Download as PDF, PPTX
![[course site]
Javier Ruiz Hidalgo
javier.ruiz@upc.edu
Associate Professor
Universitat Politecnica de Catalunya
Technical University of Catalonia
Loss functions
#DLUPC](https://image.slidesharecdn.com/dlai2017d4l2lossfunctions-171101161756/75/Loss-functions-DLAI-D4L2-2017-UPC-Deep-Learning-for-Artificial-Intelligence-1-2048.jpg)















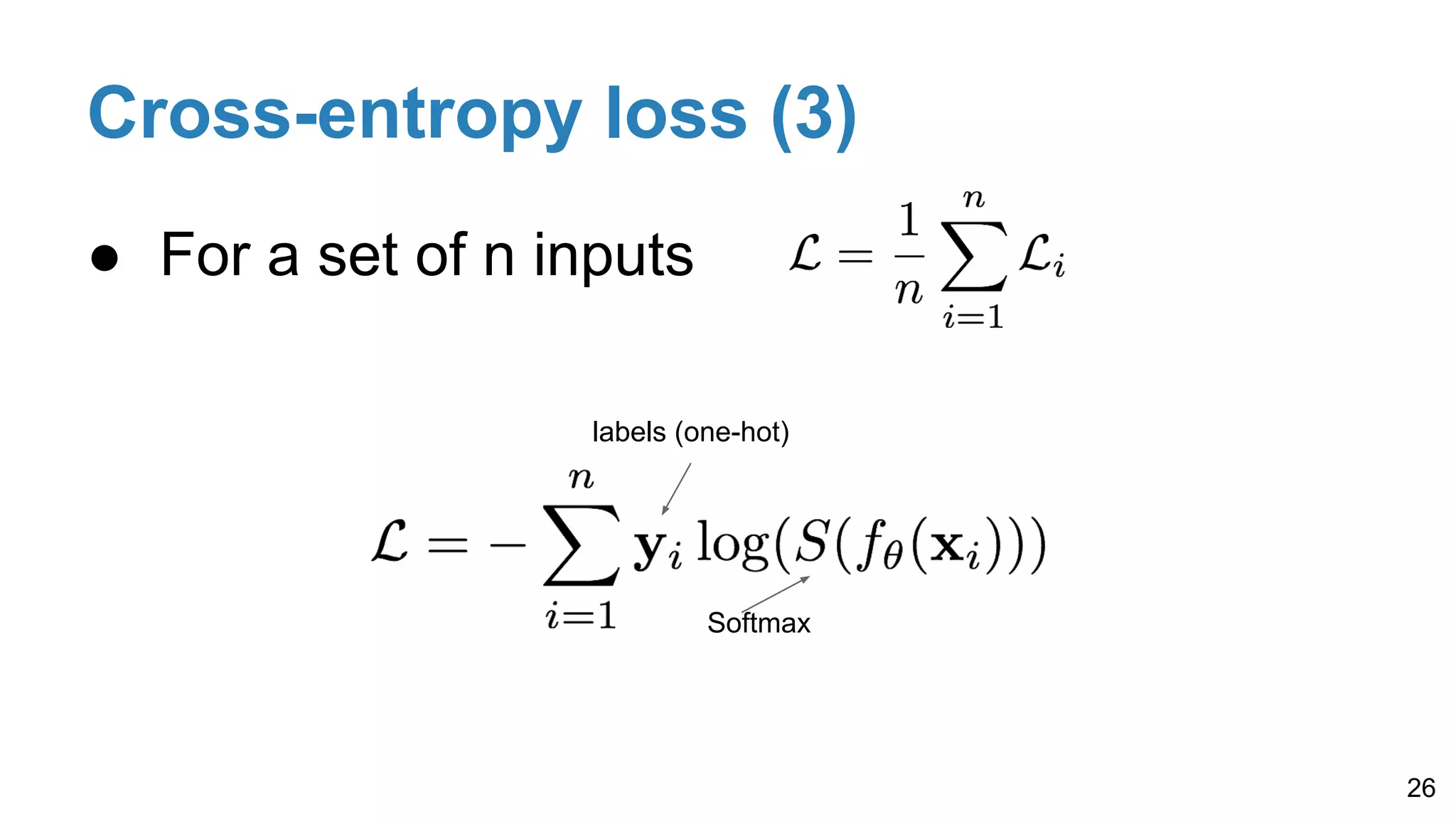









The document discusses the role and properties of loss functions in supervised deep learning, particularly in the context of regression and classification tasks. It explains key concepts such as the training process guided by loss functions, the common types like cross-entropy and square error, and the importance of regularization to prevent overfitting. The document also highlights the implementation of techniques like softmax and one-hot encoding for effective classification.
Introduces Javier Ruiz Hidalgo as an expert and outlines loss functions, including their definition, properties, and training processes.
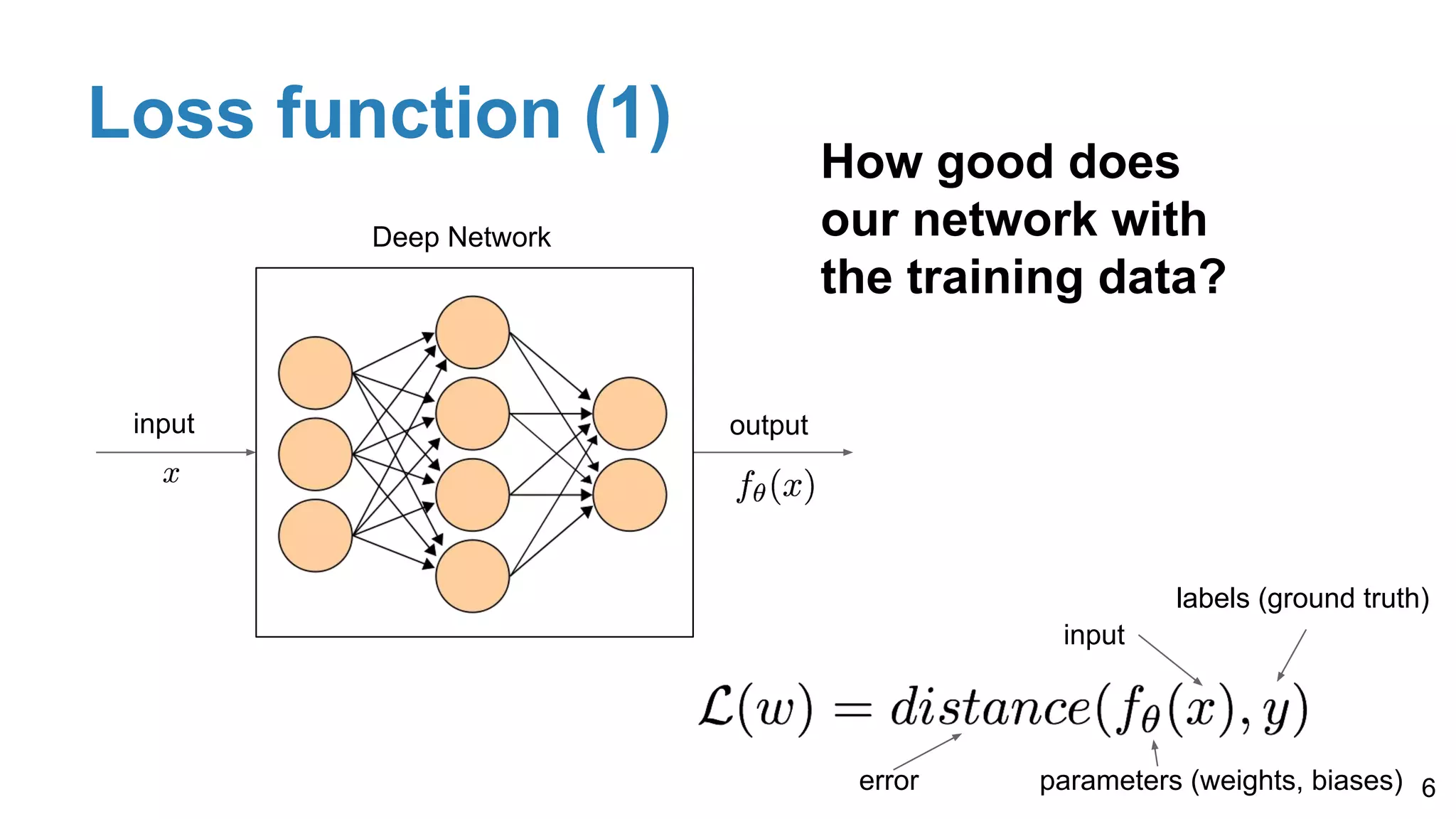
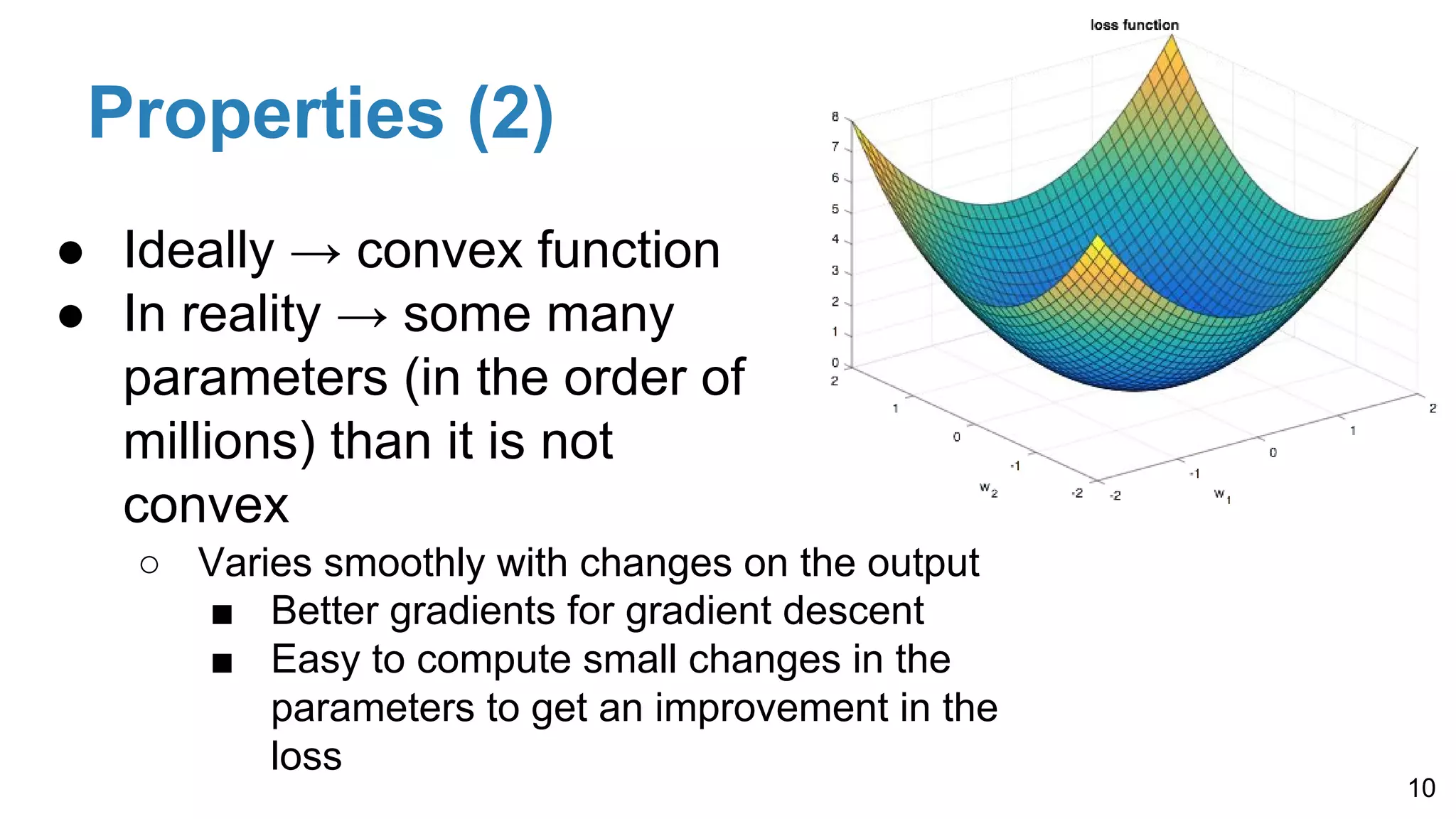
Defines loss functions as measures of model performance, discusses training via gradient descent, and their properties—ideally convex but often non-convex.
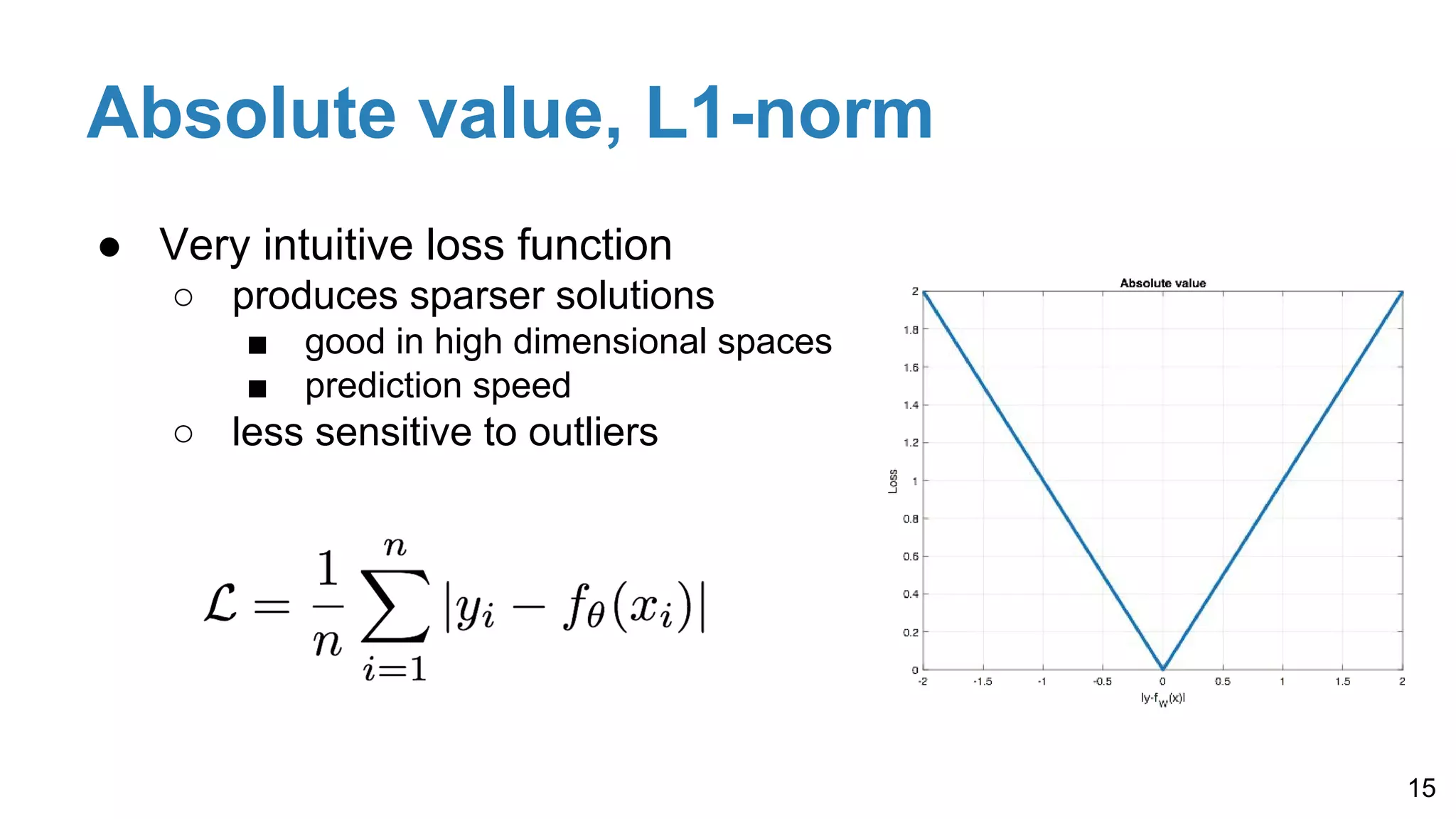
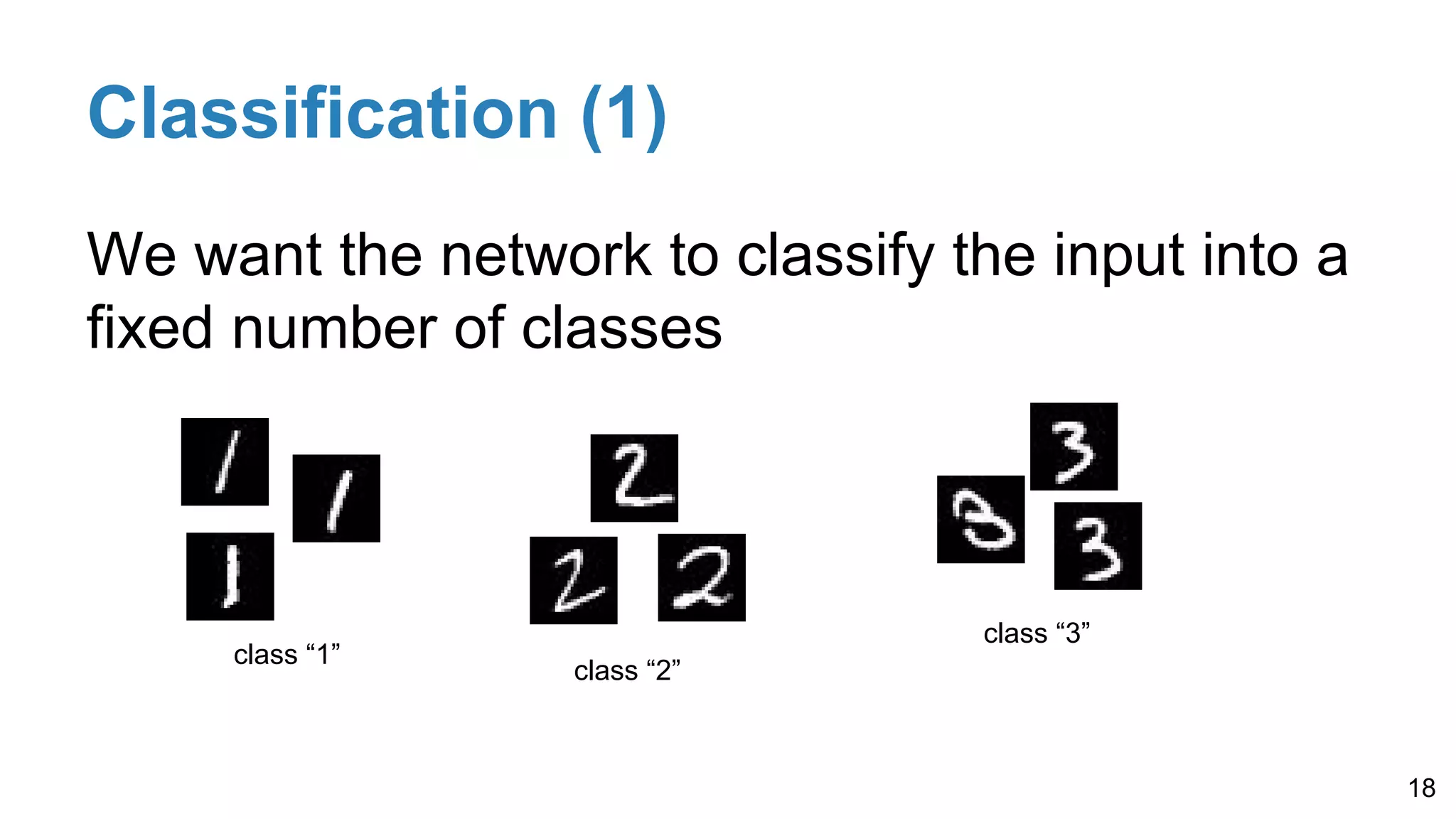
Explains common loss functions for regression (absolute value, square error) and classification (hinge loss, cross-entropy), highlighting their roles depending on tasks.
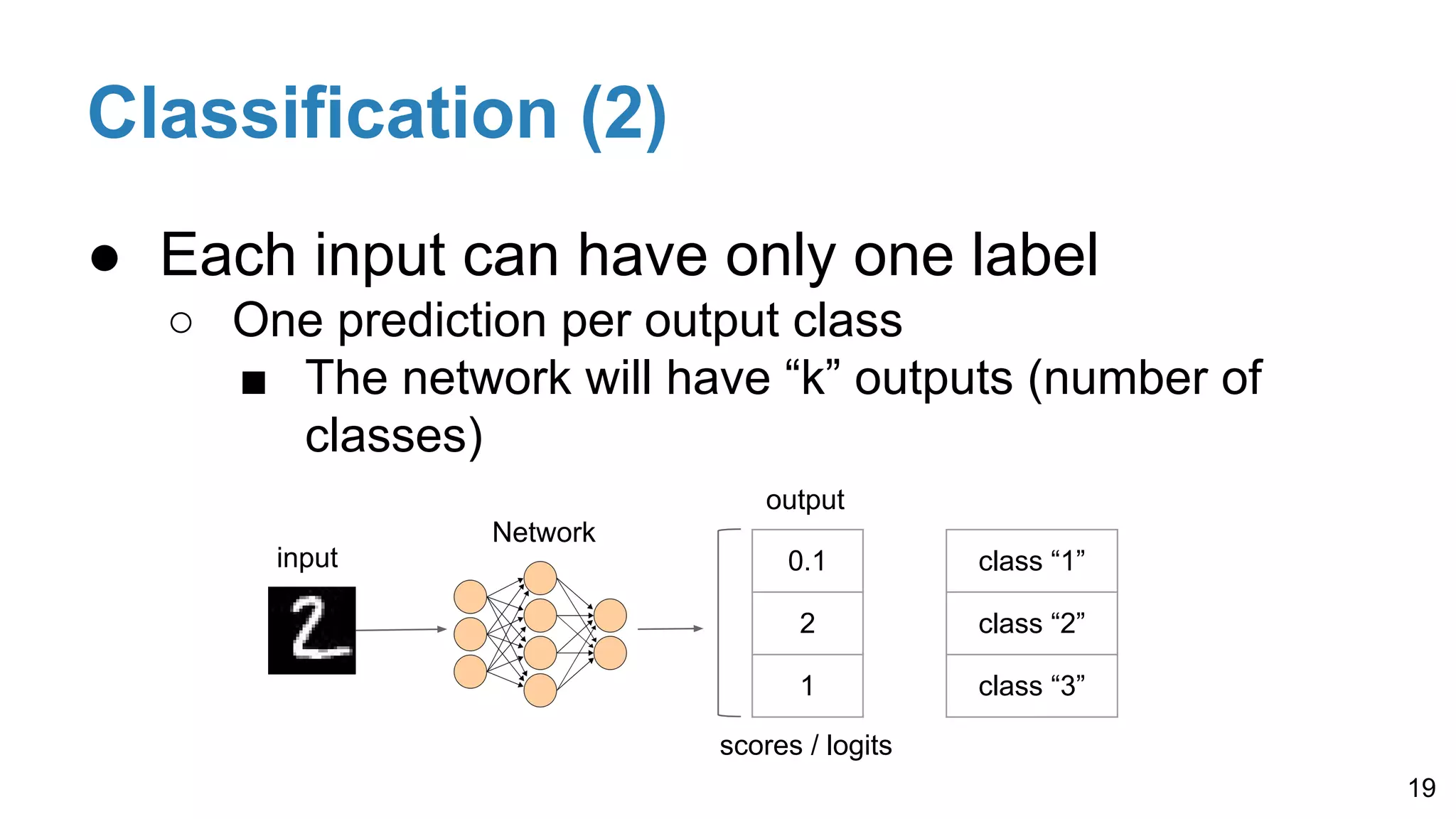
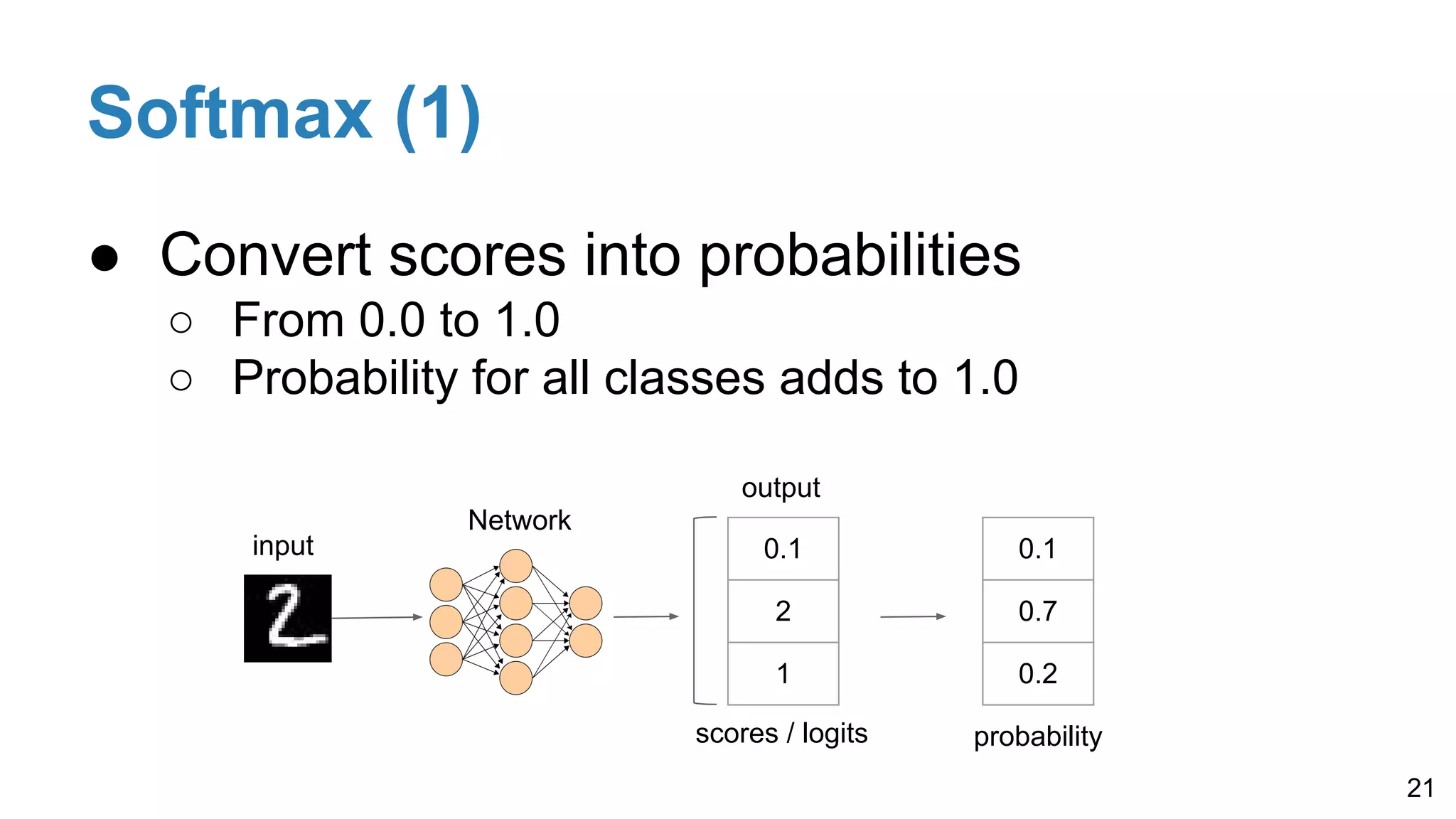
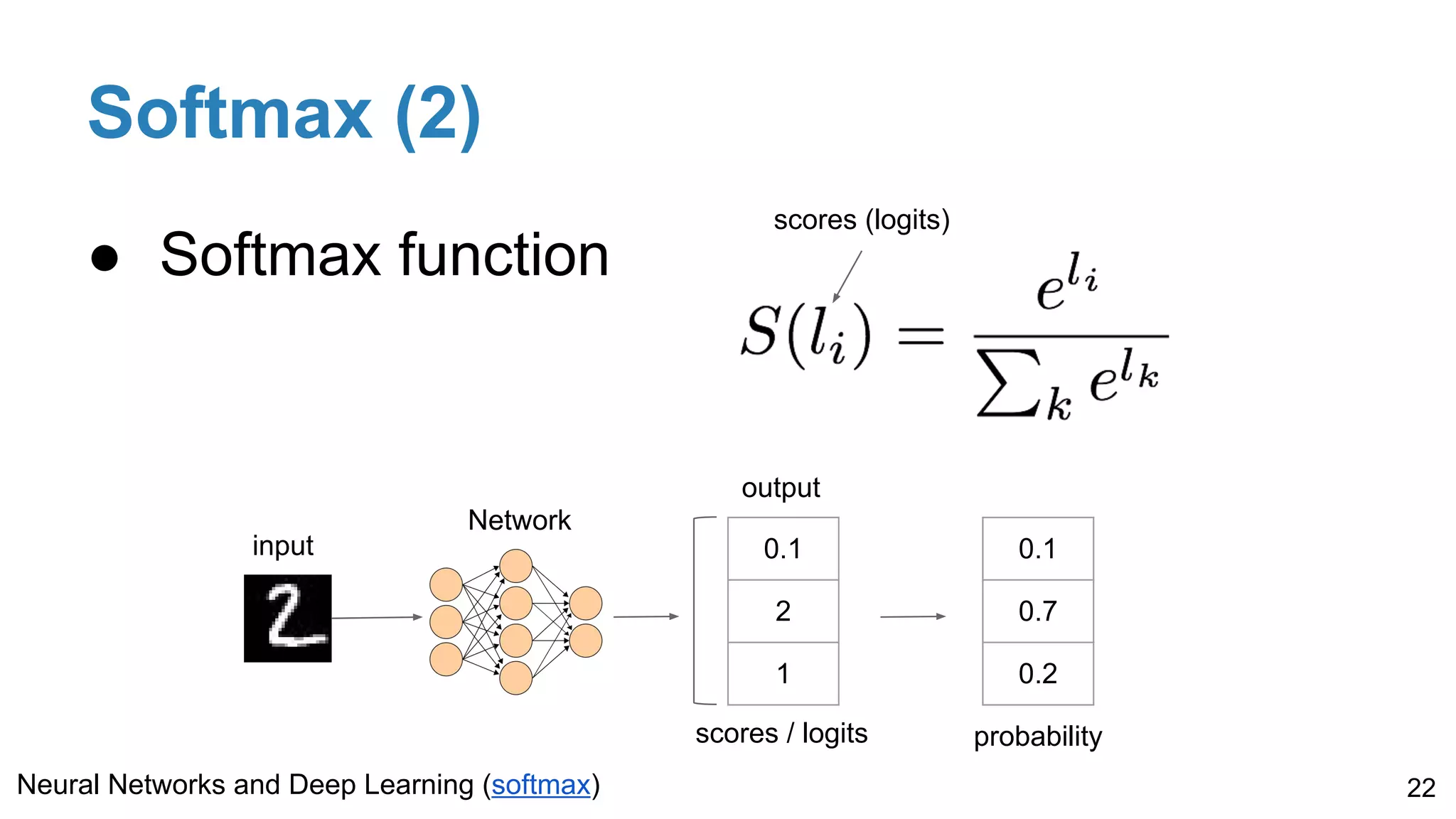
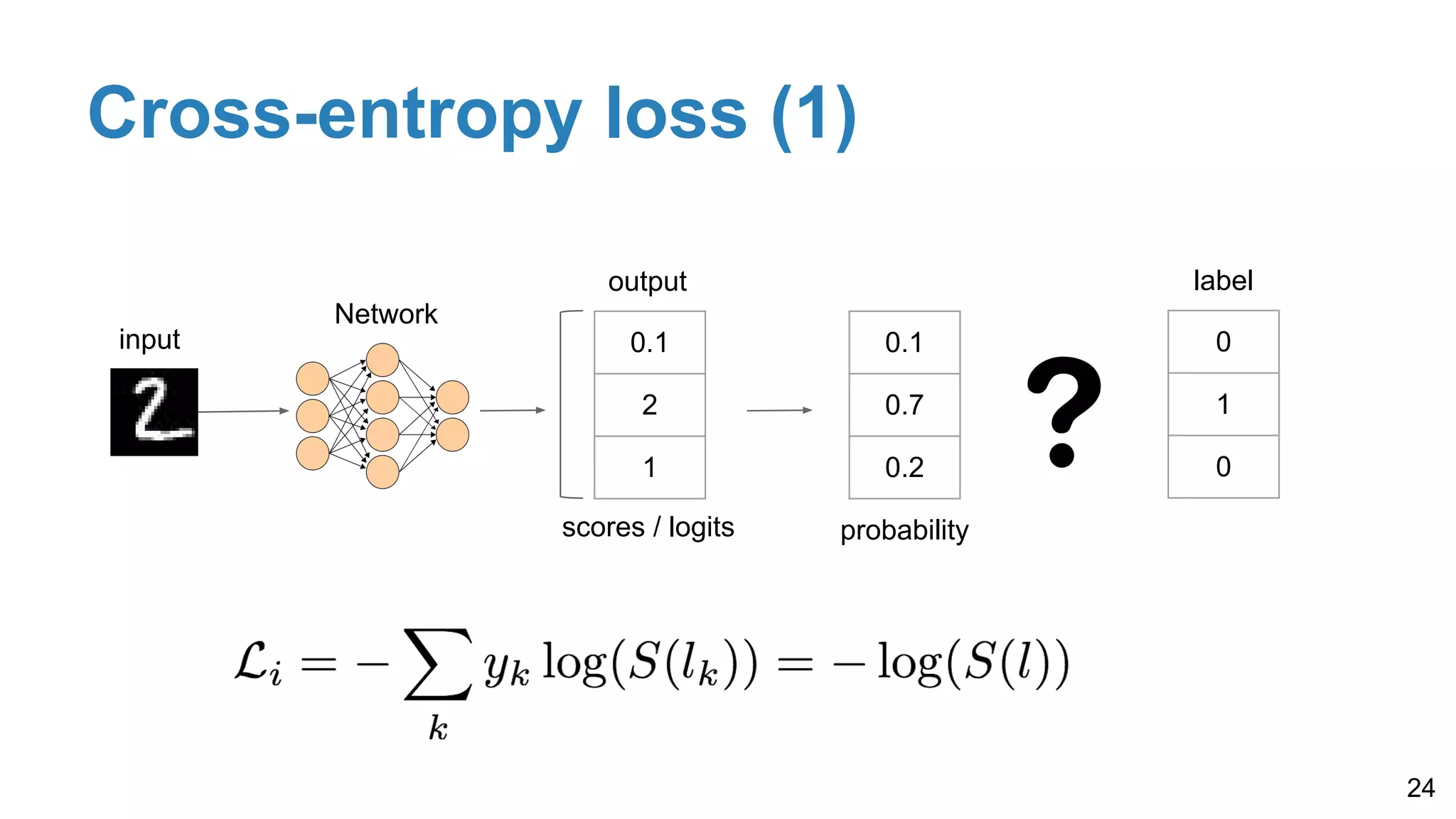
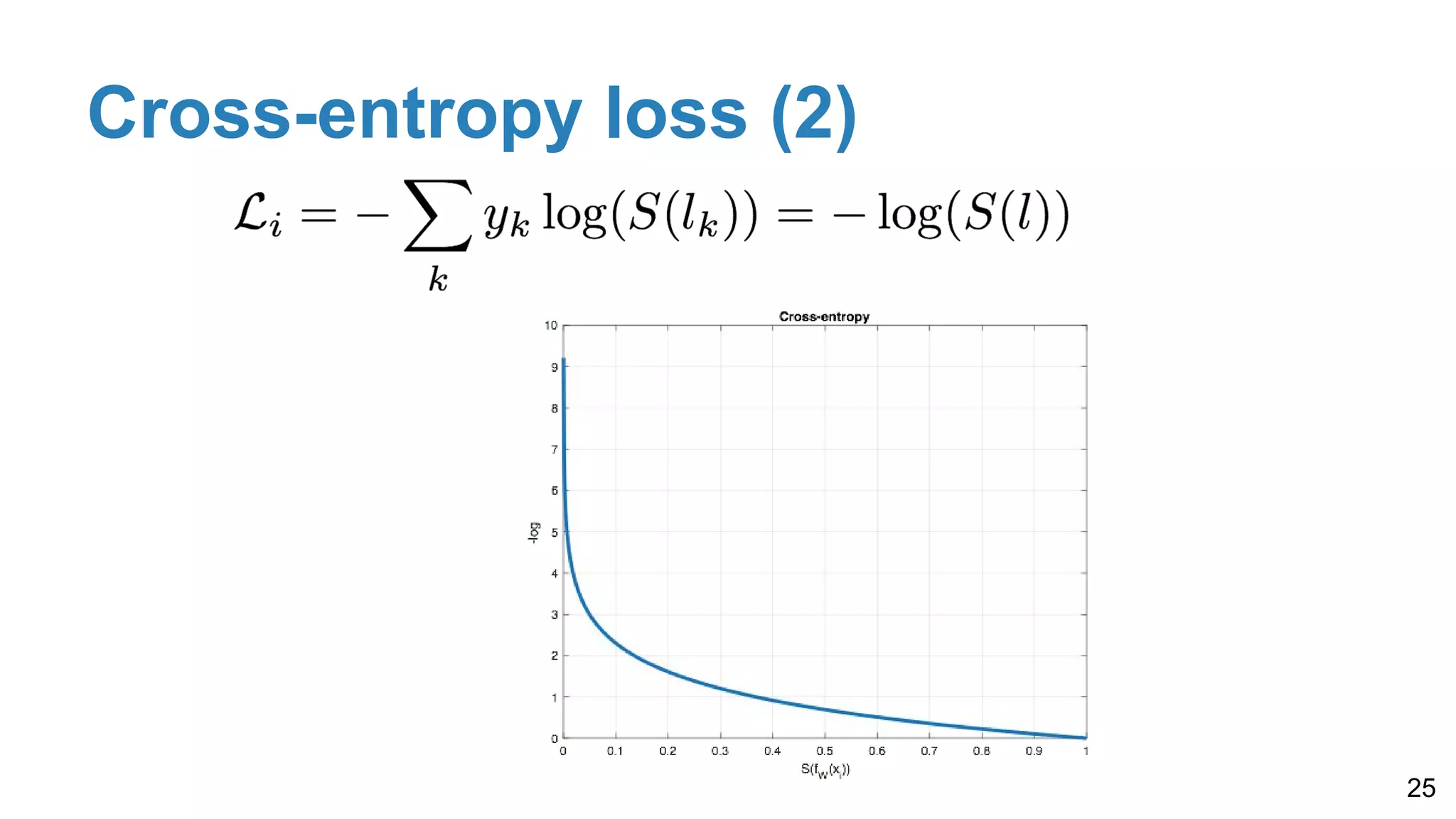
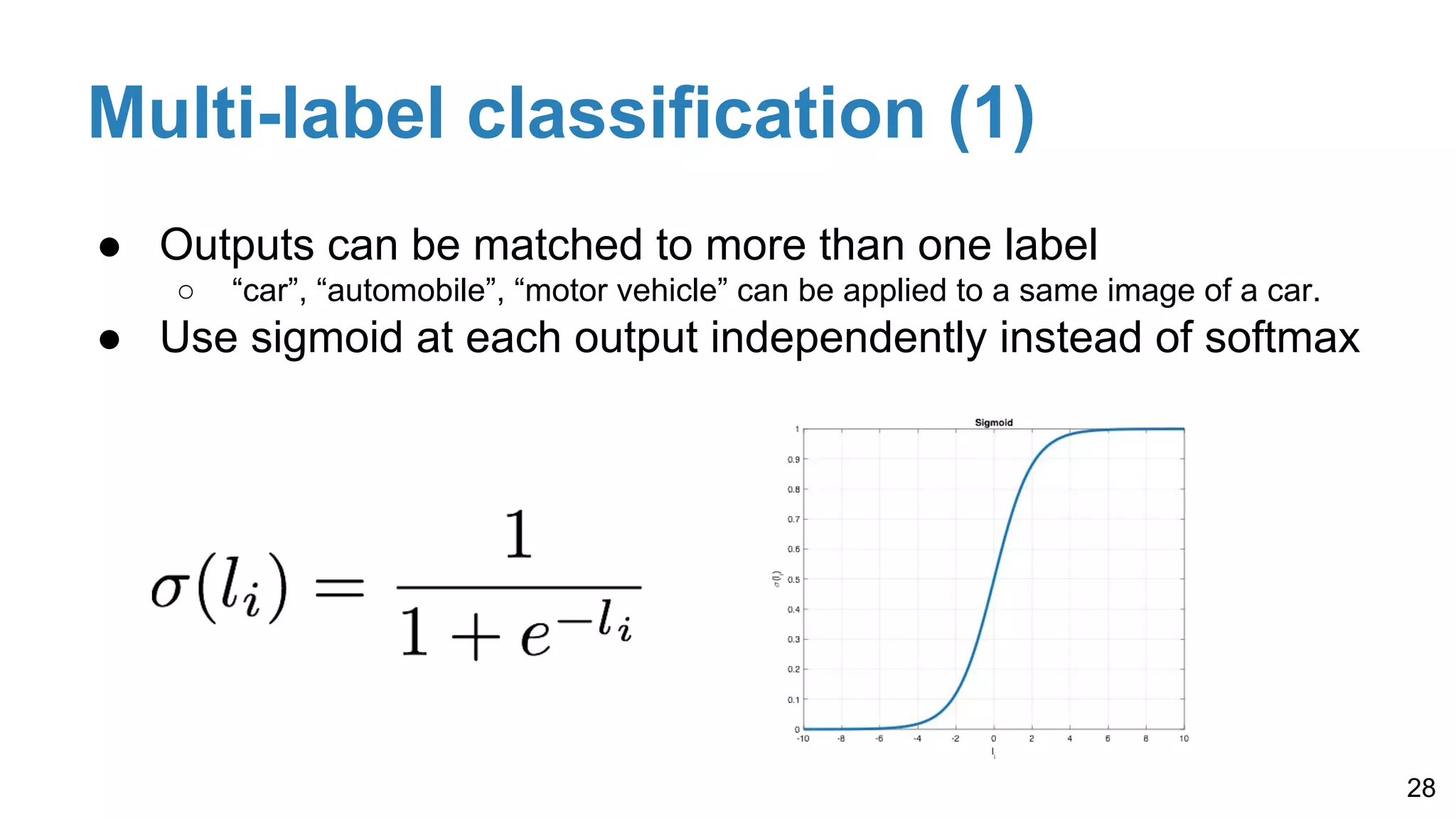
Details on softmax for probability conversion, one-hot encoding for labels, and cross-entropy loss for improved performance in classification tasks, including multi-label scenarios.
Discusses regularization techniques (L1 and L2) to control network capacity and prevent overfitting.
Presents an example comparing cross-entropy loss with classification accuracy to demonstrate advantages in performance evaluation.
Final slides provide references to concepts discussed and open the floor for questions.






















































































