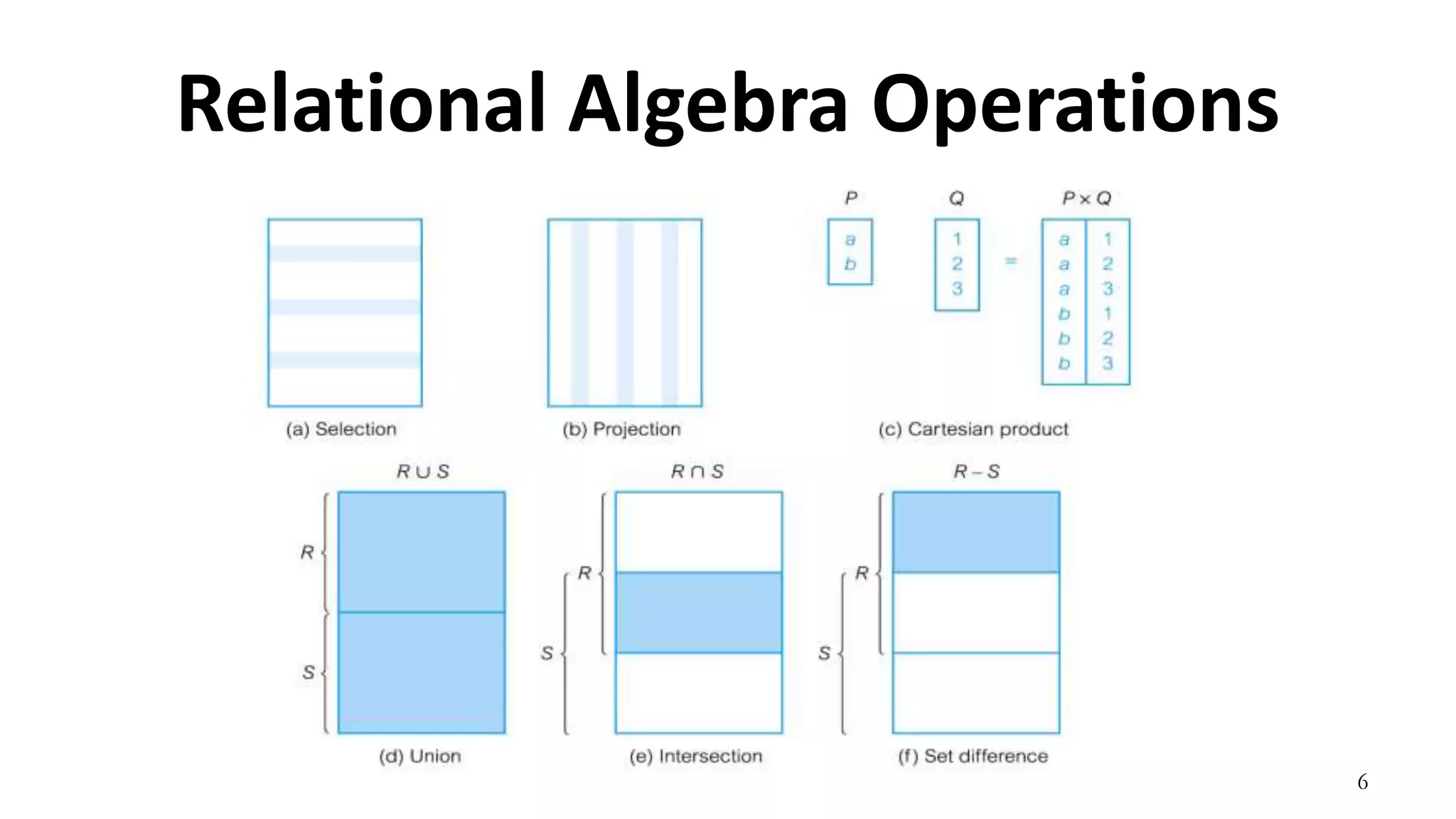
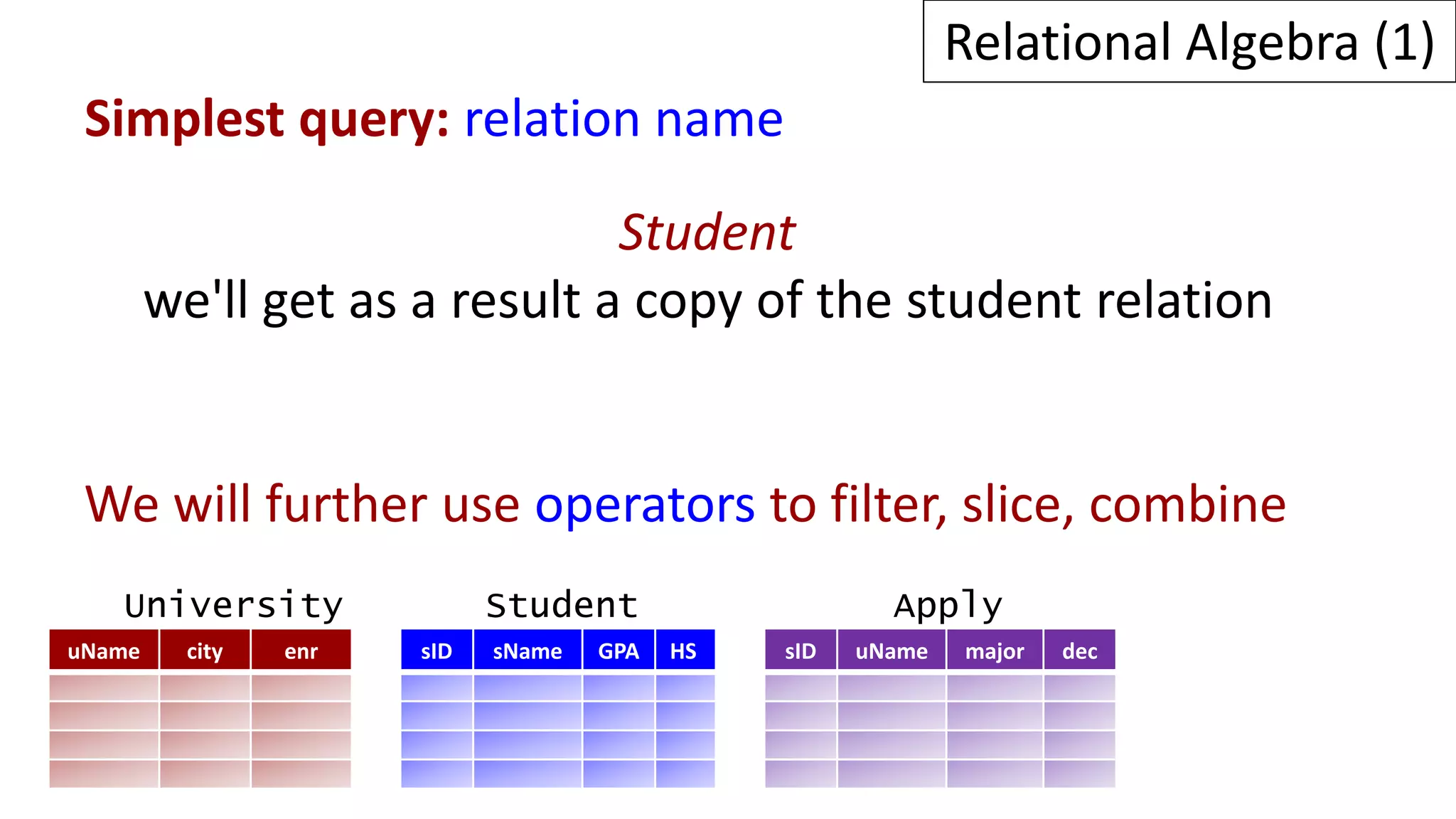
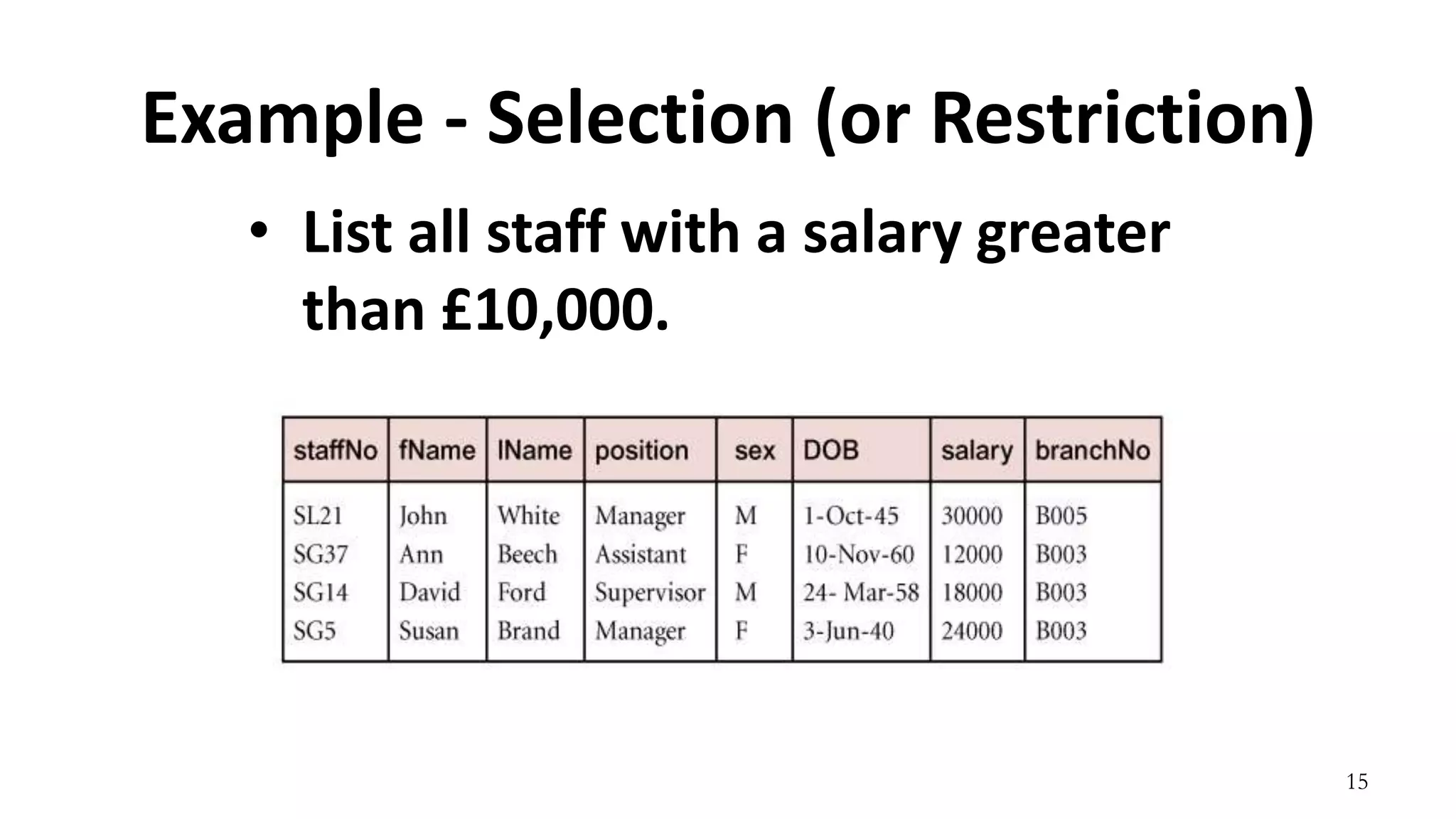
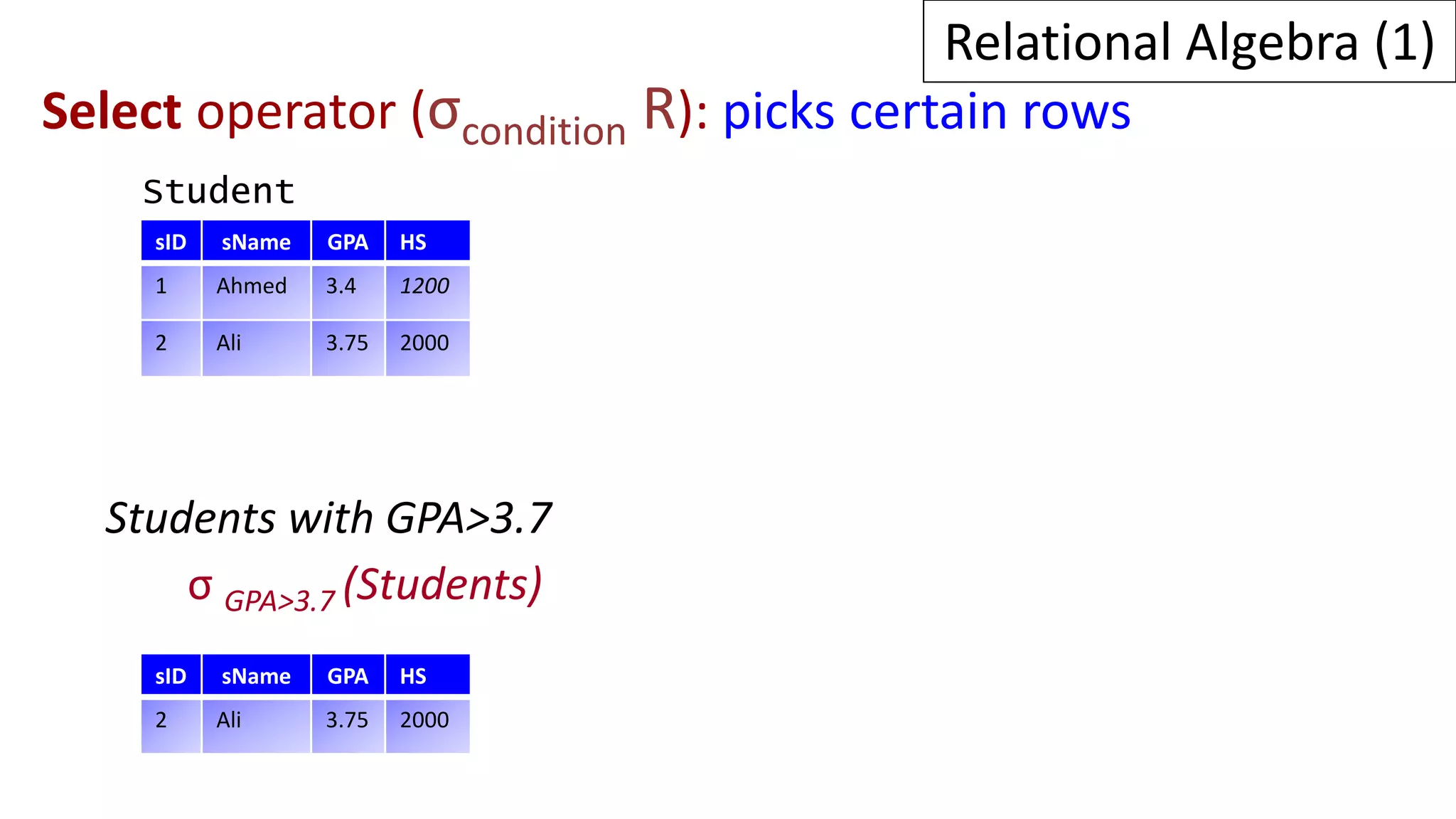
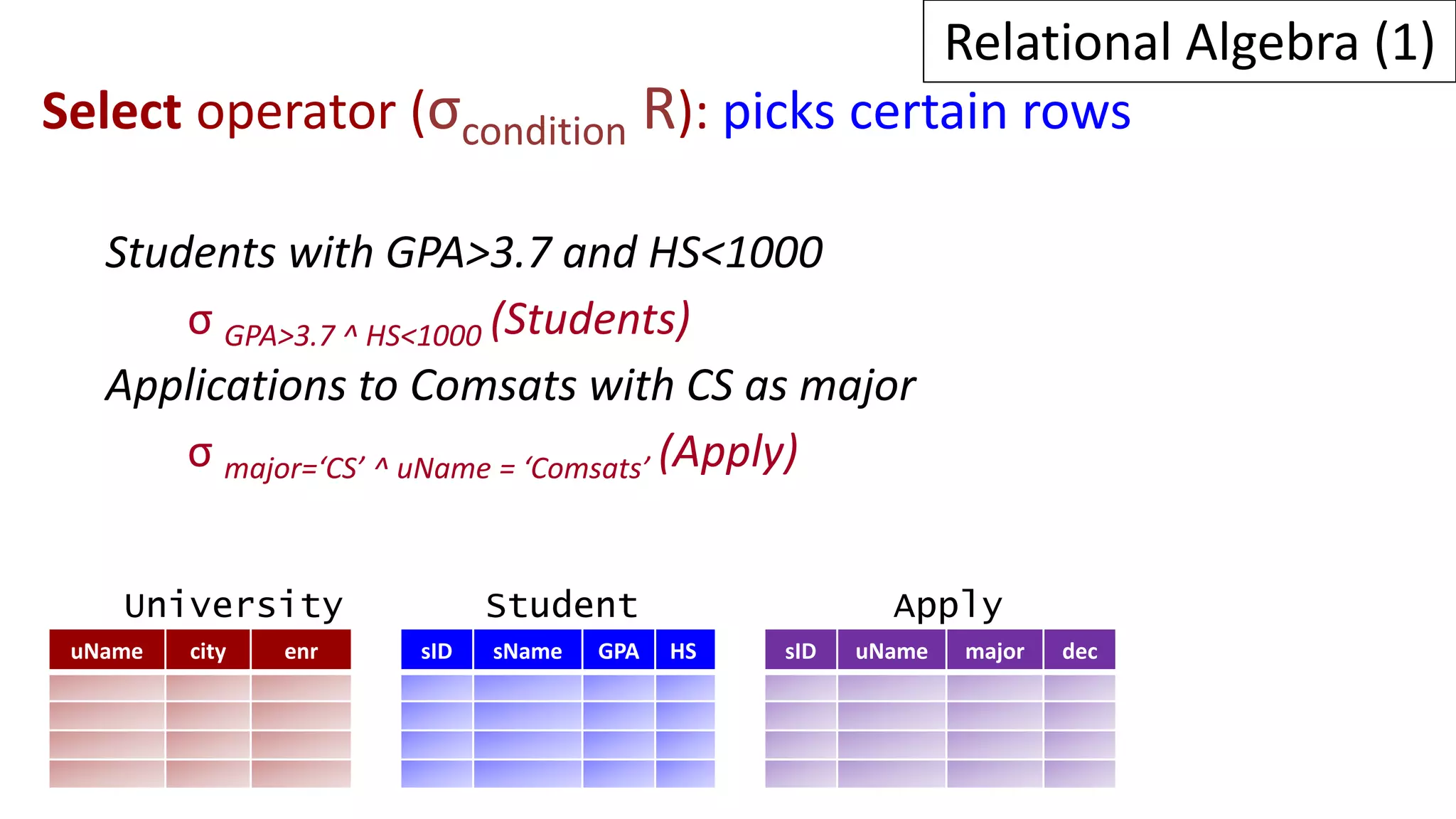
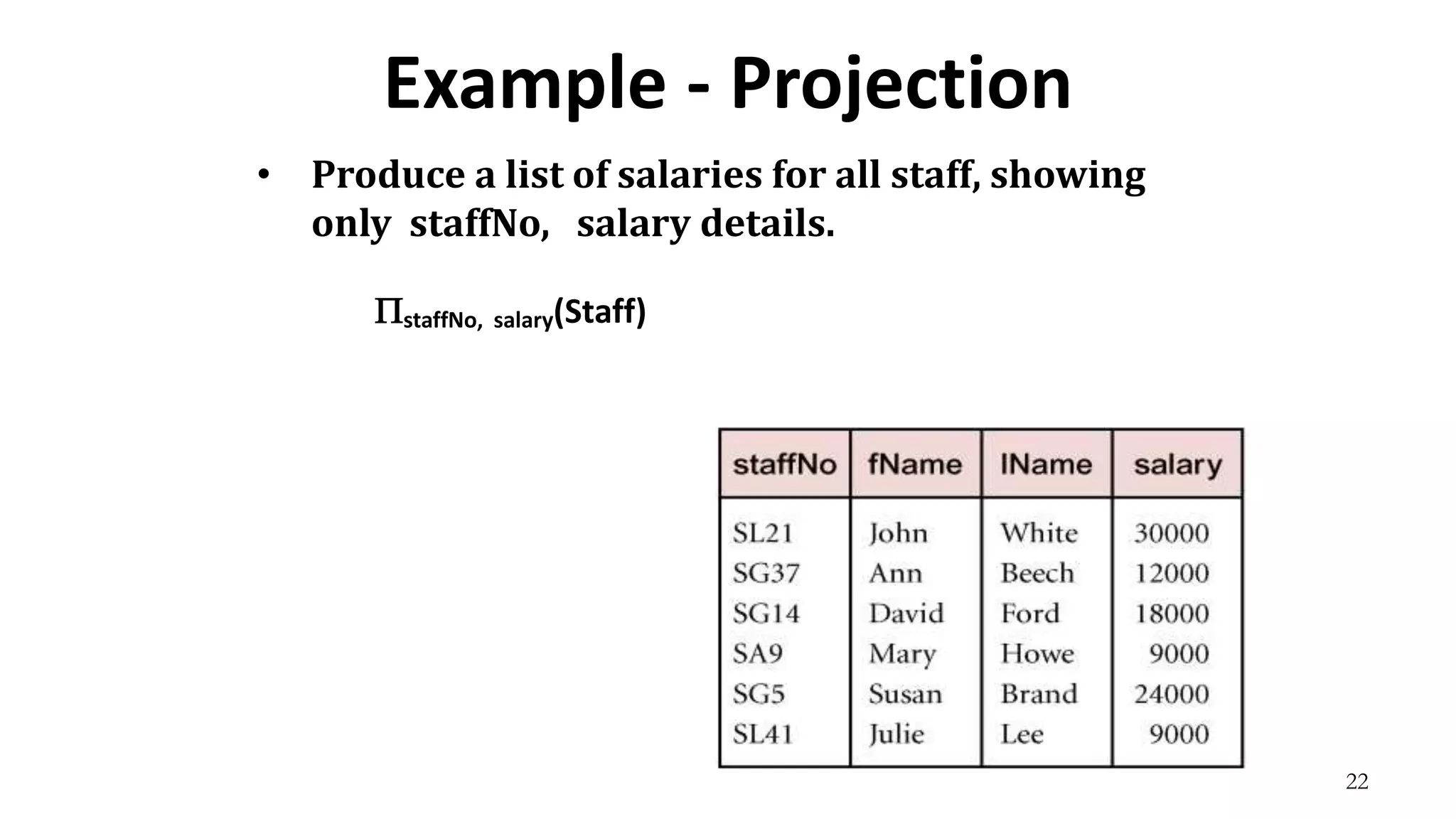
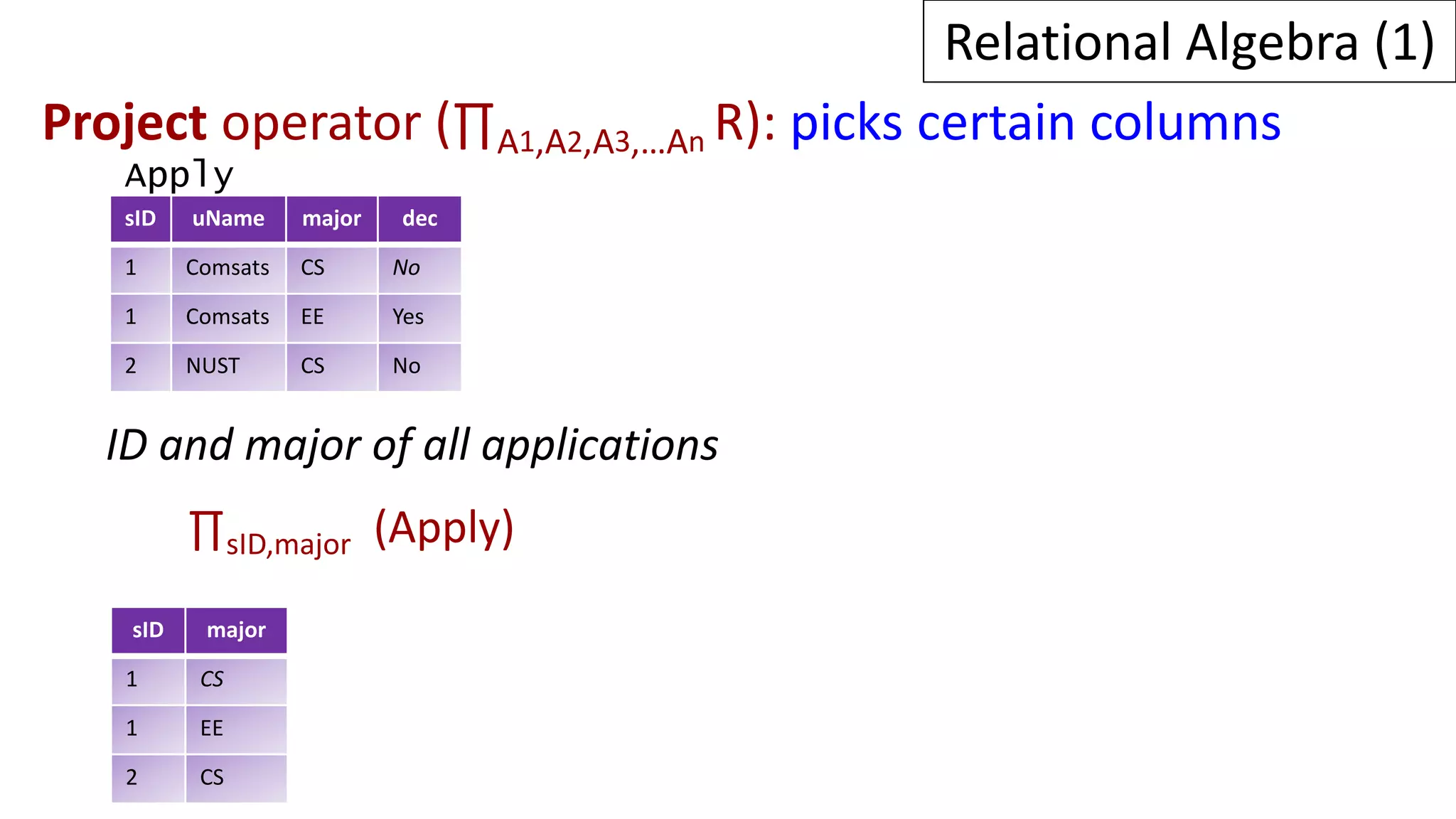
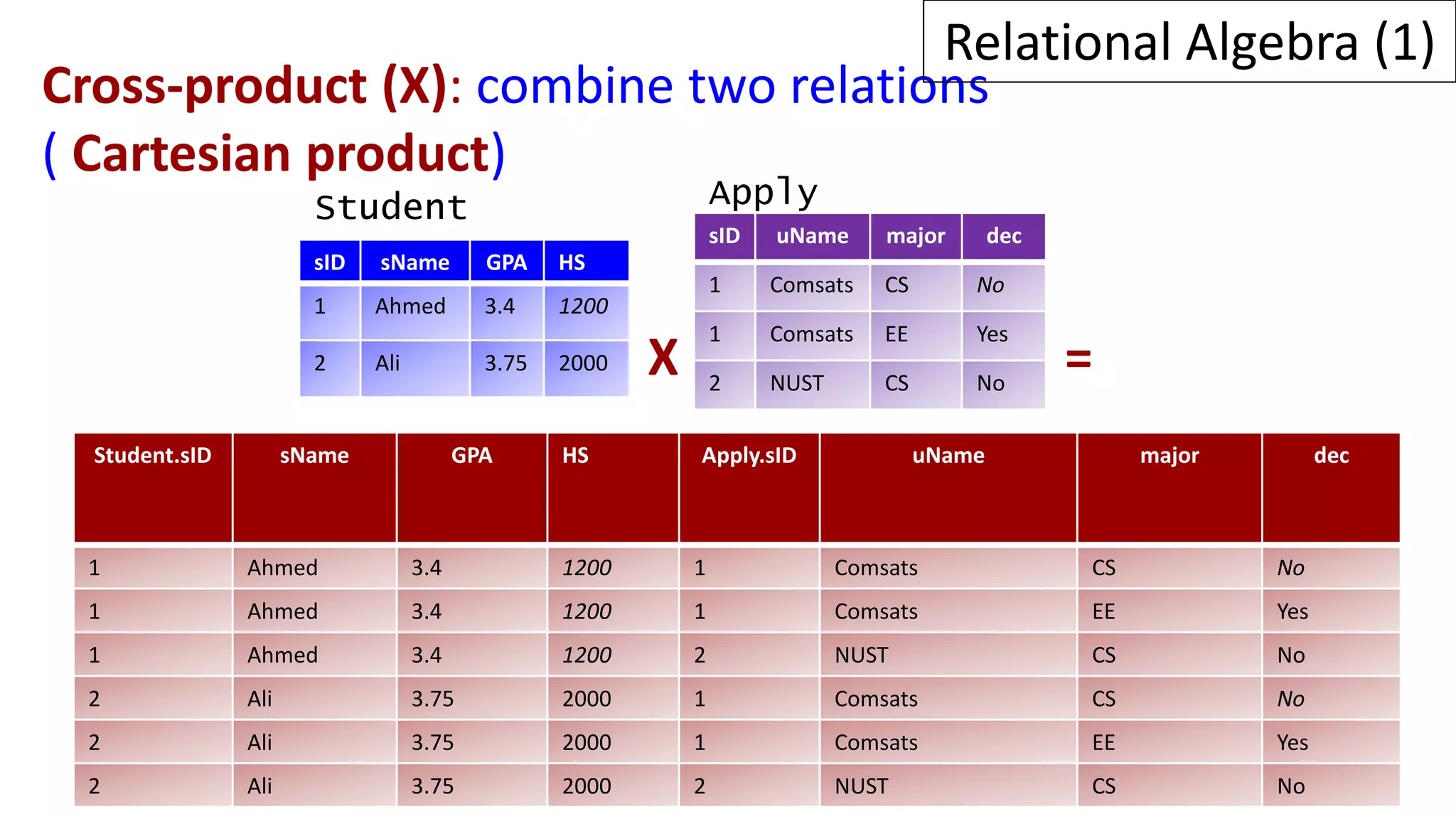
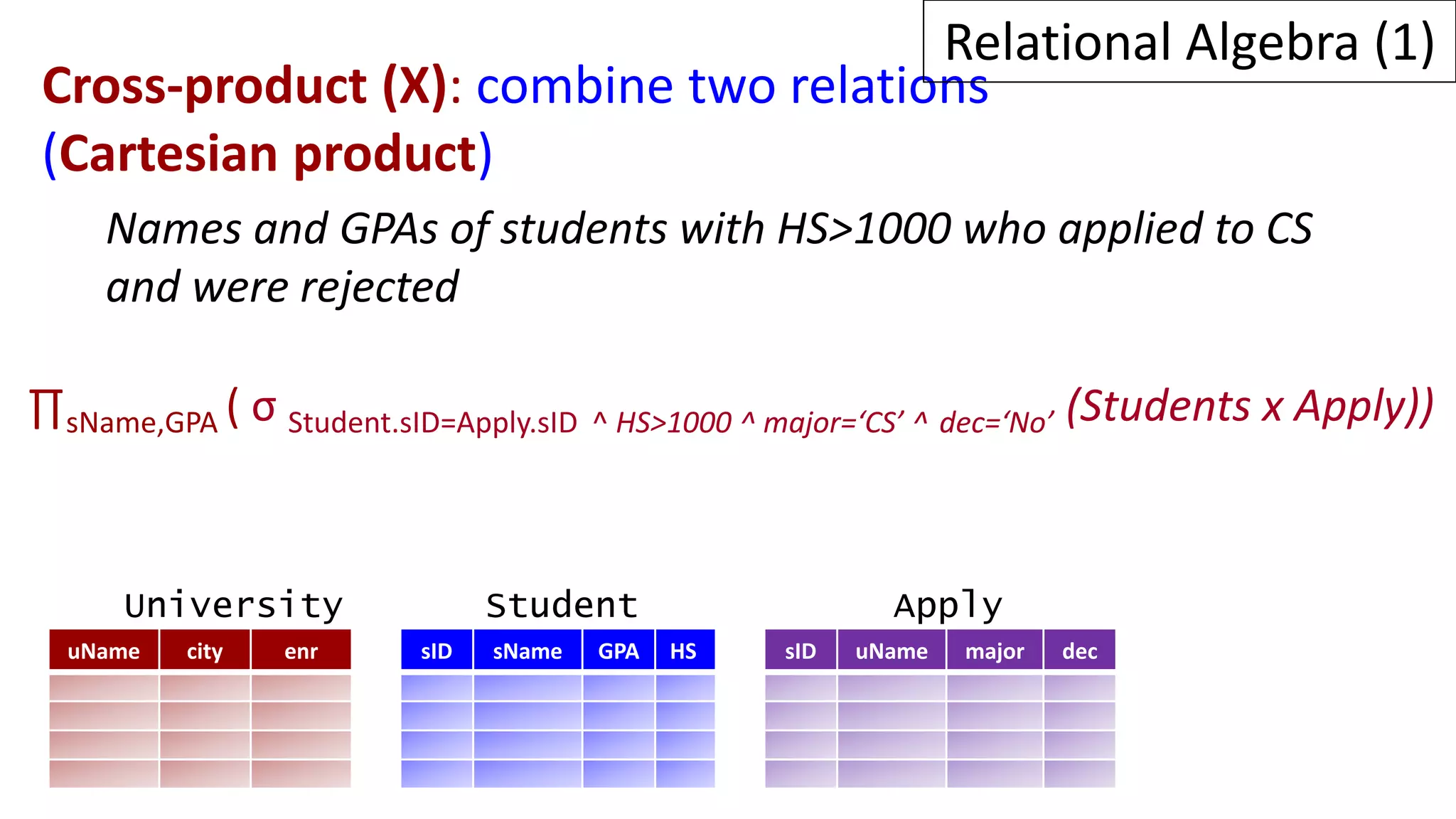
Relational algebra is a procedural query language used to manipulate data in relational databases. It consists of operands like relations and operators like selection, projection, union, and intersection that are applied to the operands to retrieve or construct new relations. Some common relational algebra operators are select (σ), project (π), join, union (∪), intersection (∩), and set difference. Relational algebra forms the theoretical foundation for query languages like SQL.