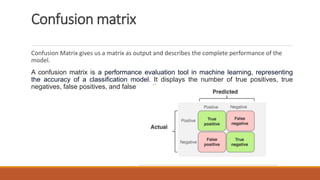
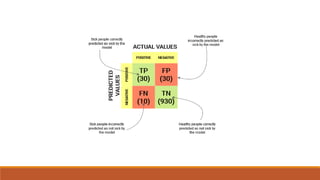
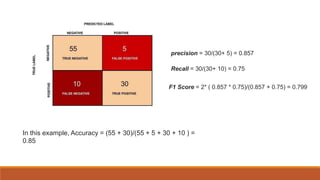
The document outlines key performance evaluation metrics for machine learning models, emphasizing classification accuracy, confusion matrix, precision, recall, and error rates. It explains the limitations of using accuracy alone in unbalanced datasets and introduces the F1 score as a comprehensive metric combining precision and recall. Other metrics discussed include mean absolute error (MAE) and mean squared error (MSE), which measure the accuracy of predictions relative to actual outcomes.









































![PERFORMANCE_PREDICTION__PARAMETERS[1].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/performancepredictionparameters1-240130171305-9f984922-thumbnail.jpg?width=640&height=640&fit=bounds)




















