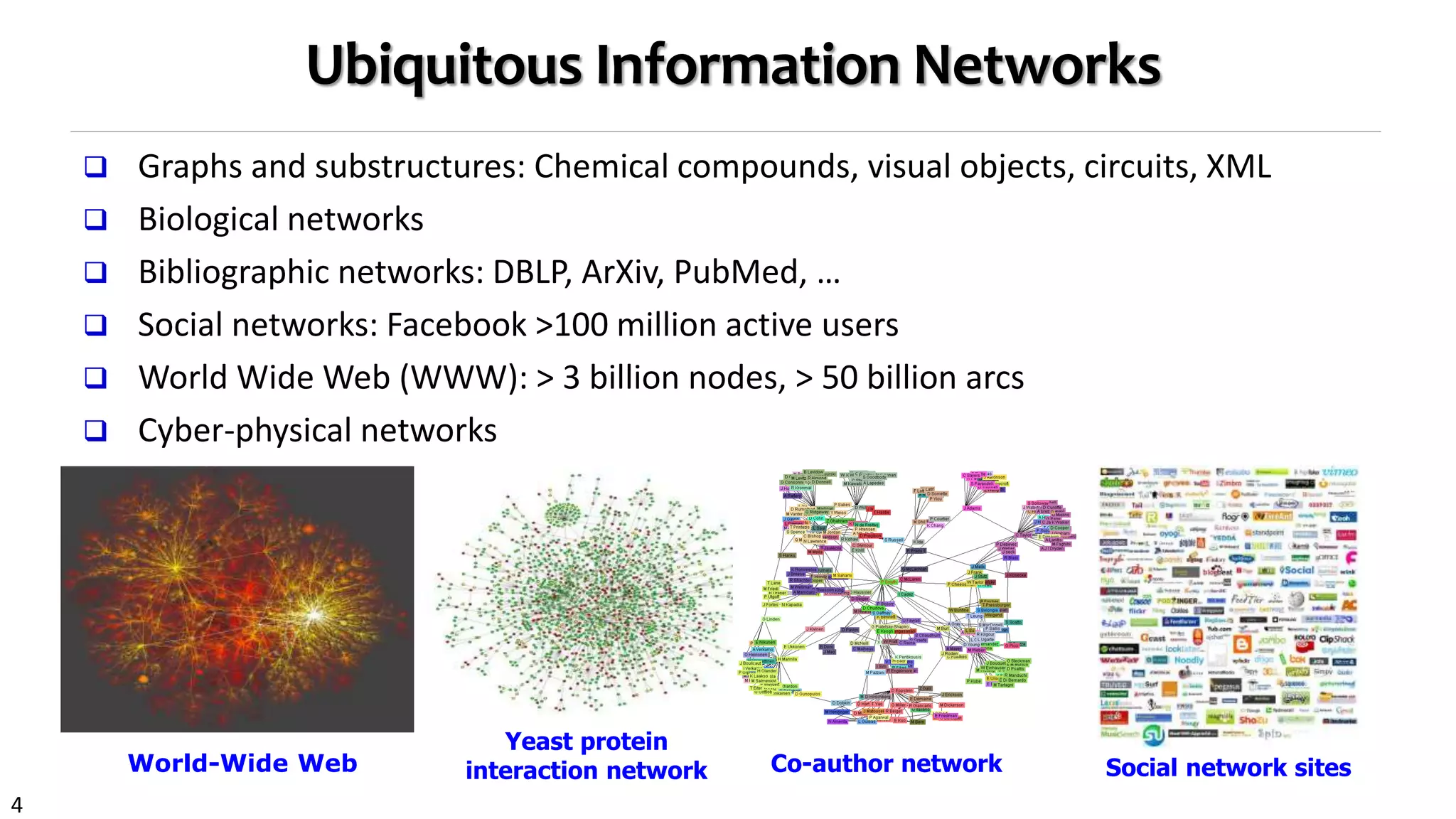
Ranking-Based Clustering in Heterogeneous Networks
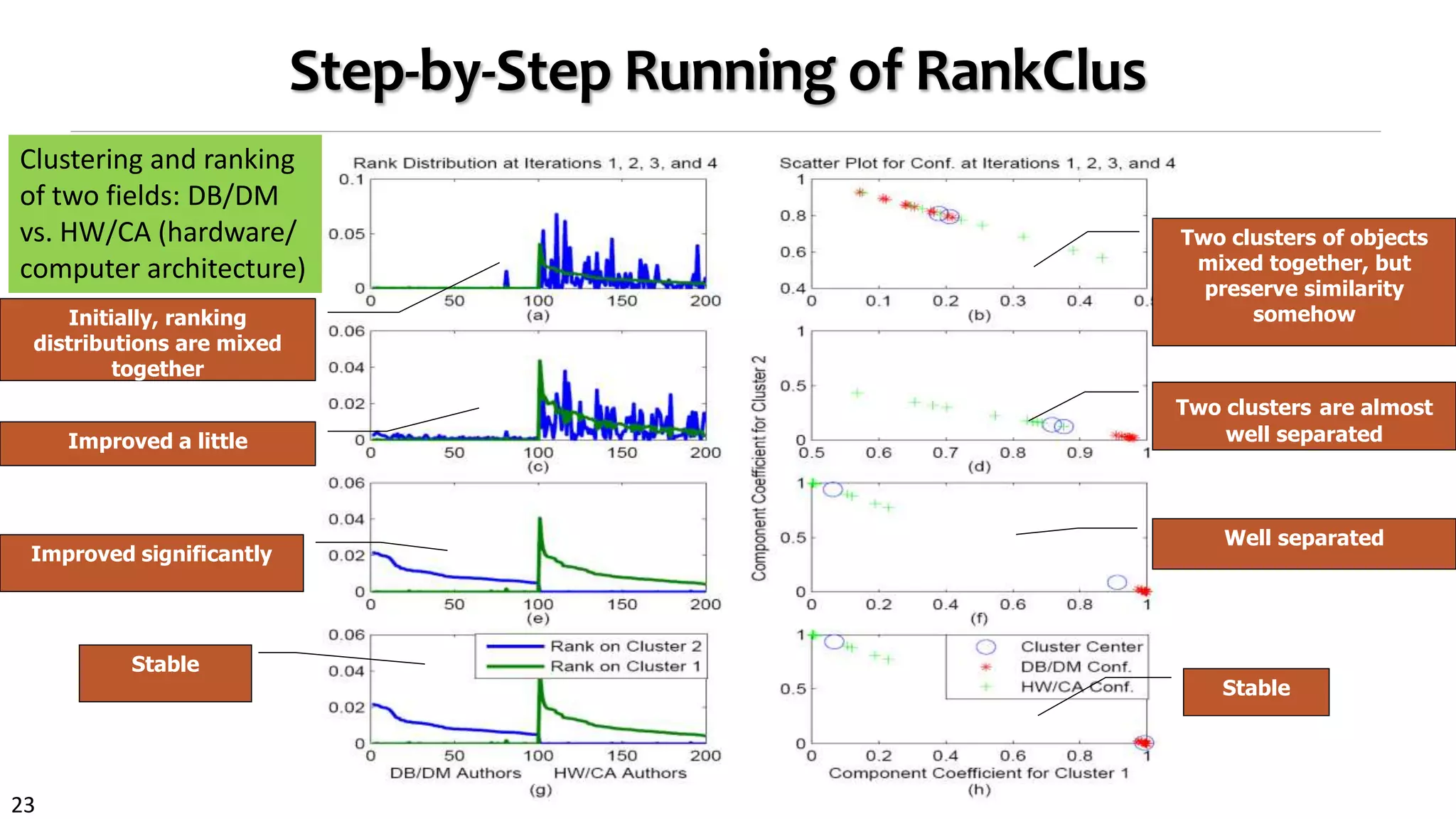
Clustering and ranking: Two critical functions in data mining
Clustering without ranking? Think about no PageRank dark time before Google
Ranking will make more sense within a particular cluster
Einstein in physics vs. Turing in computer science
Why not integrate ranking with clustering & classification?
High-ranked objects should be more important in a cluster than low-ranked ones
Why treat every object the same weight in the same cluster?
But how to get their weight?
Integrate ranking with clustering/classification in the same process
Ranking, as the feature, is conditional (i.e., relative) to a specific cluster
Ranking and clustering may mutually enhance each other
Ranking-based clustering: RankClus [EDBT’09], NetClus [KDD’09]](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-14-2048.jpg)






![22
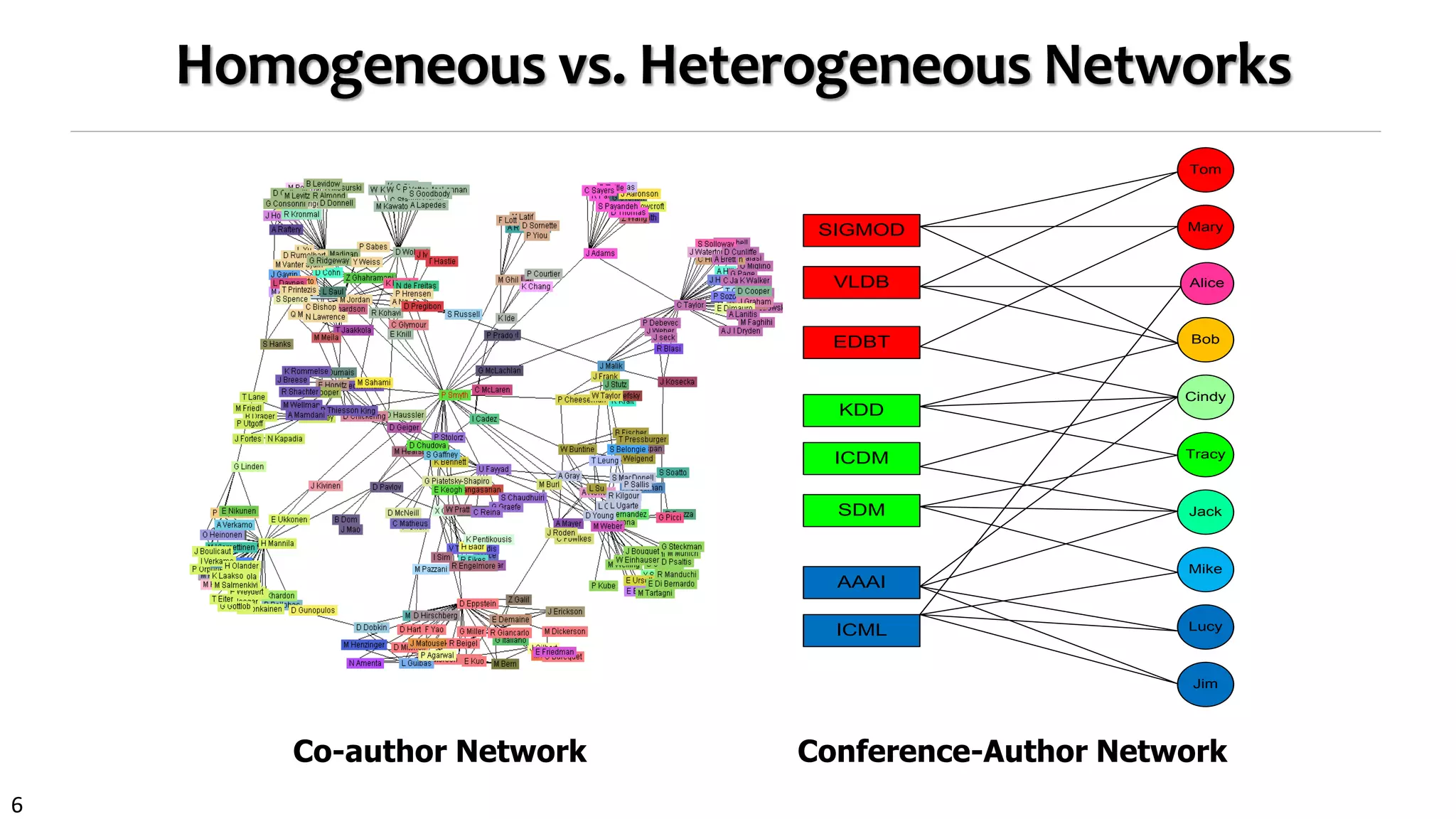
RankClus: Integrating Clustering with Ranking
An EM styled Algorithm
Initialization
Randomly partition
Repeat
Ranking
Ranking objects in each sub-
network induced from each cluster
Generating new measure space
Estimate mixture model
coefficients for each target object
Adjusting cluster
Until change < threshold
SIGMOD
SDM
ICDM
KDD
EDBT
VLDB
ICML
AAAI
Tom
Jim
Lucy
Mike
Jack
Tracy
Cindy
Bob
Mary
Alice
SIGMOD
VLDB
EDBT
KDDICDM
SDM
AAAI
ICML
Objects
Ranking
Sub-Network
Ranking
Clustering
RankClus [EDBT’09]: Ranking and clustering mutually
enhancing each other in an E-M framework
An E-M framework for iterative enhancement](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-22-2048.jpg)


![27
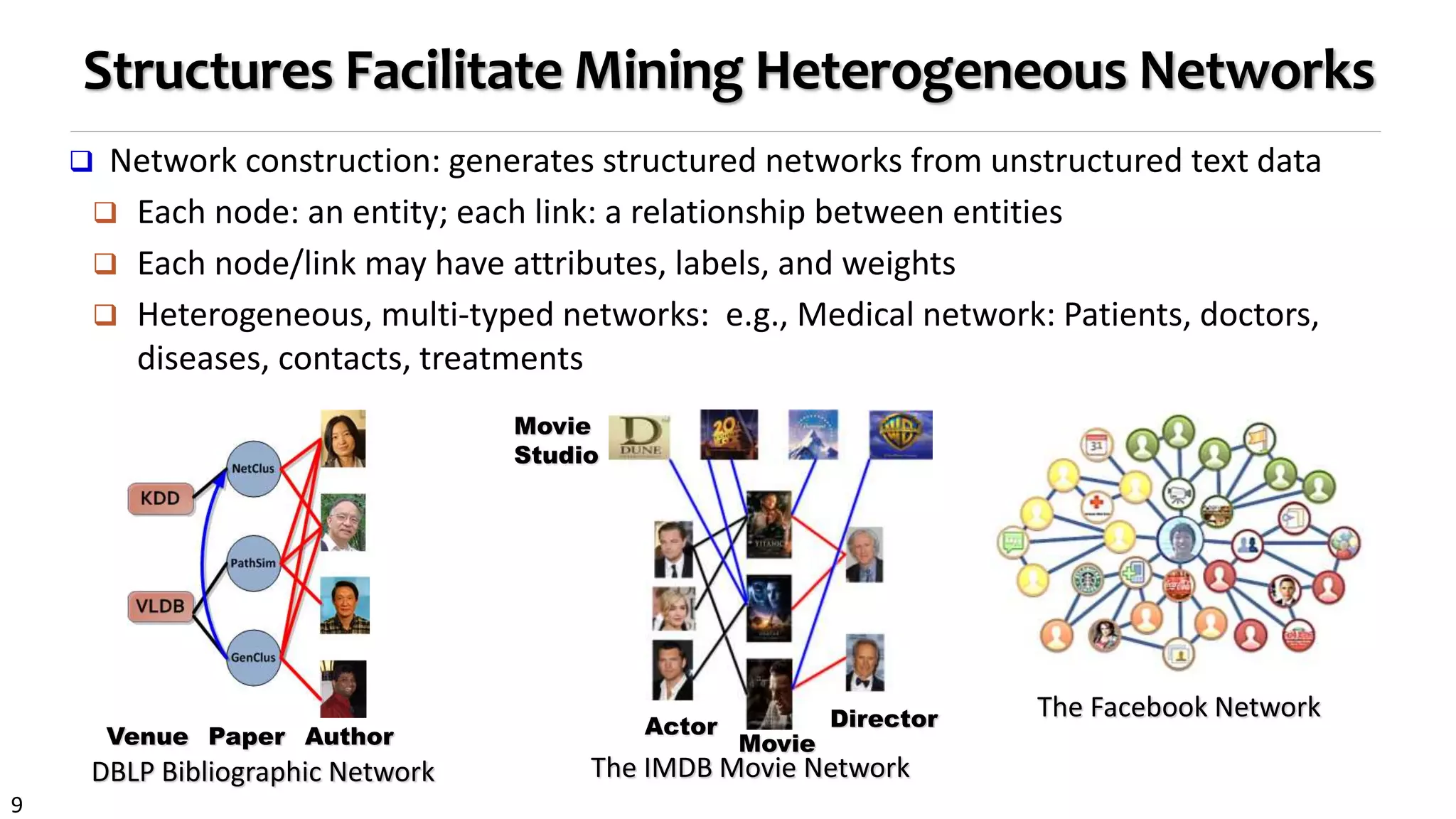
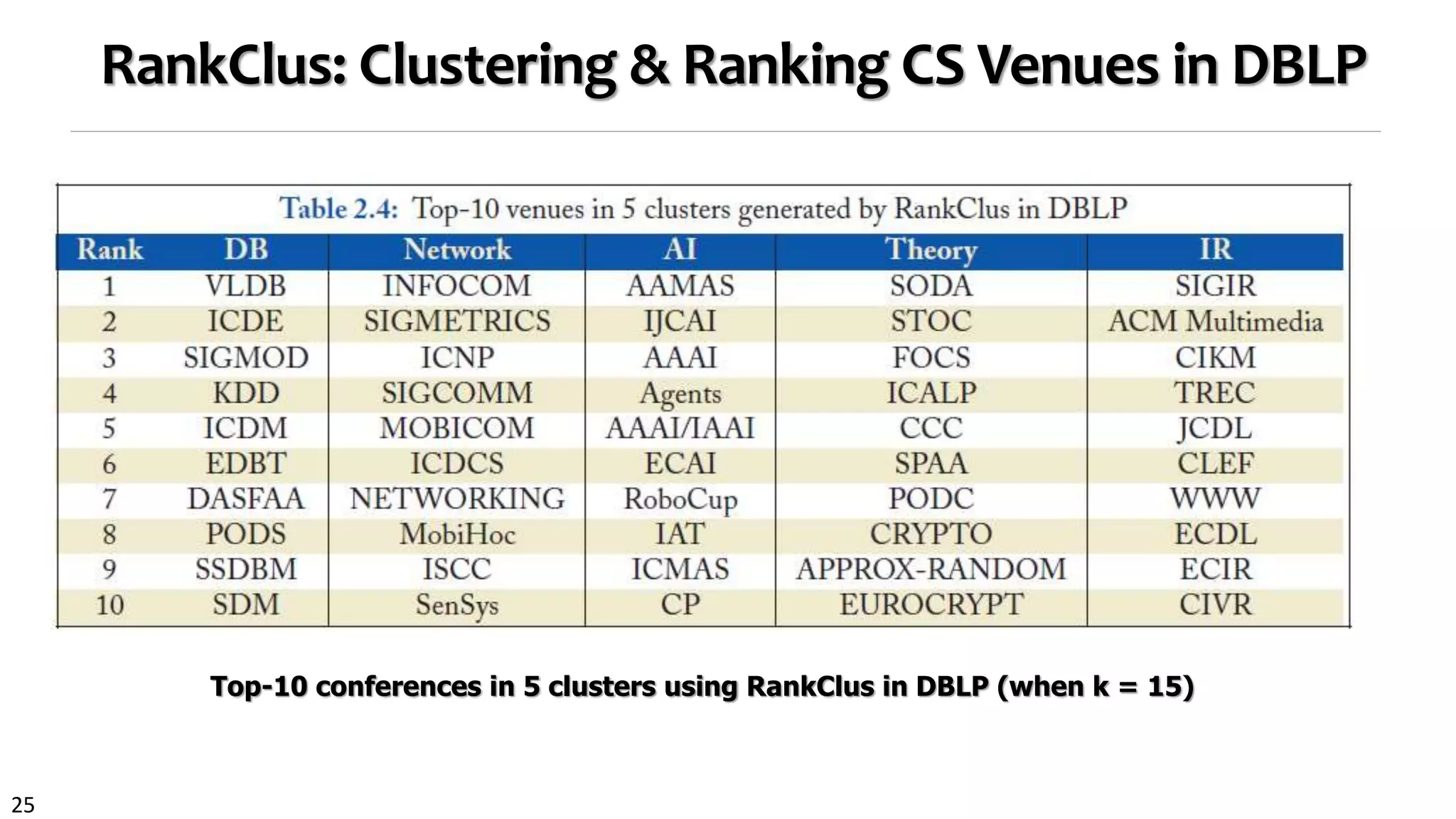
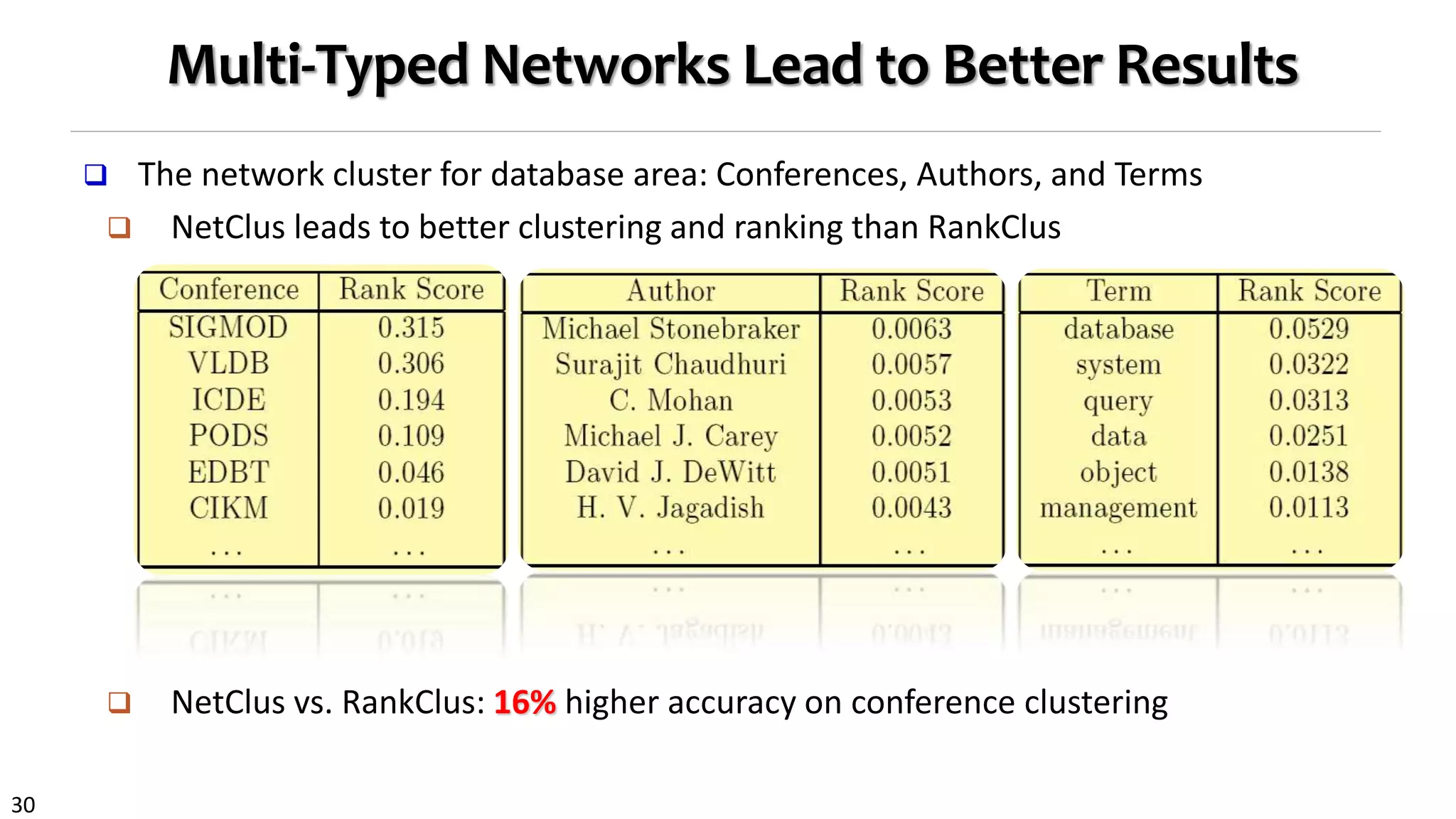
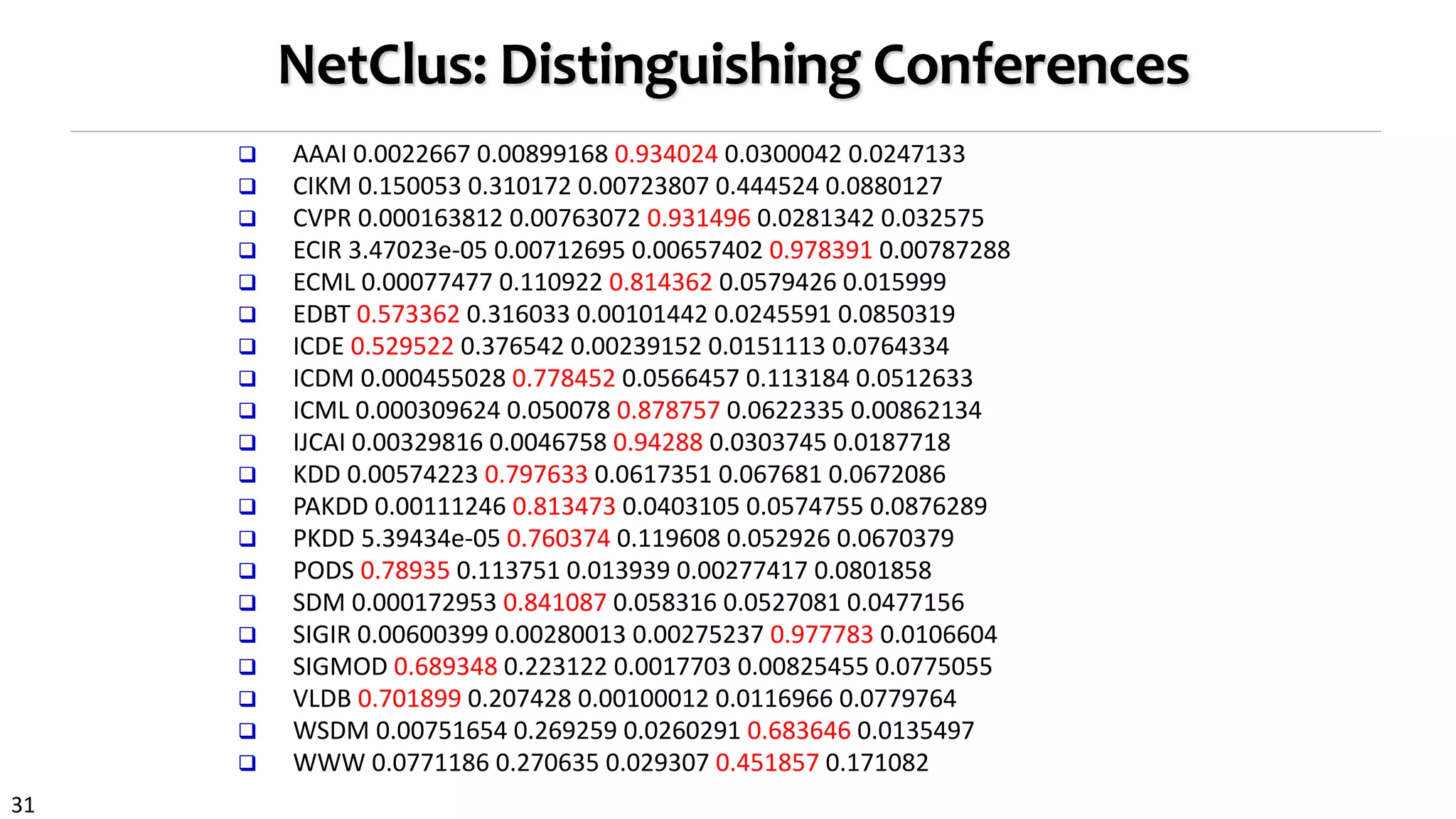
NetClus: Ranking-Based Clustering with Star Network Schema
Beyond bi-typed network: Capture more semantics with multiple types
Split a network into multi-subnetworks, each a (multi-typed) net-cluster [KDD’09]
Research
Paper
Term
AuthorVenue
Publish Write
Contain
P
T
AV
P
T
AV
……
P
T
AV
NetClus
Computer Science
Database
Hardware
Theory
DBLP network: Using terms, venues, and authors
to jointly distinguish a sub-field, e.g., database](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-27-2048.jpg)





![35
Impact of RankClus Methodology
RankCompete [Cao et al., WWW’10]
Extend to the domain of web images
RankClus in Medical Literature [Li et al., Working paper]
Ranking treatments for diseases
RankClass [Ji et al., KDD’11]
Integrate classification with ranking
Trustworthy Analysis [Gupta et al., WWW’11] [Khac Le et al., IPSN’11]
Integrate clustering with trustworthiness score
Topic Modeling in Heterogeneous Networks [Deng et al., KDD’11]
Propagate topic information among different types of objects
…](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-35-2048.jpg)


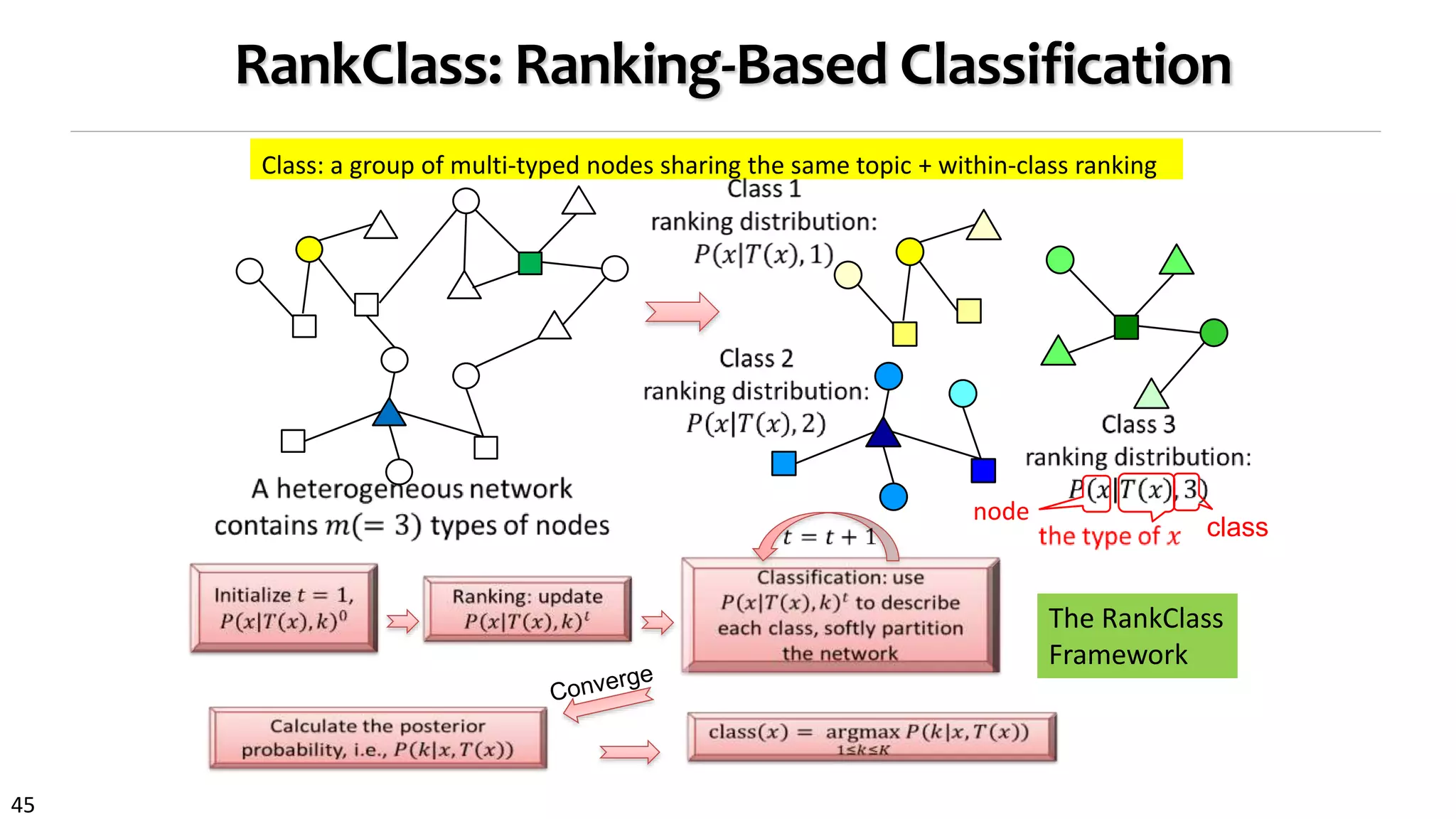
![38
Classification: Knowledge Propagation Across
Heterogeneous Typed Networks
RankClass [Ji et al., KDD’11]:
Ranking-based classification
Highly ranked objects will
play more role in
classification
Class membership and
ranking are statistical
distributions
Let ranking and
classification mutually
enhance each other!
Output: Classification
results + ranking list of
objects within each class
Classification: Labeled knowledge propagates through multi-typed
objects across heterogeneous networks [KDD’11]](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-38-2048.jpg)

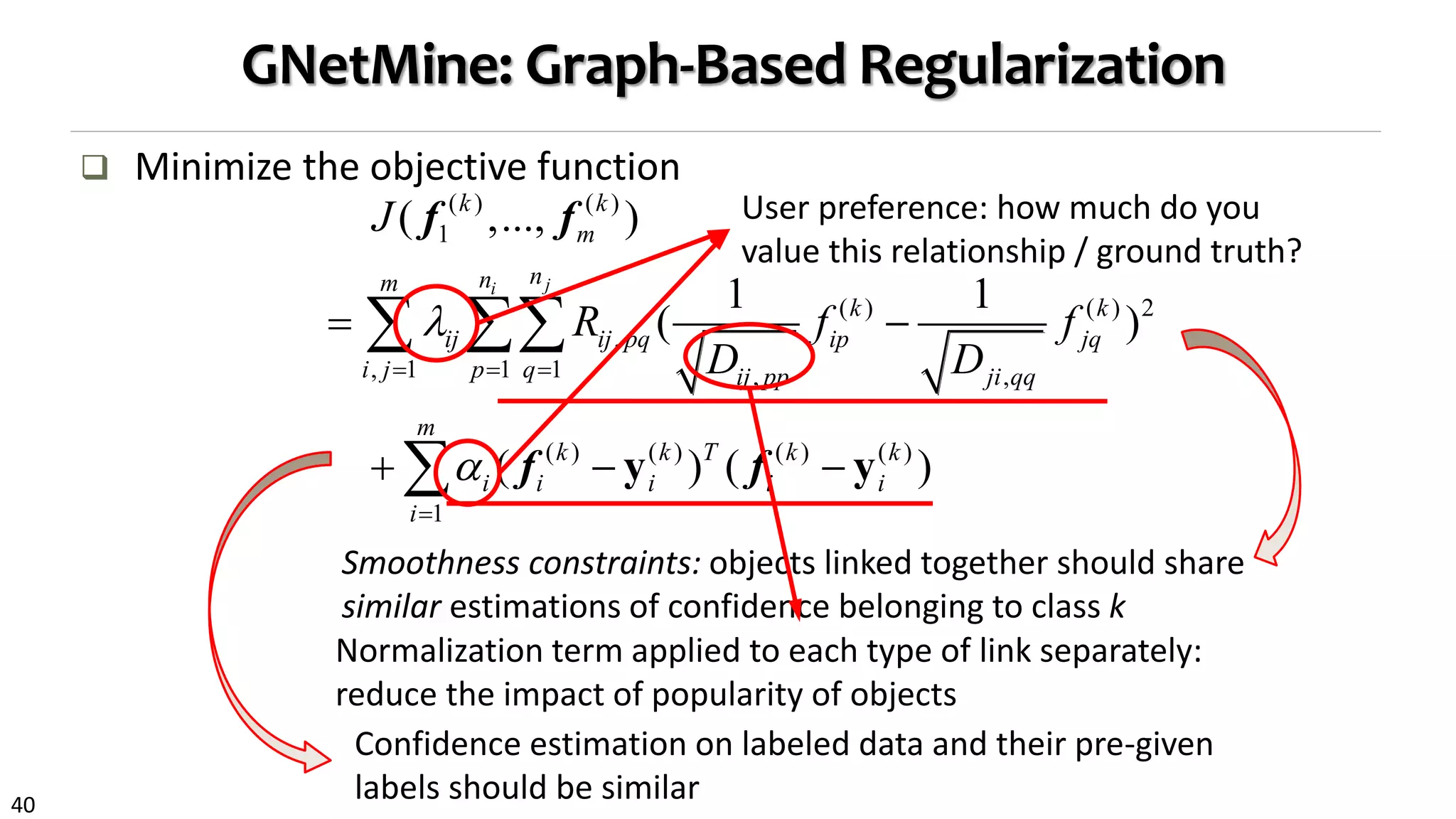
![41
RankClass: Ranking-Based Classification
Classification in heterogeneous networks
Knowledge propagation: Class label knowledge propagated across multi-typed
objects through a heterogeneous network
GNetMine [Ji et al., PKDD’10]: Objects are treated equally
RankClass [Ji et al., KDD’11]: Ranking-based classification
Highly ranked objects will play more role in classification
An object can only be ranked high in some focused classes
Class membership and ranking are stat. distributions
Let ranking and classification mutually enhance each other!
Output: Classification results + ranking list of objects within each class](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-41-2048.jpg)
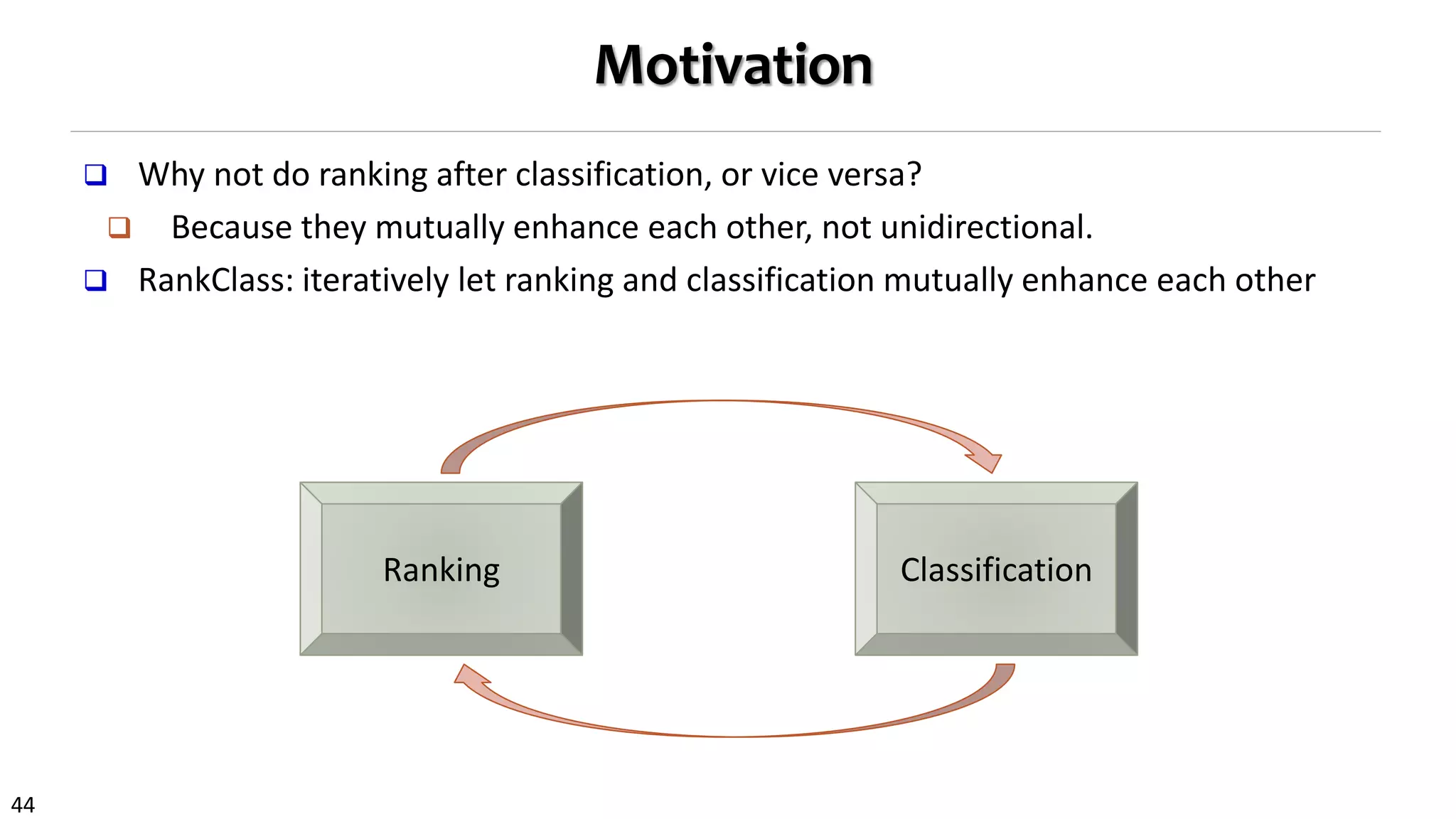
![42
From RankClus to GNetMine & RankClass
RankClus [EDBT’09]: Clustering and ranking working together
No training, no available class labels, no expert knowledge
GNetMine [PKDD’10]: Incorp. label information in networks
Classification in heterog. networks, but objects treated equally
RankClass [KDD’11]: Integration of ranking and classification in heterogeneous
network analysis
Ranking: informative understanding & summary of each class
Class membership is critical information when ranking objects
Let ranking and classification mutually enhance each other!
Output: Classification results + ranking list of objects within each class](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-42-2048.jpg)
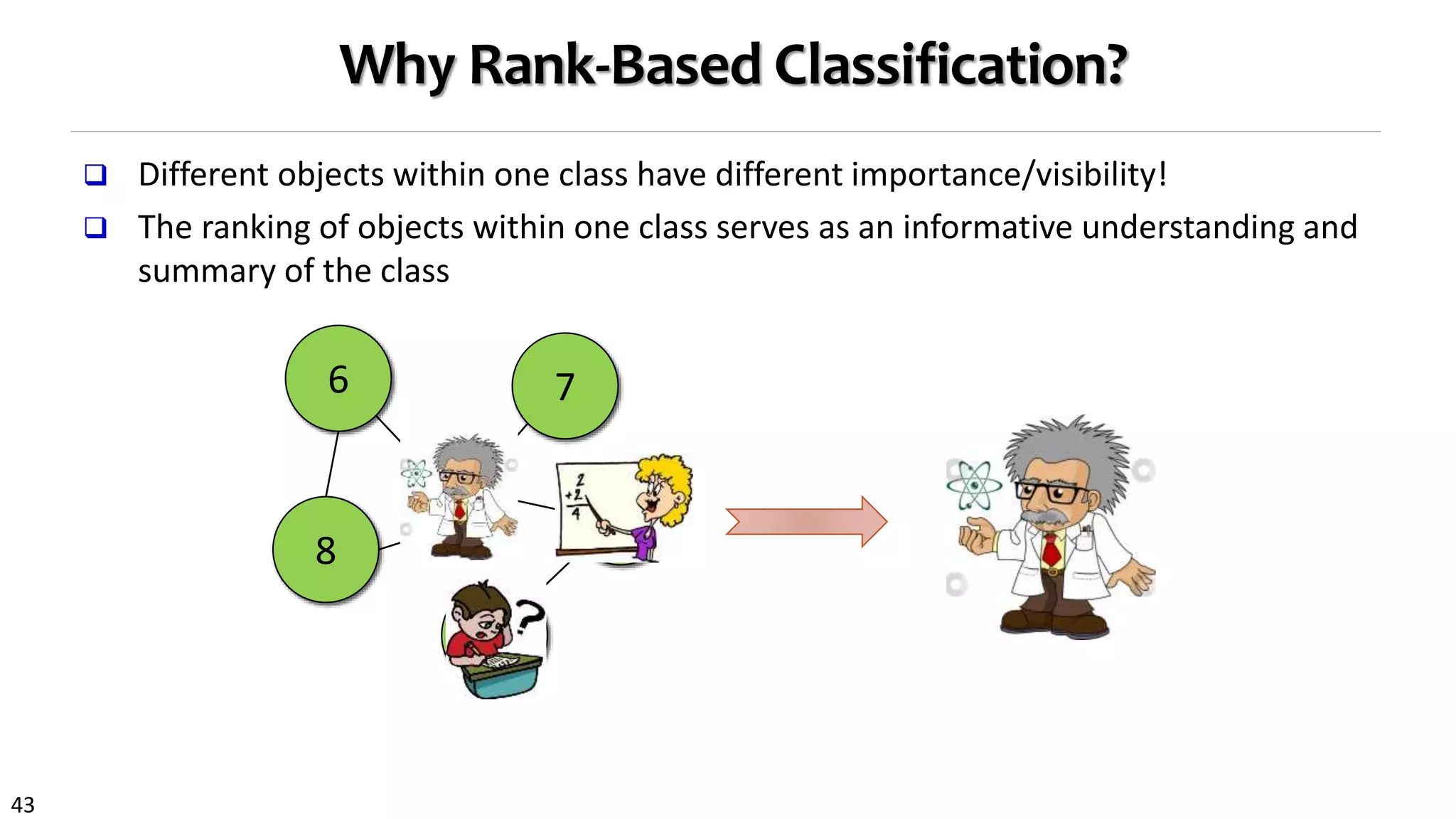
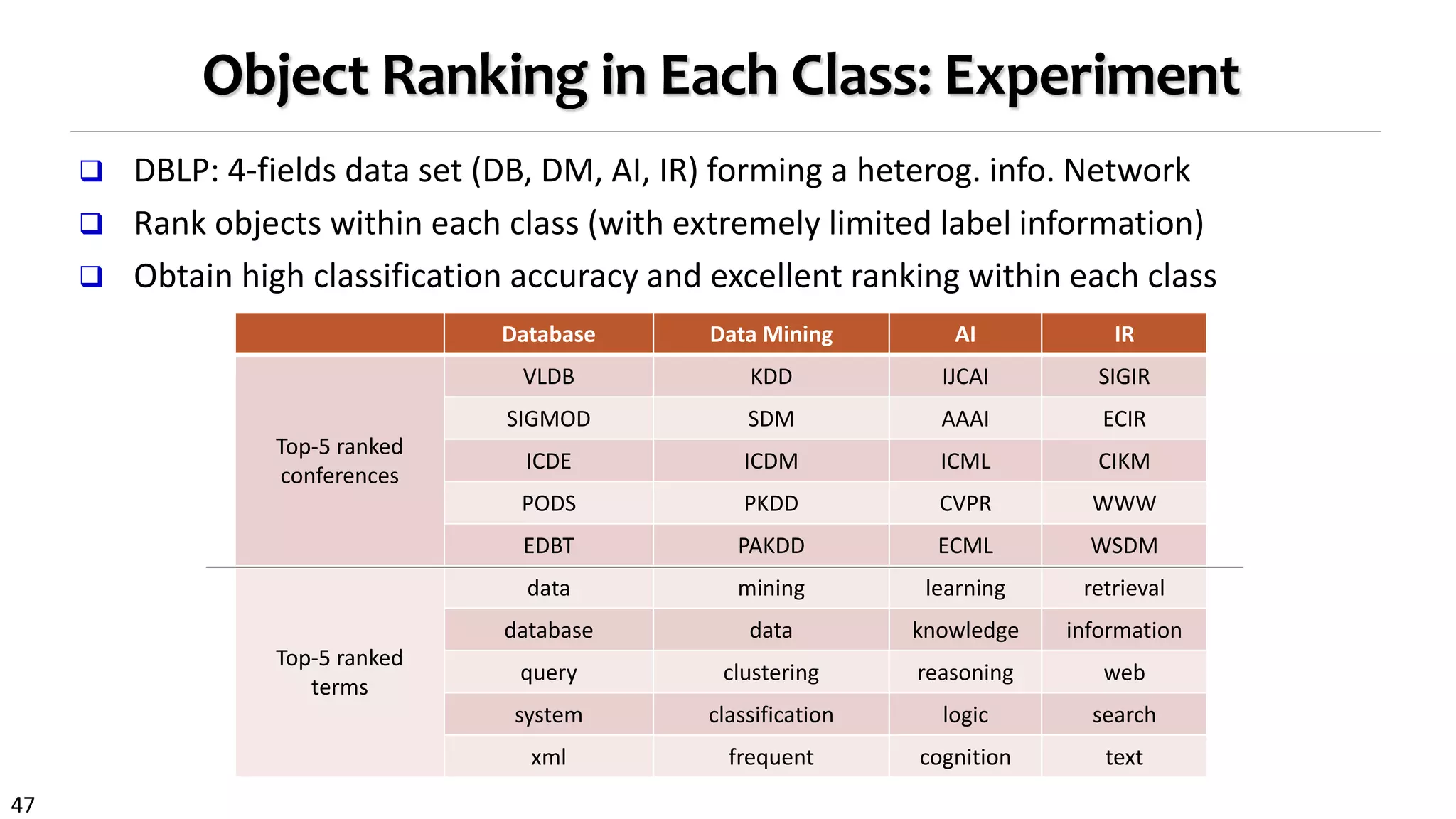
![46
Comparing Classification Accuracy on the DBLP Data
Class: Four research areas:
DB, DM, AI, IR
Four types of objects
Paper(14376), Conf.(20),
Author(14475),
Term(8920)
Three types of relations
Paper-conf., paper-
author, paper-term
Algorithms for comparison
LLGC [Zhou et al. NIPS’03]
wvRN) [Macskassy et al.
JMLR’07]
nLB [Lu et al. ICML’03,
Macskassy et al.
JMLR’07]](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-46-2048.jpg)







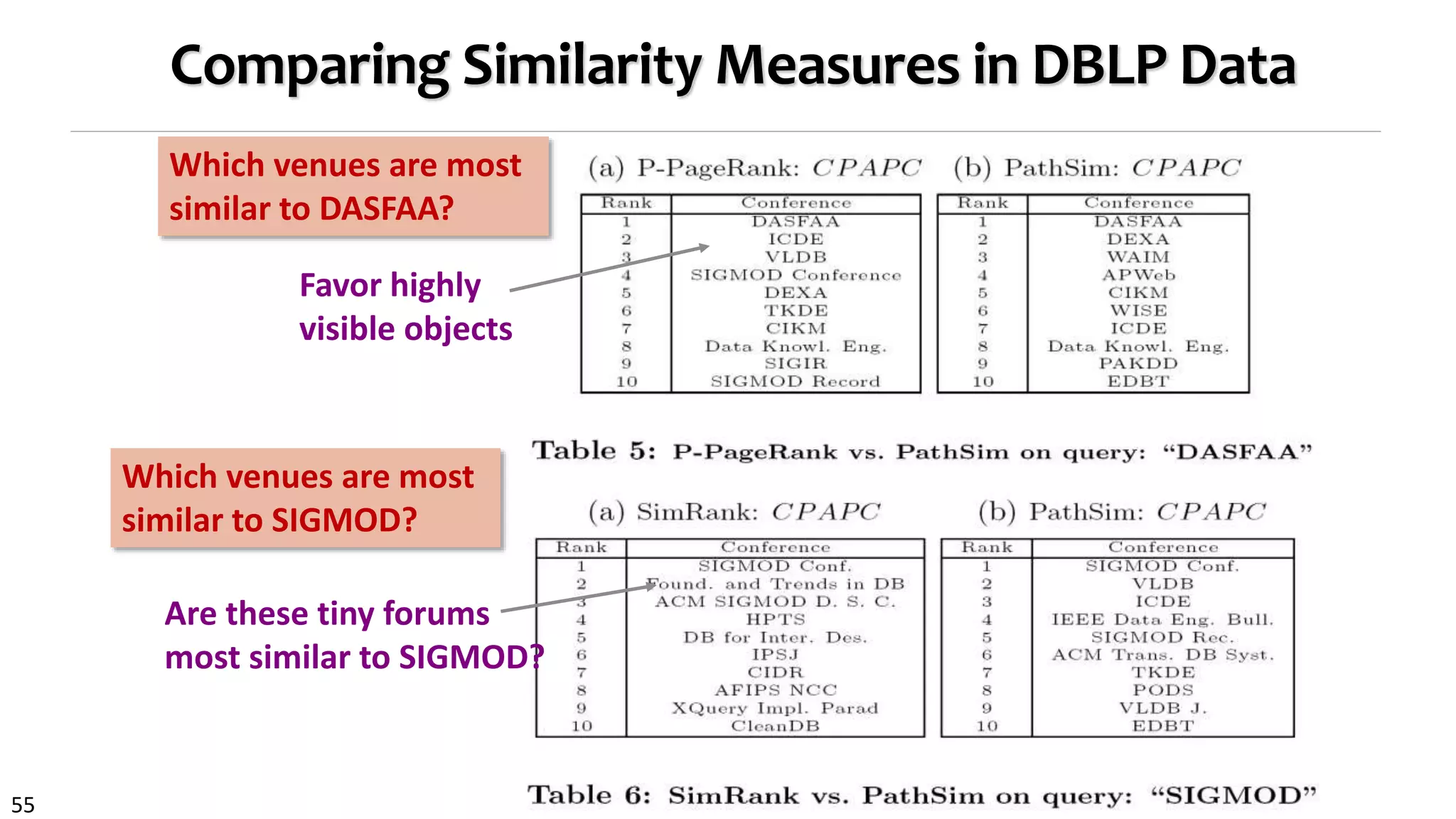
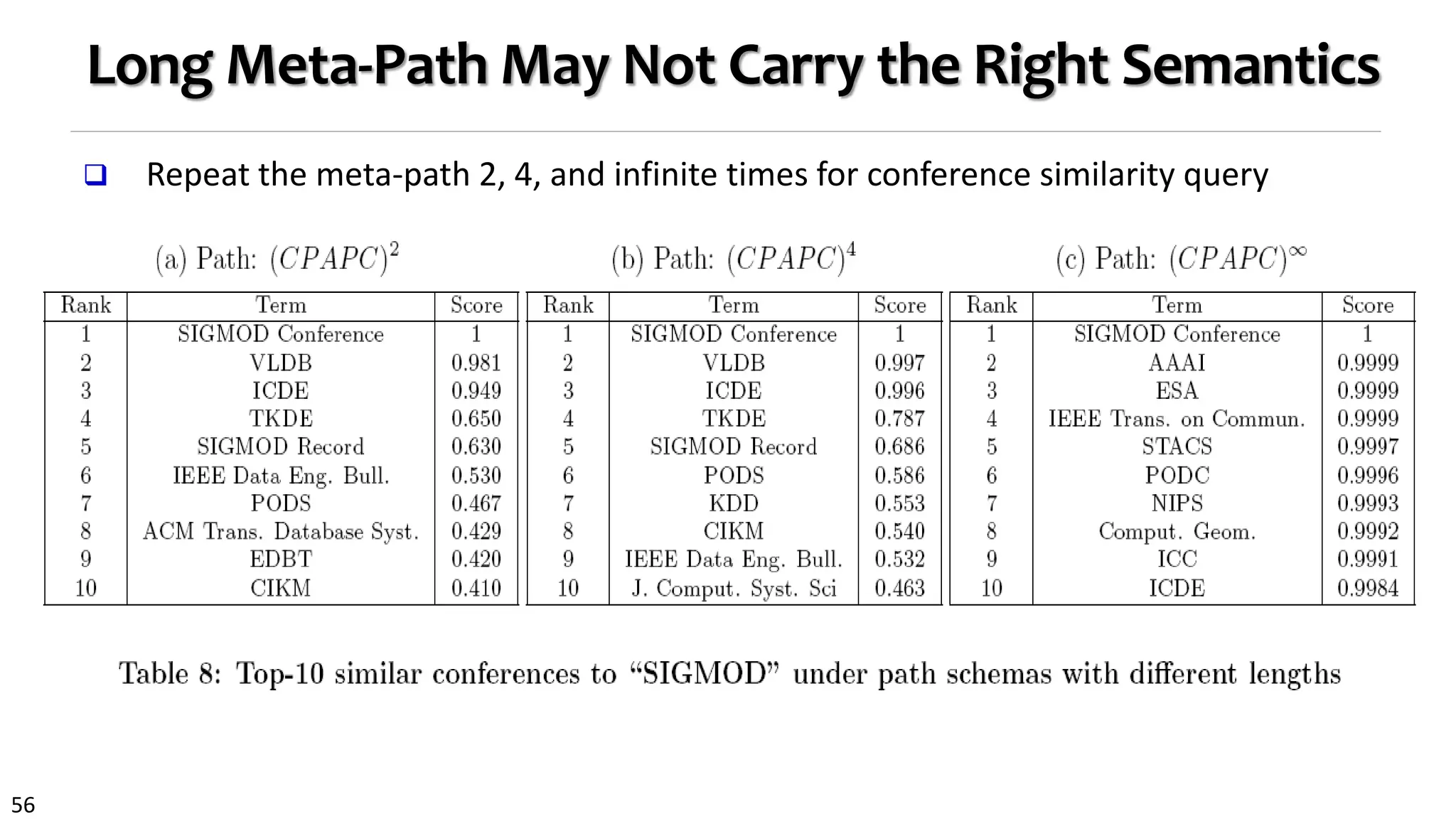
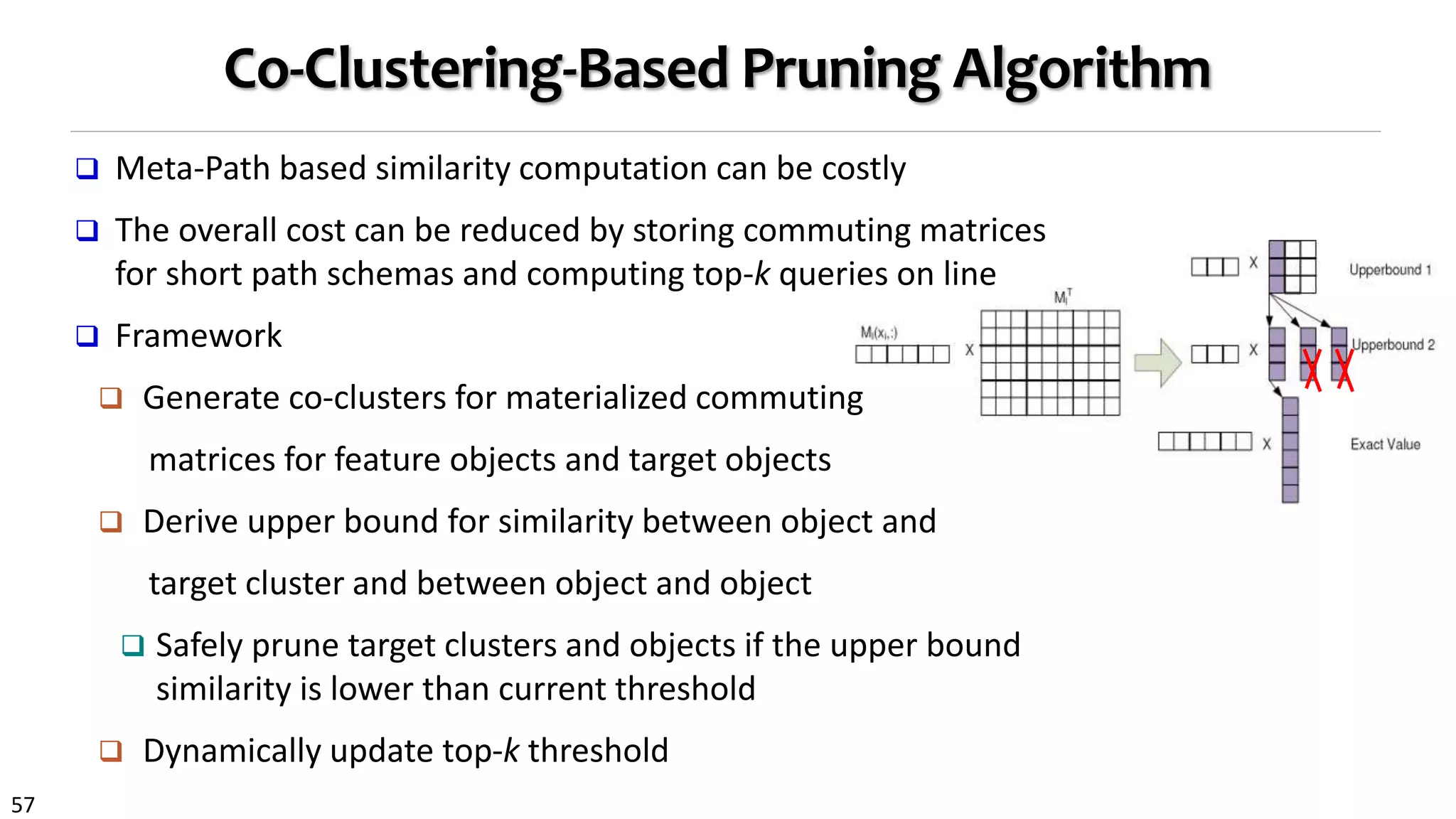
![58
Meta-Path: A Key Concept for Heterogeneous Networks
Meta-path based mining
PathPredict [Sun et al., ASONAM’11]
Co-authorship prediction using meta-path based similarity
PathPredict_when [Sun et al., WSDM’12]
When a relationship will happen
Citation prediction [Yu et al., SDM’12]
Meta-path + topic
Meta-path learning
User Guided Meta-Path Selection [Sun et al., KDD’12]
Meta-path selection + clustering](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-58-2048.jpg)


![61
Relationship Prediction vs. Link Prediction
Link prediction in homogeneous networks [Liben-Nowell and Kleinberg, 2003,
Hasan et al., 2006]
E.g., friendship prediction
Relationship prediction in heterogeneous networks
Different types of relationships need different prediction models
Different connection paths need to be treated separately!
Meta-path-based approach to define topological features
vs.
vs.](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-61-2048.jpg)

![63
PathPredict: Meta-Path Based Relationship Prediction
Who will be your new coauthors in the next 5 years?
Meta path-guided prediction of links and relationships
Philosophy: Meta path relationships among similar typed links share
similar semantics and are comparable and inferable
Co-author prediction (A—P—A) [Sun et al., ASONAM’11]
Use topological features encoded by meta paths, e.g., citation
relations between authors (A—P→P—A)
vs.
Meta-paths
between
authors of
length ≤ 4
Meta-
Path
Semantic
Meaning](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-63-2048.jpg)


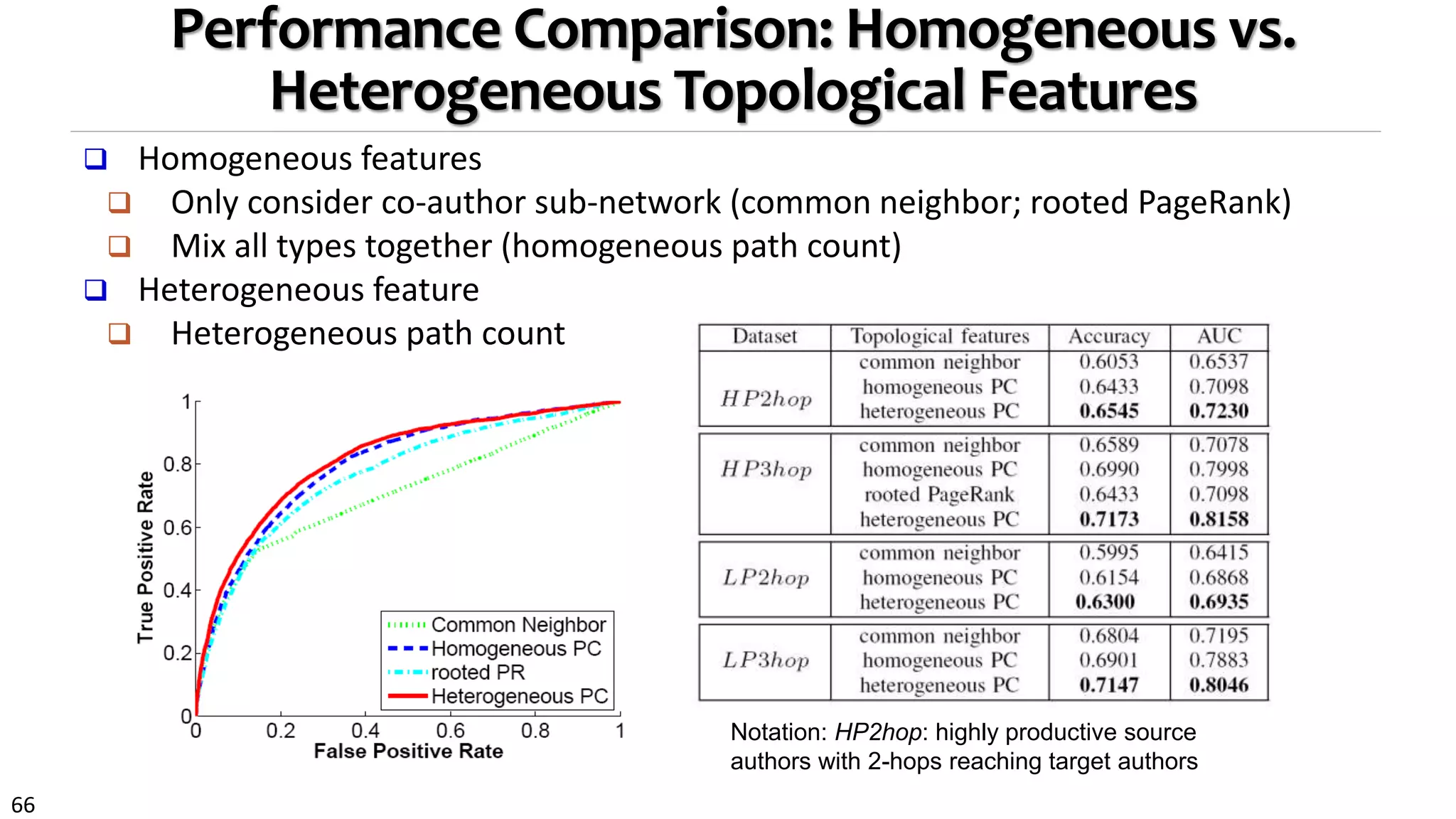
![68
The Power of PathPredict: Experiment on DBLP
Explain the prediction power of
each meta-path
Wald Test for logistic
regression
Higher prediction accuracy than
using projected homogeneous
network
11% higher in prediction
accuracy
Co-author prediction for Jian Pei: Only 42 among 4809
candidates are true first-time co-authors!
(Feature collected in [1996, 2002]; Test period in [2003,2009])](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-68-2048.jpg)
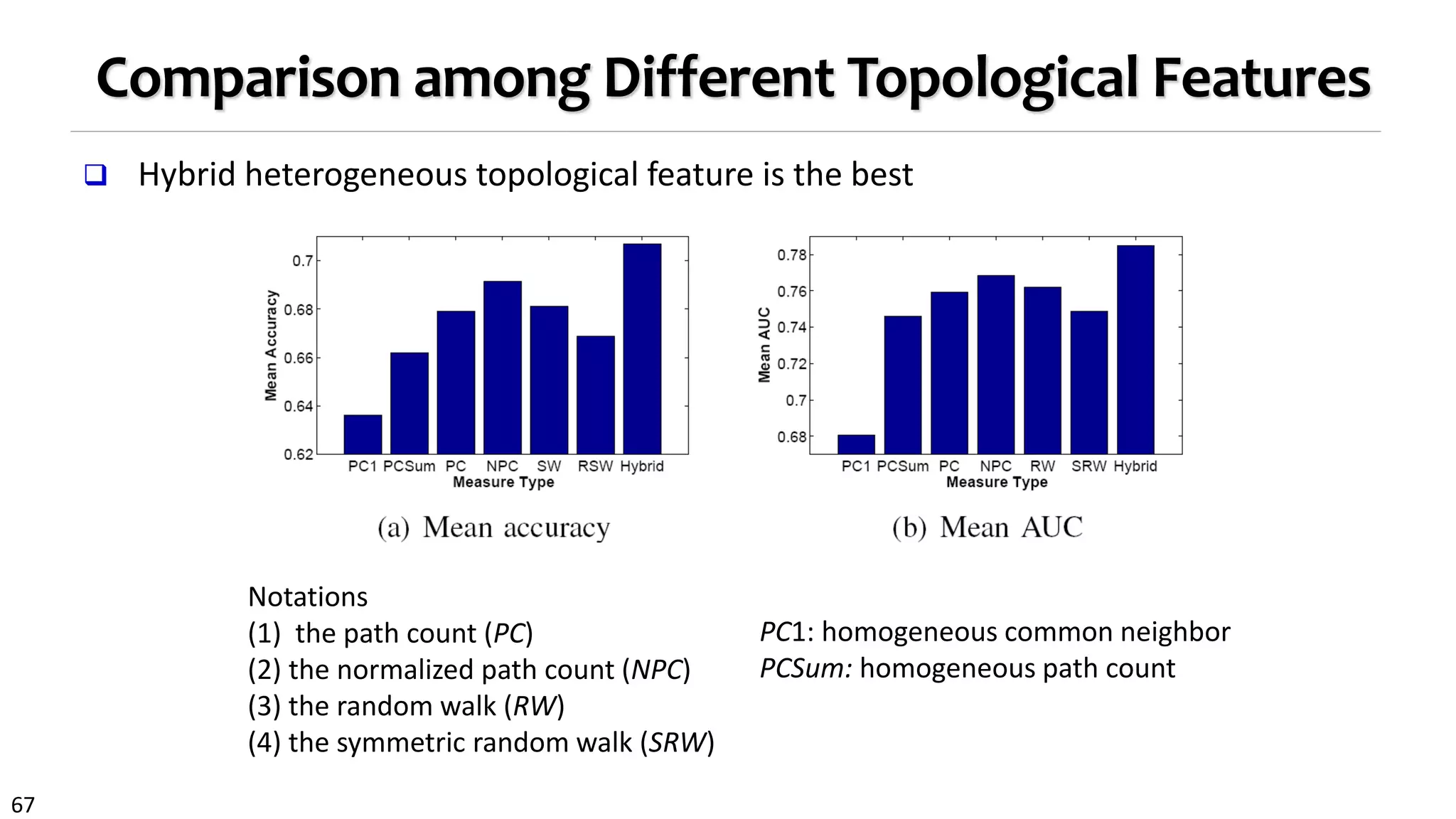
![69
The Power of PathPredict: Experiment on DBLP
Explain the prediction power of each
meta-path
Wald Test for logistic regression
Higher prediction accuracy than using
projected homogeneous network
11% higher in prediction accuracy
Co-author prediction for Jian Pei: Only 42 among 4809
candidates are true first-time co-authors!
(Feature collected in [1996, 2002]; Test period in [2003,2009])
Evaluation of the prediction
power of different meta-paths
Prediction of new coauthors
of Jian Pei in [2003-2009]
Social relations
play more
important role?](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-69-2048.jpg)





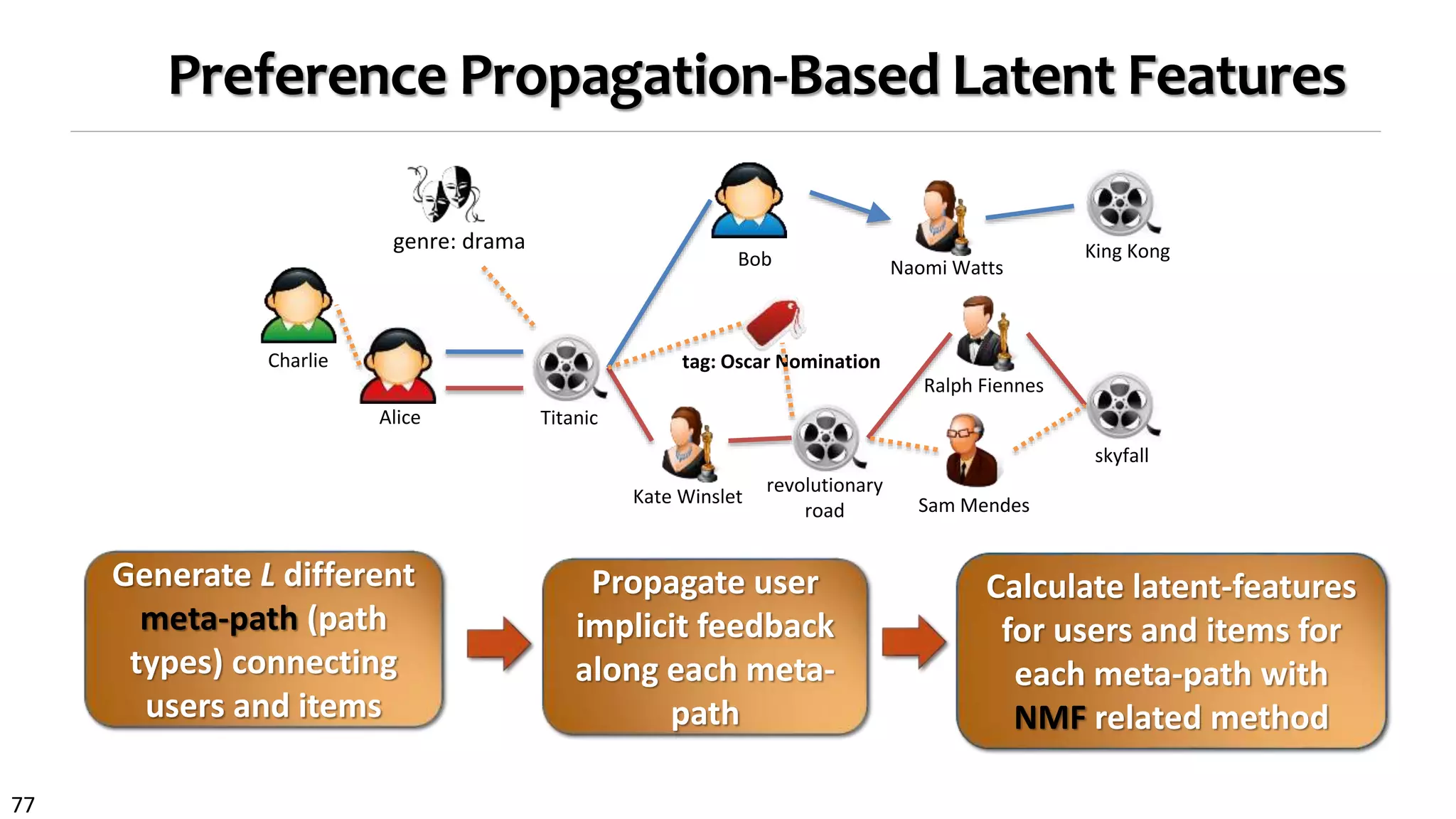
![75
Enhancing the Power of Recommender Systems by Heterog.
Info. Network Analysis
Heterogeneous relationships complement each other
Users and items with limited feedback can be connected to the network by
different types of paths
Connect new users or items in the information network
Different users may require different models: Relationship heterogeneity makes
personalized recommendation models easier to define
Avatar TitanicAliens Revolutionary
Road
James
Cameron
Kate
Winslet
Leonardo
Dicaprio
Zoe
Saldana
Adventure
Romance
Collaborative filtering methods suffer from
the data sparsity issue
# of users or items
A small set
of users &
items have a
large number
of ratings
Most users & items have a
small number of ratings
#ofratings
Personalized recommendation with heterog.
Networks [WSDM’14]](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-75-2048.jpg)








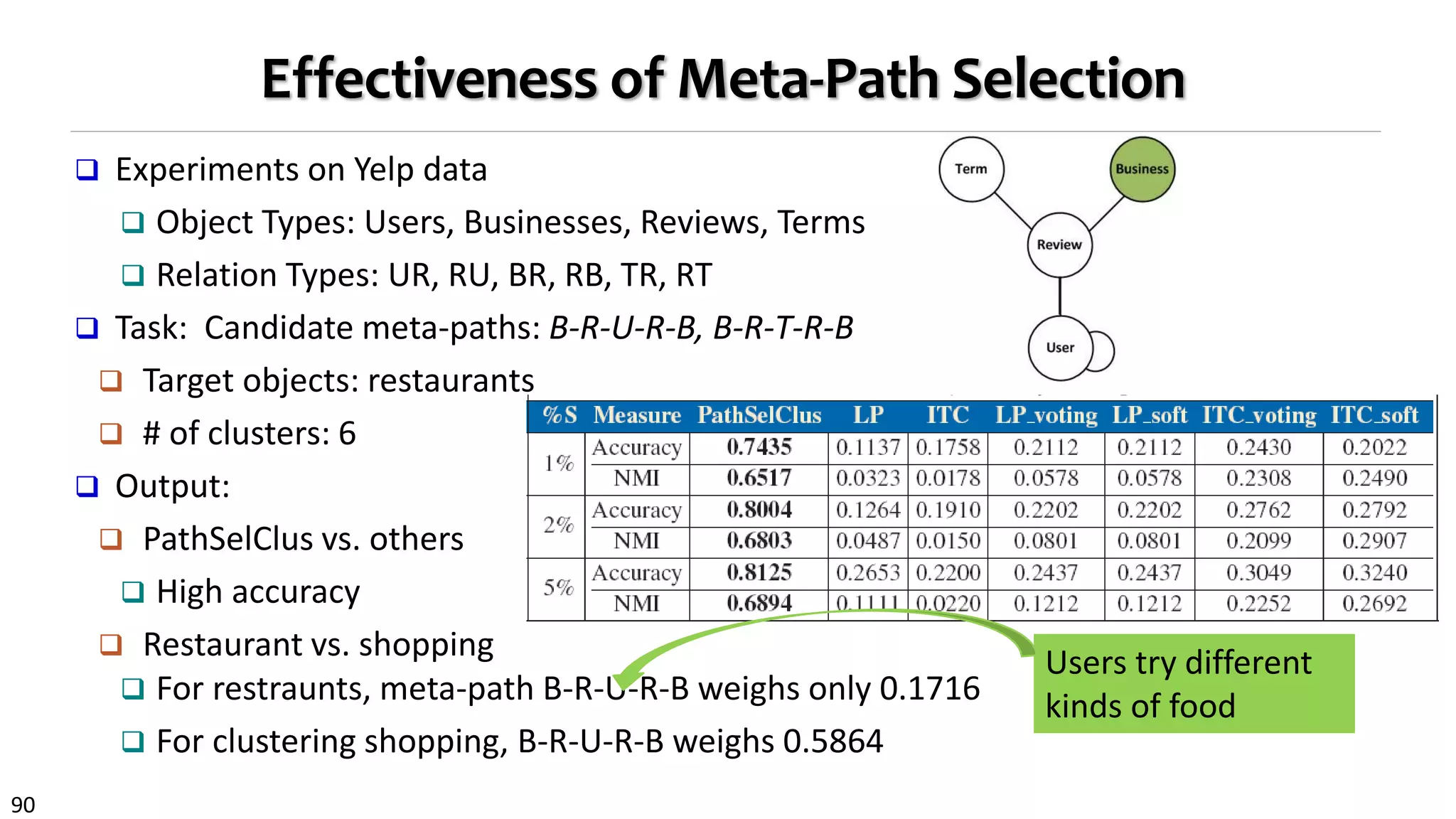




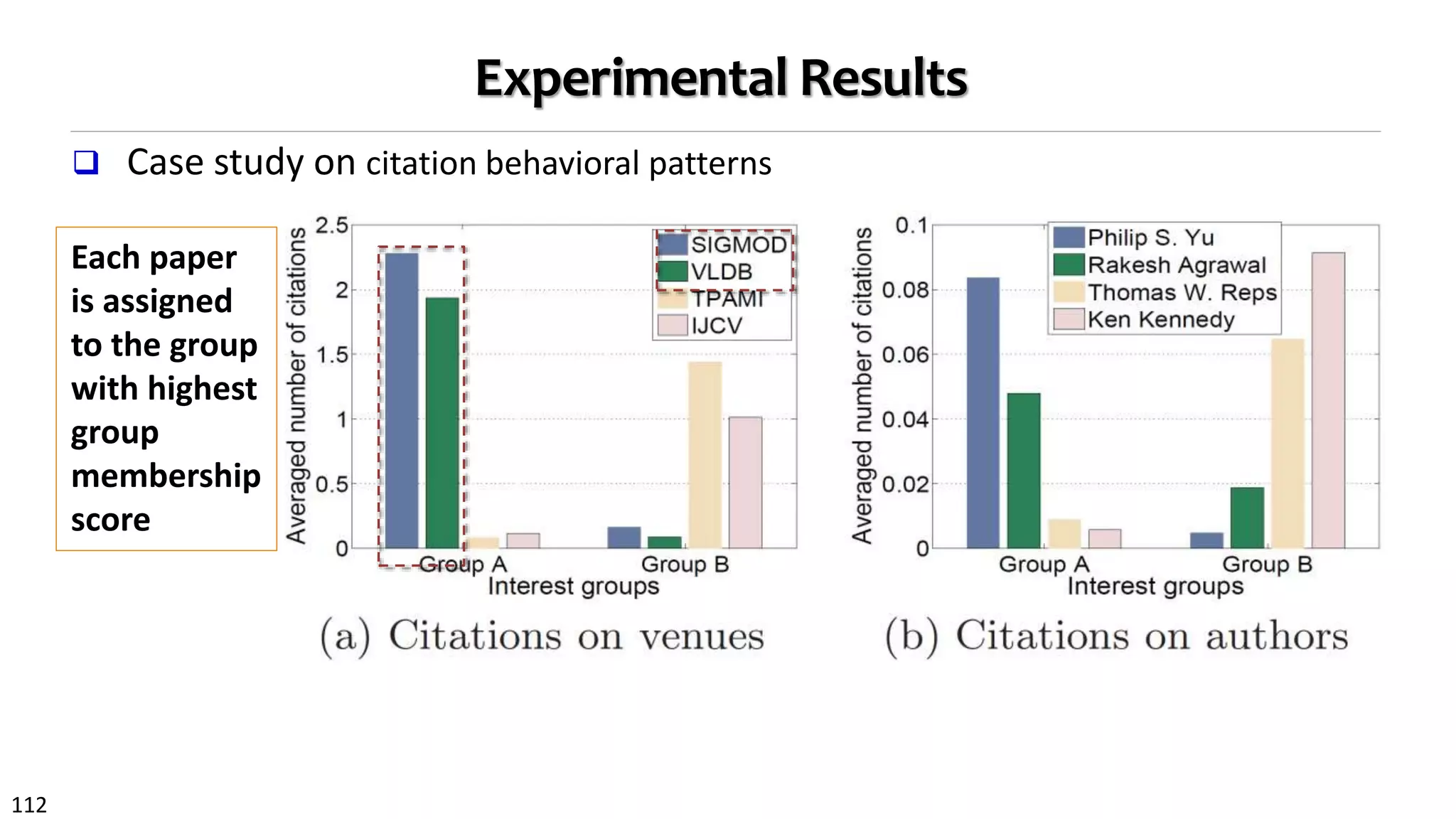
![95
Consider Distinct Citation Behavioral Patterns
Basic idea: Paper’s citations can be organized into different groups, each
having its own behavioral pattern to identify references of interest
A principled way to capture paper’s citation behaviors
More accurate approach:paper-specific recommendation model
Most existing studies: assume all papers adopt same criterion and follow
same behavioral pattern in citing other papers:
Context-based [He et al., WWW’10; Huang et al., CIKM’12]
Topical similarity-based [Nallapati et al., KDD’08; Tang et al., PAKDD’09]
Structural similarity-based [Liben-Nowell et al., CIKM’03; Strohman et al.,
SIGIR’07]
Hybrid methods [Bethard et al., CIKM’10; Yu et al., SDM’12]](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-95-2048.jpg)

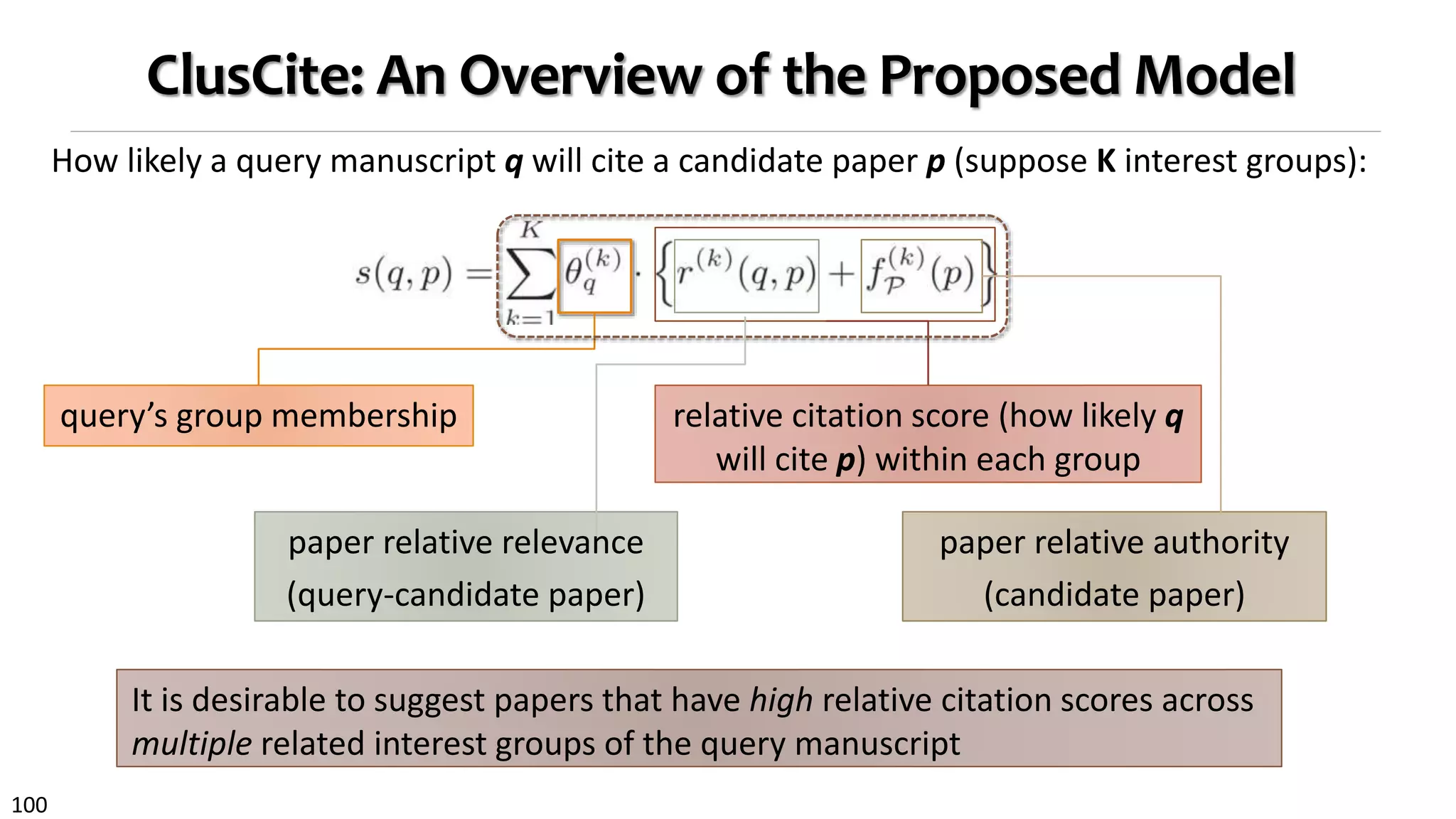


![105
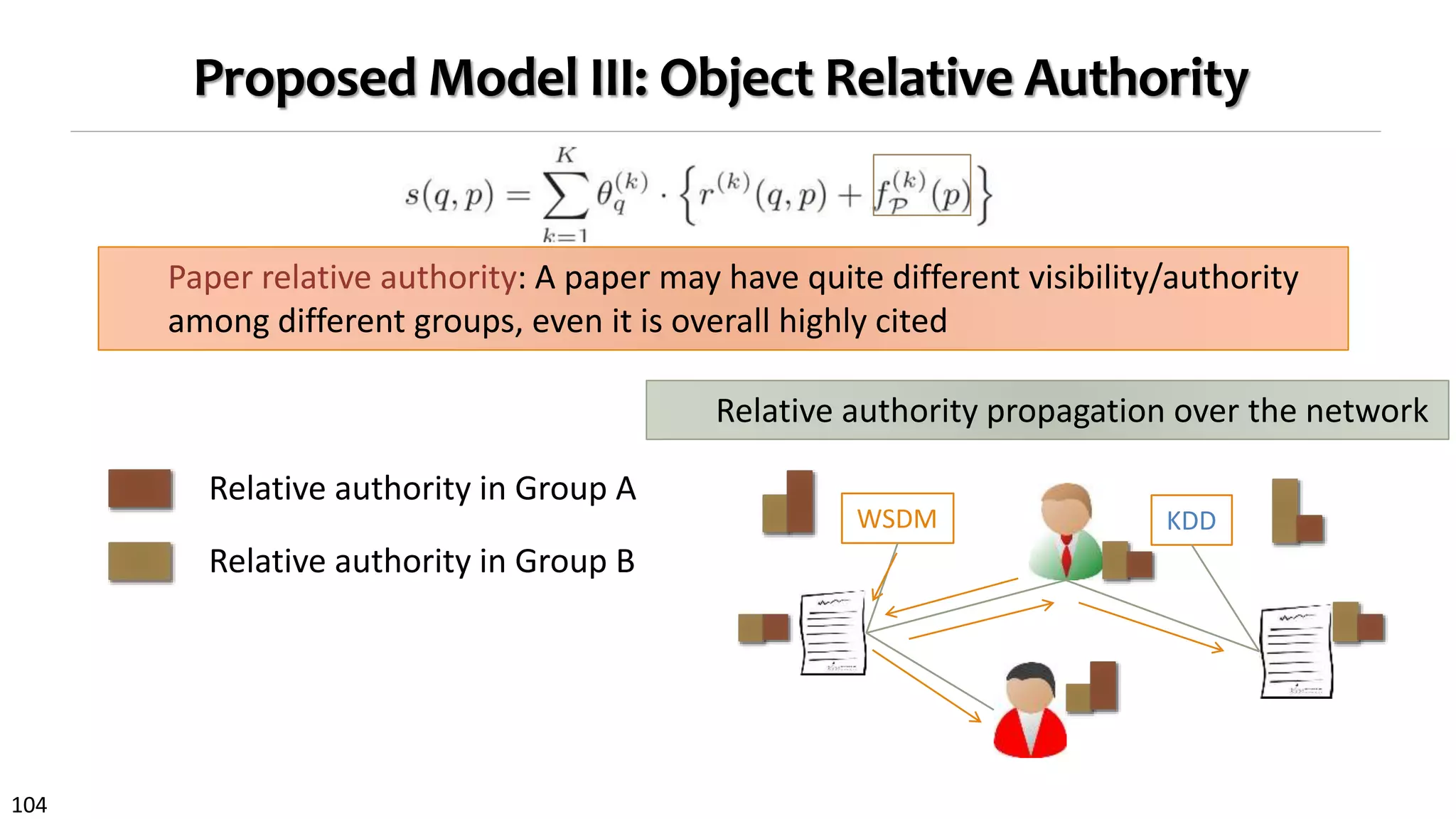
Proposed Model III: Object Relative Authority
Paper relative authority: A paper may have quite different visibility/authority
among different groups, even it is overall highly cited
and pa-
putes the
oup. The
final rec-
mbership
sent how
groups.
ce
of meta
der vari-
re, could
different
ong with
ated pa-
because
d ICDM)
riving relative authority separately, we propose to estimate
them jointly using graph regularization, which preservescon-
sistency over each subgraph. By doing so, paper relative
authority serves as a feature for learning interest groups,
and better estimated groups can in turn help derive relative
authority more accurately (Fig. 3).
We adopt the semi-supervised learning framework [8] that
leads to iteratively updating rules as authority propagation
between different types of objects.
FP = GP FP , FA , FV ; λA , λV ,
FA = GA FP and FV = GV FP . (3)
We denote relative authority score matrices for paper, au-
thor and venue objects by FP ∈ RK × n
, FA ∈ RK × |A | and
FV ∈ RK × |V | . Generally, in an interest group, relative im-
portance of one type of object could be a combination of the
relative importance from different types of objects [23].](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-105-2048.jpg)
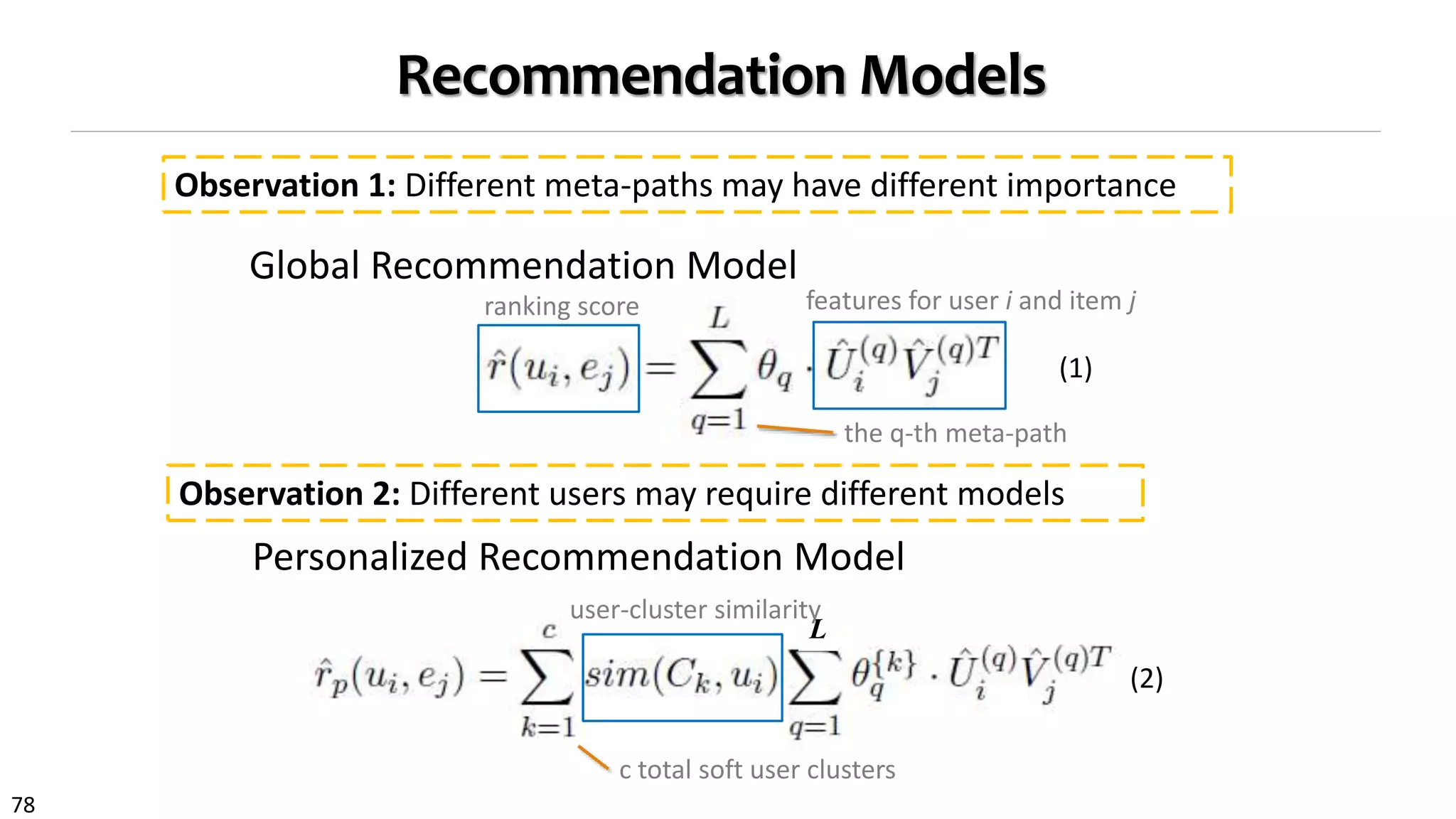
![106
Model Learning: A Joint Optimization Problem
A joint optimization problem:
ance may not
mization prob-
neously, which
egularization.
bject in terms
earned model
n Sec. 4.1 and
4.2 along with
4.3.
m
on network as
ed citation re-
e of negatives
d may cite in
methods adopt
ctive functions
egative exam-
subgraph R(V ) .
Integrating theloss in Eq. (5) with graph regularization in
Eq. (6), we formulate a joint optimization problem follow-
ing the graph-regularized semi-supervised learning frame-
work [9]:
min
P ,W ,F P ,F A ,F V
1
2
L + R +
cp
2
∥P∥2
F +
cw
2
∥W ∥2
F
s.t. P ≥ 0; W ≥ 0. (7)
To ensurestability of theobtained solution, Tikhonov reg-
ularizers are imposed on variables P and W [4], and we use
cp , cw > 0 to control the strength of regularization. In ad-
dition, we impose non-negativity constraints to make sure
learned group membership indicators and feature weights
can provide semantic meaning as we want.
4.2 The ClusCite Algorithm
Directly solving Eq (7) is not easy because the objective
function is non-convex. We develop an alternative mini-
mization algorithm, called ClusCit e, which alternatively
formance, which is defined as follows:
L =
n
i ,j = 1
Mi j Yi j −
K
k = 1
L
l = 1
θ
(k )
pi w
(l )
k S
(i )
j l −
K
k = 1
θ
(k )
pi FP ,k j
2
,
=
n
i = 1
M i ⊙ Y i − R i P(W S(i ) T
+ FP )
2
2
.
(5)
We define the weight indicator matrix M ∈ Rn × n
for the
citation matrix, where M i j takes value 1 if the citation rela-
tionship between pi and pj is observed and 0 in other cases.
By doing so, the model can focus on positive examples and
get rid of noise in the 0 values. One can also impose a de-
gree of confidence by setting different weights on different
observed citations, but we leave this to future study.
For ease of optimization, the loss can be further rewrit-
ten in a matrix form, where matrix P ∈ R(|T |+ |A |+ |V |) × K
is
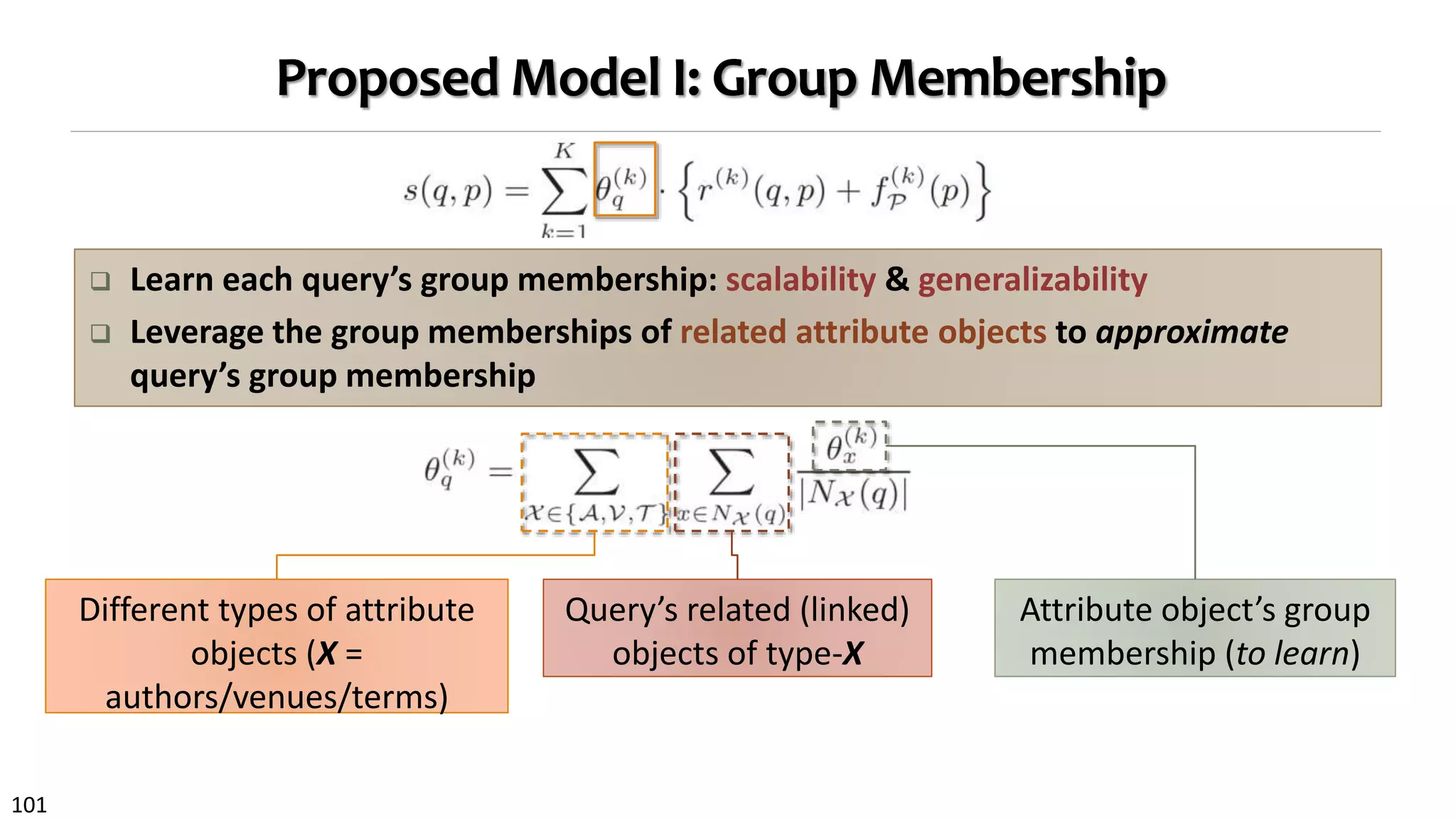
nd other conceptual information. Specifically, we
the query’s group membership θ
( k )
q by weighted
on of group memberships of its attribute objects.
θ( k )
q =
X ∈ { A ,V ,T } x ∈ N X (q)
θ
(k )
x
|NX (q)|
. (4)
e NX (q) to denote type X neighbors for query q,
tribute objects. How likely a type X object is to
the k-th interest group is represented by θ
(k )
x .
specific citation recommendation can be efficiently
d for each query manuscript q by applying Eq. (1)
h definitions in Eqs. (2), (3) and (4).
ODEL LEARNING
ction introduces thelearning algorithm for thepro-
ation recommendation model in Eq. (1).
are three sets of parameters in our model: group
hips for attribute objects; feature weights for inter-
s; and object relative authority within each inter-
. A straightforward way is to first conduct hard-
g of attribute objects based on the network and
ve feature weights and relative authority for each
Such a solution encounters several problems: (1)
ct may have multiple citation interests, (2) mined
usters may not properly capture distinct citation
ten in a matrix form, where matrix P ∈ R( |T |+ |A |+ |V |)× K
is
group membership indicator for all attribute objects while
R i ∈ Rn × ((|T |+ |A |+ |V |))
is thecorresponding neighbor indica-
tor matrix such that R i P = X ∈ { A ,V ,T } x ∈ N X ( pi )
θ
( k )
x
|N X ( pi ) |
.
Feature weights for each interest group are represented by
each row of thematrix W ∈ RK × L
, i.e., Wk l = w
( l )
k . Hadamard
product ⊙is used for the matrix element-wise product.
As discussed in Sec. 3.3, to achieve authority learning
jointly, we adopt graph regularization to preserve consisten-
cy over the paper-author and paper-venue subgraphs, which
takes the following form:
R = λ A
2
n
i = 1
|A |
j = 1
R
(A )
i j
F P , i
D
( P A )
i i
−
F A , j
D
( A P )
j j
2
2
+ λ V
2
n
i = 1
|V |
j = 1
R
( V )
i j
F P , i
D
( P V )
i i
−
F V , j
D
( V P )
j j
2
2
.
(6)
Theintuition behind theabovetwo termsisnatural: Linked
objects in theheterogeneousnetwork are morelikely to share
similar relative authority scores [14]. To reduce impact of
node popularity, we apply a normalization technique on au-
thority vectors, which helpssuppresspopular objects to keep
them from dominating the authority propagation. Each
element in the diagonal matrix D ( P A ) ∈ Rn × n
is the de-
gree of paper pi in subgraph R(A ) while each element in
D ( A P ) ∈ R|A |× |A |
is the degree of author aj in subgraph
R(A ) Similarly, we can define the two diagonal matrices for
weighted model prediction error
Graph
regularization
to encode
authority
propagation
Algorithm: Alternating minimization (w.r.t. each variable)](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-106-2048.jpg)
![107
Learning Algorithm
Updating formula for alternating minimization
First, to learn group membership for attribute objects,
we take the derivative of the objective function in Eq. (7)
with respect to P while fixing other variables, and apply
the Karush-Kuhn-Tucker complementary condition to im-
pose the non-negativity constraint [7]. With some simple
algebraic operations, a multiplicative update formula for P
can be derived as follows:
Pj k ← Pj k
n
i = 1
R T
i
˜Y i S( i )
W T
+ L+
P 1 + L−
P 2
j k
LP 0 + L−
P 1 + L+
P 2 + cp P
j k
, (8)
where matrices LP 0, LP 1 and LP 2 are defined as follows:
LP 0 =
n
i = 1
R T
i Ri PW ˜S( i )T ˜S(i )
W T
; LP 1 =
n
i = 1
R T
i
˜Y i FT
P ;
LP 2 =
n
i = 1
R T
i Ri P ˜F
( i )
P
˜F
( i )T
P +
n
i = 1
RT
i Ri PW ˜S( i )T
FT
P
+
n
i = 1
RT
i Ri PFP
˜S(i )
W T
.
In order to preserve non-negativity throughout the update,
L P 1 is decomposed into L −
P 1 and L +
P 1 where A+
i j = (|Ai j | +
Ai j )/ 2 and A−
i j = (|Ai j | − Ai j )/ 2. Similarly, we decompose
L into L −
and L +
, but note that the decomposition is
i = 1
In order to preserve non-negativity throughout the update,
L P 1 is decomposed into L −
P 1 and L +
P 1 where A+
i j = (|Ai j | +
Ai j )/ 2 and A−
i j = (|Ai j | − Ai j )/ 2. Similarly, we decompose
L P 2 into L −
P 2 and L +
P 2, but note that the decomposition is
applied to each of the three components of L P 2, respectively.
We denote the masked Y i as ˜Y i , which is the Hadamard
product of M i and Y i . Similarly, ˜S(i ) and ˜F
(i )
P denote row-
wise masked S(i ) and F P by M i .
Second, to learn feature weights for interest groups, the
multiplicative update formula for W can be derived follow-
ing a similar derivation as that of P, taking the form:
Wk l ← Wk l
n
i = 1
PT
R T
i
˜Y i S( i )
+ L−
W
k l
n
i = 1
PT R T
i R i PW ˜S(i ) T ˜S(i ) + L +
W + cw W
k l
,
(9)
where we have L W = n
i = 1 P T R T
i R i P F P
˜S( i ) .
Similarly, to preserve non-negativity of W , L W is decom-
posed into L +
W and L −
W , which can be computed same be-
fore.
Finally, we derive the authority propagation functions in
Eq. (3) by optimizing the objective function in Eq. (7) with
respect to the authority score matrices of papers, authors
arned group membership indicators and feature weights
n provide semantic meaning as we want.
2 The ClusCite Algorithm
Directly solving Eq (7) is not easy because the objective
nction is non-convex. We develop an alternative mini-
zation algorithm, called ClusCit e, which alternatively
timizes the problem with respect to each variable.
Thelearning algorithm essentially accomplishestwo things
multaneously and iteratively: Co-clustering of attribute
jectsand relevancefeatureswith respect to interest groups,
d authority propagation between different objects. Dur-
g an iteration, different learning components will mutually
hance each other (Fig. 3): Feature weights and relative
thority can be more accurately derived with high quality
terest groups while in turn they serve a good feature for
arning high quality interest groups.
First, to learn group membership for attribute objects,
e take the derivative of the objective function in Eq. (7)
th respect to P while fixing other variables, and apply
e Karush-Kuhn-Tucker complementary condition to im-
ose the non-negativity constraint [7]. With some simple
gebraic operations, a multiplicative update formula for P
n be derived as follows:
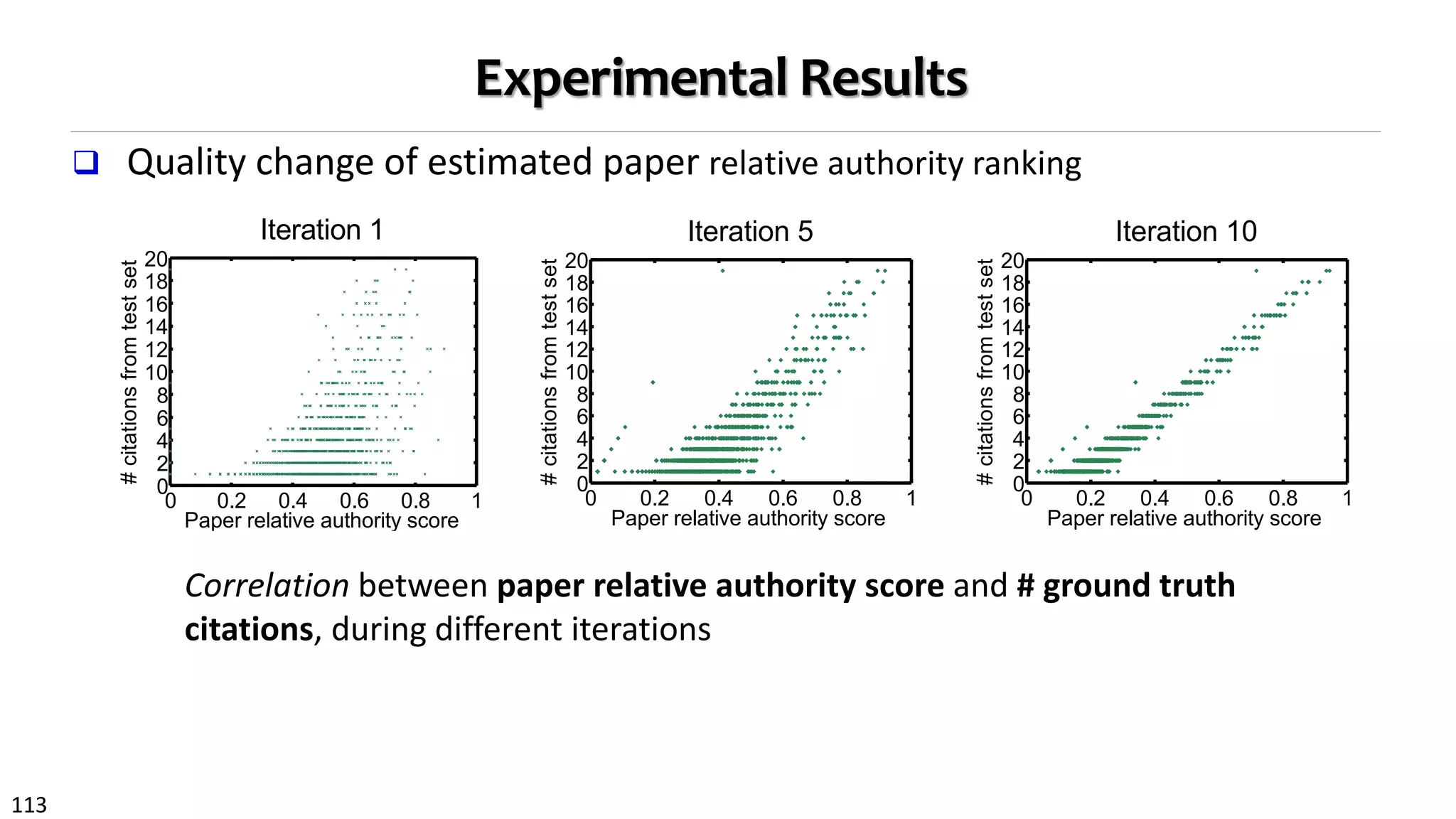
0 0.2 0.4 0.6 0.8 1
0
2
4
6
8
10
12
14
16
18
20
Paper relative authority score
#citationsfromtestset
Iteration 1
0 0.2 0.4 0.6 0.8 1
0
2
4
6
8
10
12
14
16
18
20
Paper relative authority score
#citationsfromtestset
Iteration 5
0 0.2 0.4 0.6 0.8 1
0
2
4
6
8
10
12
14
16
18
20
Paper relative authority score
#citationsfromtestset
Iteration 10
Figure 3: Correlat ion bet ween paper relat ive au-
t hority and # ground t rut h cit at ions, during differ-
ent it erat ions.
and venues. Specifically, we take the derivative of the ob-
jective function with respect to F P , F A and FV , and follow
traditional semi-supervised learning frameworks [8] to derive
the update rules, which take the form:
FP = GP (FP , FA , FV ; λA , λV )
=
1
λA + λV
λA FA ST
A + λV FV ST
V + L F P (10)
FA = GA (FP ) = FP SA ; (11)
FV = GV (FP ) = FP SV . (12)
where we have normalized adjacency matrices and the paper
authority guidance terms defined as follows:
SA = (D (P A )
)− 1/ 2
R ( A )
(D ( A P )
)− 1/ 2
A lgor it hm 1 Model Learning by ClusCite
I nput : adjacency matrices { Y , SA , SV } , neighbor indicator
R , mask matrix M , meta path-based features { S(i )
} , pa-
rameters { λA , λV , cw , cp } , number of interest groups K
Out put : group membership P, feature weights W , relative
authority { FP , FA , FV }
1: Initialize P, W with positive values, and { FP , FA , FV }
with citation counts from training set
2: repeat
3: Update group membership P by Eq. (8)
4: Update feature weights W by Eq. (9)
5: Compute paper relative authority FP by Eq. (10)
6: Compute author relative authority FA by Eq. (11)
7: Compute venue relative authority FV by Eq. (12)
8: unt il objective in Eq. (7) converges
membership matrix P by Eq. (8) takesO(L|E|3
/ n3
+ L2
|E|2
/ n2
+ K dn) time. Learning the feature weights W by Eq. (9)
takes O(L|E|3
/ n3
+ L2
|E|2
/ n2
+ K dn) time. Updating all
three relative authority matrices takes O(L|E |3
/ n3
+ |E| +
Table 3: St at ist ics of two bibliogr aphic networ ks.
Data sets D B L P P ubM ed
# papers 137,298 100,215
# authors 135,612 212,312
# venues 2,639 2,319
# terms 29,814 37,618
# relationships ∼2.3M ∼3.6M
Paper avg citations 5.16 17.55
Table 4: Tr aining, validat ion and t est ing paper sub-
set s from t he D B L P and PubM ed dat aset s
(a) The DBLP dataset
Subsets Train Validation Test
Years T0= [1996, 2007] T1= [2008] T2 = [2009, 2011]
# papers 62.23% 12.56% 25.21%
(b) The PubMed dataset
Subsets Train Validation Test
Years T0= [1966, 2008] T1= [2009] T2 = [2010, 2013]
# papers 64.50% 7.81% 27.69%
set (T0) as the ground truth. Such an evaluation practice](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-107-2048.jpg)

![109
Experimental Setup
Datasets
– DBLP: 137k papers; ~2.3M relationships; Avg # citations/paper: 5.16
– PubMed: 100k papers; ~3.6M relationships; Avg # citations/paper: 17.55
Evaluations
hbor indicator
res { S(i )
} , pa-
groups K
hts W , relative
{ FP , FA , FV }
8)
by Eq. (10)
by Eq. (11)
by Eq. (12)
3
/ n3
+ L2
|E |2
/ n2
W by Eq. (9)
. Updating all
E|3
/ n3
+ |E | +
compute Clus-
# papers 137,298 100,215
# authors 135,612 212,312
# venues 2,639 2,319
# terms 29,814 37,618
# relationships ∼2.3M ∼3.6M
Paper avg citations 5.16 17.55
Table 4: Training, validat ion and t est ing paper sub-
set s from t he D B L P and PubM ed dat aset s
(a) The DBLP dataset
Subsets Train Validation Test
Years T0= [1996, 2007] T1= [2008] T2= [2009, 2011]
# papers 62.23% 12.56% 25.21%
(b) The PubMed dataset
Subsets Train Validation Test
Years T0= [1966, 2008] T1= [2009] T2= [2010, 2013]
# papers 64.50% 7.81% 27.69%
set (T0) as the ground truth. Such an evaluation practice
is more realistic because a citation recommendation system](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-109-2048.jpg)
![110
Experimental Setup
Feature generation: meta paths
– (P – X – P)y, where X = {A, V, T} and y = {1, 2, 3}
E.g., (P – X – P)2 = P – X – P – X – P
– P – X – P P
– P – X – P P
Feature generation: similarity measures
– PathSim [VLDB’11]: symmetric measure
– Random walk-based measure [SDM’12]: can be asymmetric
Combining meta paths with different measures, in total we have 24 meta path-
based relevance features](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-110-2048.jpg)
![114
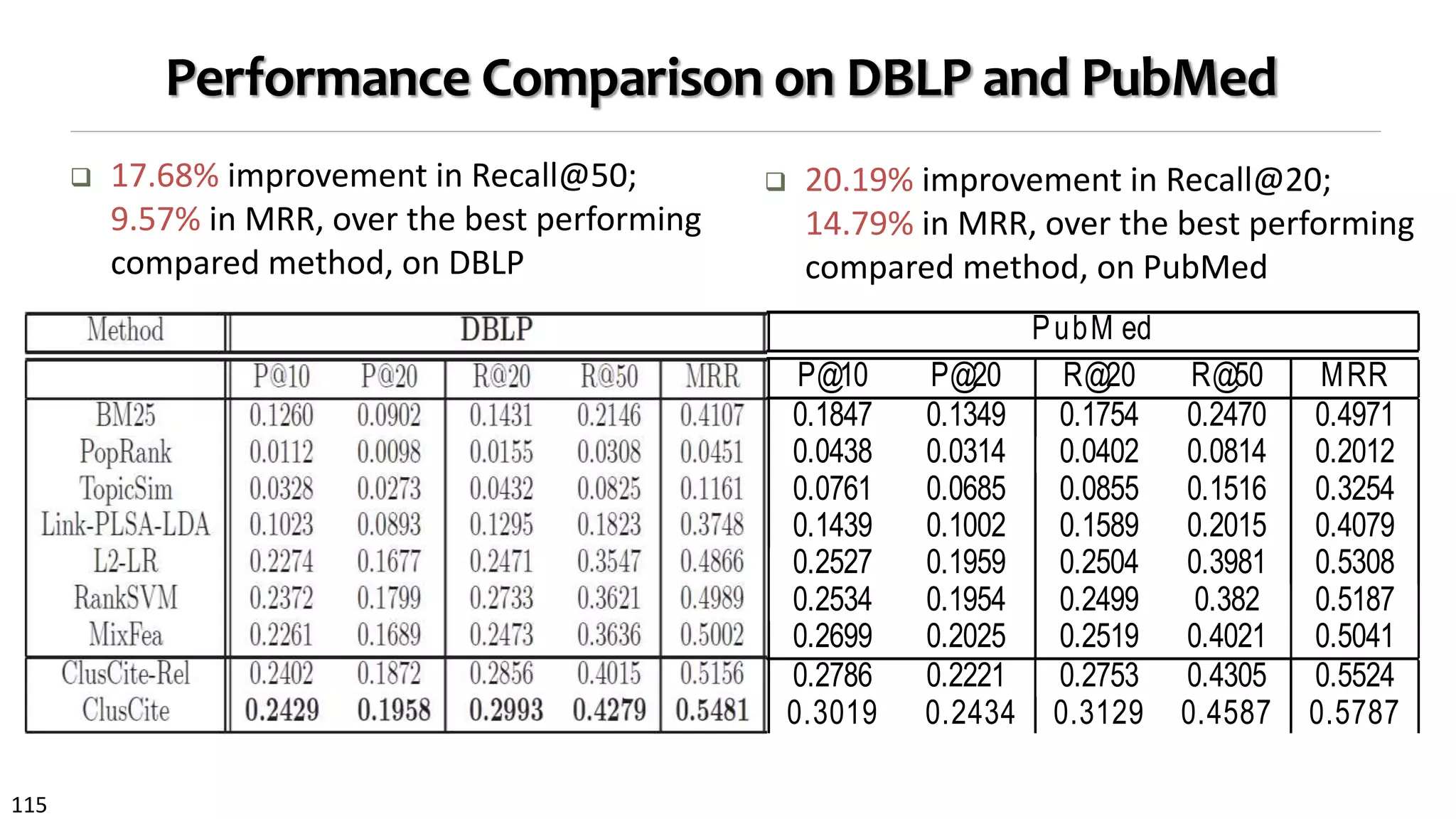
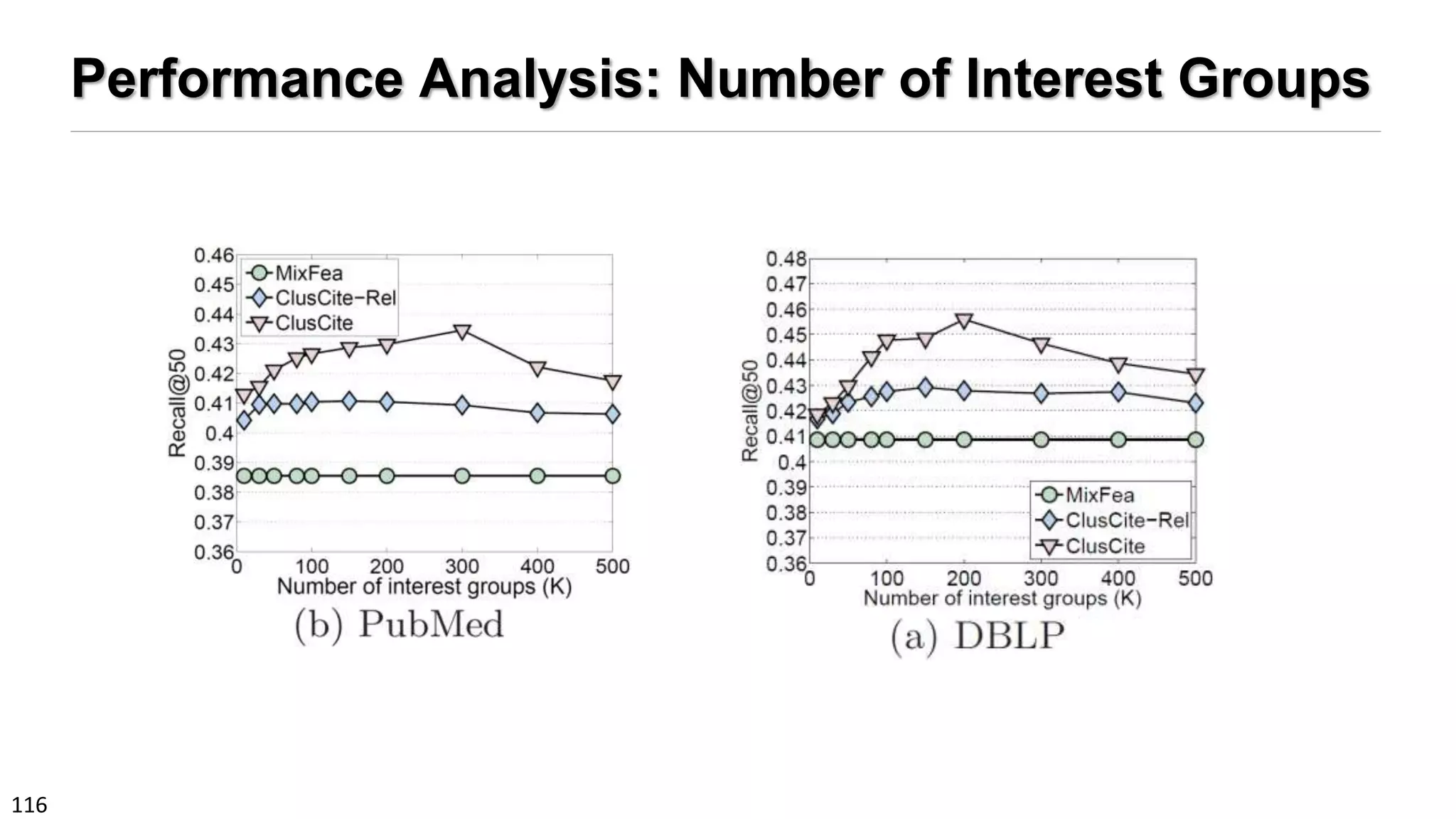
Performance Comparison: Methods Compared
Compared methods:
1. BM25: content-based
2. PopRank [WWW’05]: heterogeneous link-based authority
3. TopicSim: topic-based similarity by LDA
4. Link-PLSA-LDA [KDD’08]: topic and link relevance
5. Meta-path based relevance:
1. L2-LR [SDM’12, WSDM’12]: logistics regression with L2 regularization
2. RankSVM [KDD’02]
6. MixSim: relevance, topic distribution, PopRank scores, using RankSVM
7. ClusCite: the proposed full fledged model
8. ClusCite-Rel: with only relevance component](https://image.slidesharecdn.com/2015-07-tuto3-mininghin-160616082012/75/2015-07-tuto3-mining-hin-114-2048.jpg)




This document discusses mining heterogeneous information networks. It begins by defining heterogeneous information networks as information networks containing multiple object and link types. It then discusses how heterogeneous networks are richer than homogeneous networks derived from them by projection. Several examples of heterogeneous networks are given, such as bibliographic, social media, and healthcare networks. The document outlines principles for mining heterogeneous networks, including using meta-paths to explore network structures and relationships. It introduces methods for ranking, clustering, and classifying nodes in heterogeneous networks, such as the RankClus and NetClus algorithms, which integrate ranking and clustering.




































































![[DSC Europe 25] Marija Vlajkovic & Andrea Radonjanin - Integration of AI tool...](https://cdn.slidesharecdn.com/ss_thumbnails/qf1jrglttoc3bm8s3aop-final-integration-of-ai-tools-251208151905-394f3a6a-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Andy Cotgreave - Nothing is new in analytics.pptx](https://cdn.slidesharecdn.com/ss_thumbnails/mba4vzcurvoh5lfrd5zw-6-251205194645-341bbbbe-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Vid Stimac - Policy Parsimony: Between Oversimplifying and Ov...](https://cdn.slidesharecdn.com/ss_thumbnails/eqlepagzqp2rhg3gbluh-dsc-stimac-251120-251205090438-059e7f54-thumbnail.jpg?width=640&height=640&fit=bounds)




![[DSC Europe 25] Petar Zivanov - AI meets documents From chatbots to AI-powere...](https://cdn.slidesharecdn.com/ss_thumbnails/xer2bb6nrdc8pdpev0pc-8-251204082258-7c2fa4a1-thumbnail.jpg?width=640&height=640&fit=bounds)


![[DSC Europe 25] Dragan Vucic - Building the Learning Organization - How AI Tr...](https://cdn.slidesharecdn.com/ss_thumbnails/8brigo2sbu6qur6gxrra-7-251205085715-6ae07d24-thumbnail.jpg?width=640&height=640&fit=bounds)



