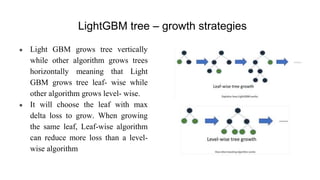
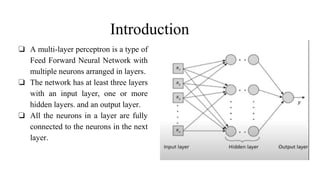
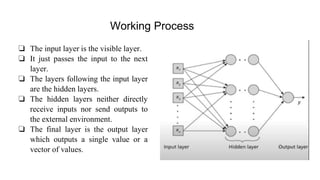
The document introduces LightGBM, a gradient boosting framework that improves training speed, accuracy, and efficiency through features like histogram-based splitting, exclusive feature bundling, and gradient-based sampling. It contrasts this with multi-layer perceptrons (MLPs), which are neural networks consisting of multiple layers with fully connected neurons for classification and regression tasks. While LightGBM handles large datasets and categorical variables effectively, it has disadvantages such as difficulty in parameter tuning and GPU configuration challenges.









![MLP Algorithms
Input: Input vector (x1, x2 ......, xn)
Output: Yn
Learning rate: α
Assign random weights and biases for every connection in the network in the range [-0.5, +0.5].
Step 1: Forward Propagation
1. Calculate Input and Output in the Input Layer:
Input at Node j 'Ij' in the Input Layer is:
Where,
ϰj, is the input received at Node j
Output at Node j 'Oj' in the Input Layer is:](https://image.slidesharecdn.com/lightgbmandmlpsslide-240420143023-b6f9b203/85/LightGBM-and-Multilayer-perceptron-MLP-slide-14-320.jpg)




















































