Download as PDF, PPTX





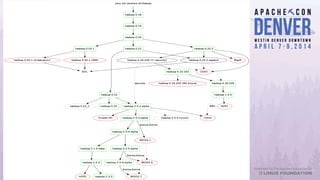

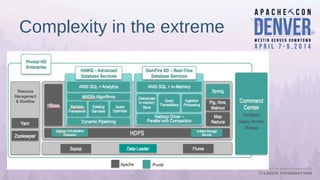







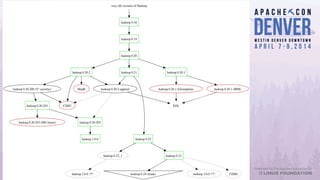
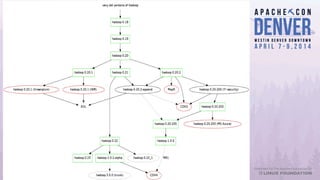
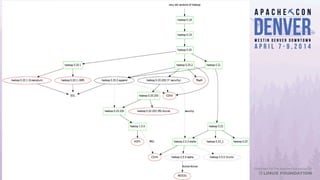
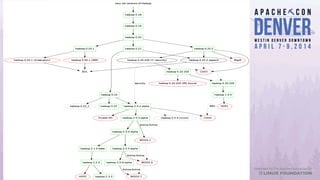














Apache Bigtop simplifies the deployment of Hadoop platforms by providing a streamlined stack that allows users to build, deploy, and configure their Hadoop ecosystems efficiently. The document discusses various case studies and lessons learned from using Bigtop in real-world scenarios, highlighting its capabilities and the growth of the associated ecosystem. Future developments focus on enhancing deployment processes, improving testing management, and increasing community engagement.






















![[OpenInfra Days Korea 2018] (Track 2) Neutron LBaaS 어디까지 왔니? - Octavia 소개](https://cdn.slidesharecdn.com/ss_thumbnails/26octavia-180704054917-thumbnail.jpg?width=640&height=640&fit=bounds)
![[OpenStack] 공개 소프트웨어 오픈스택 입문 & 파헤치기](https://cdn.slidesharecdn.com/ss_thumbnails/opensource-skimmingopenstackwithkoreausergroup-180824144737-thumbnail.jpg?width=640&height=640&fit=bounds)




















































