
Downloaded 46 times







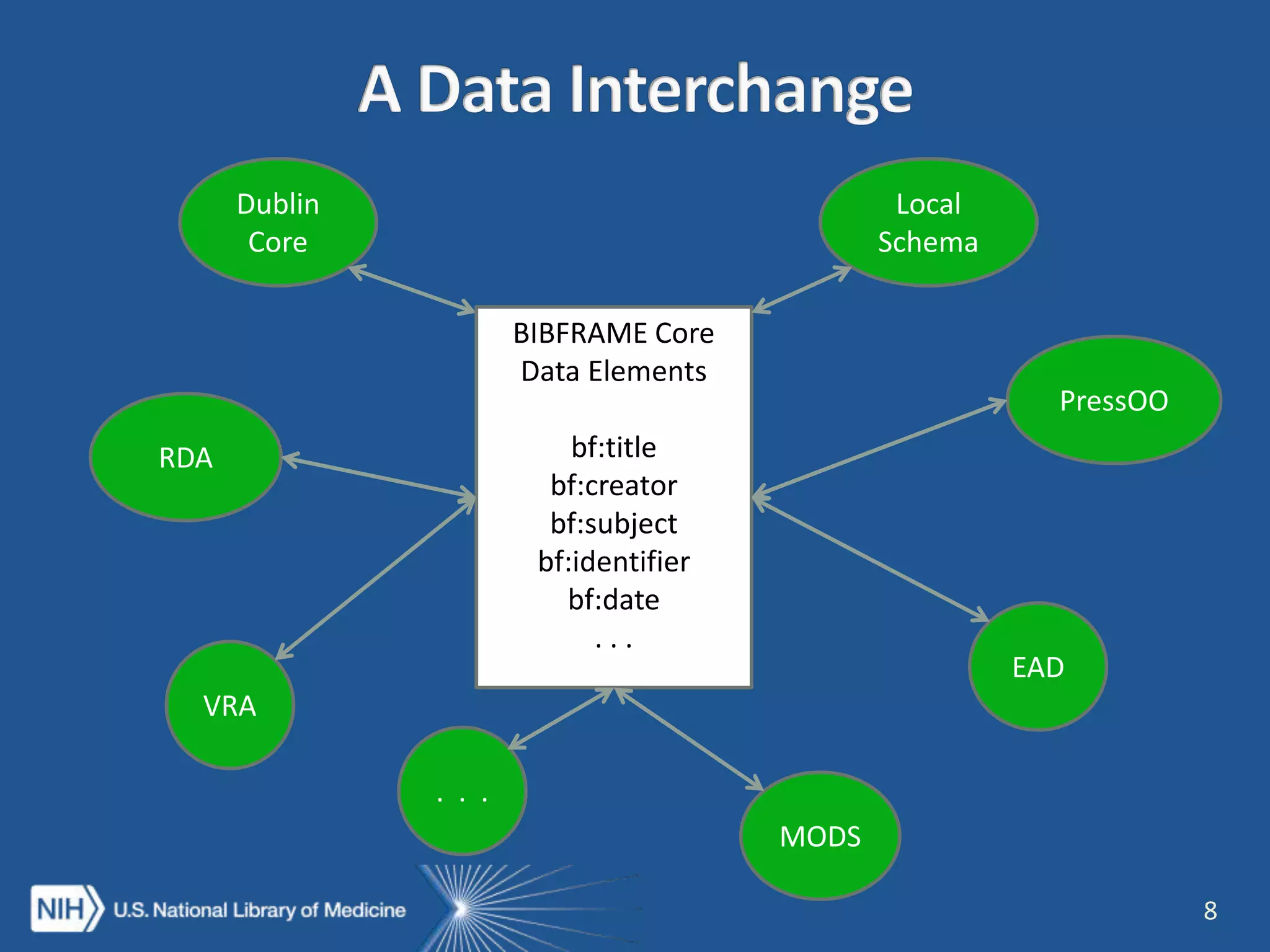




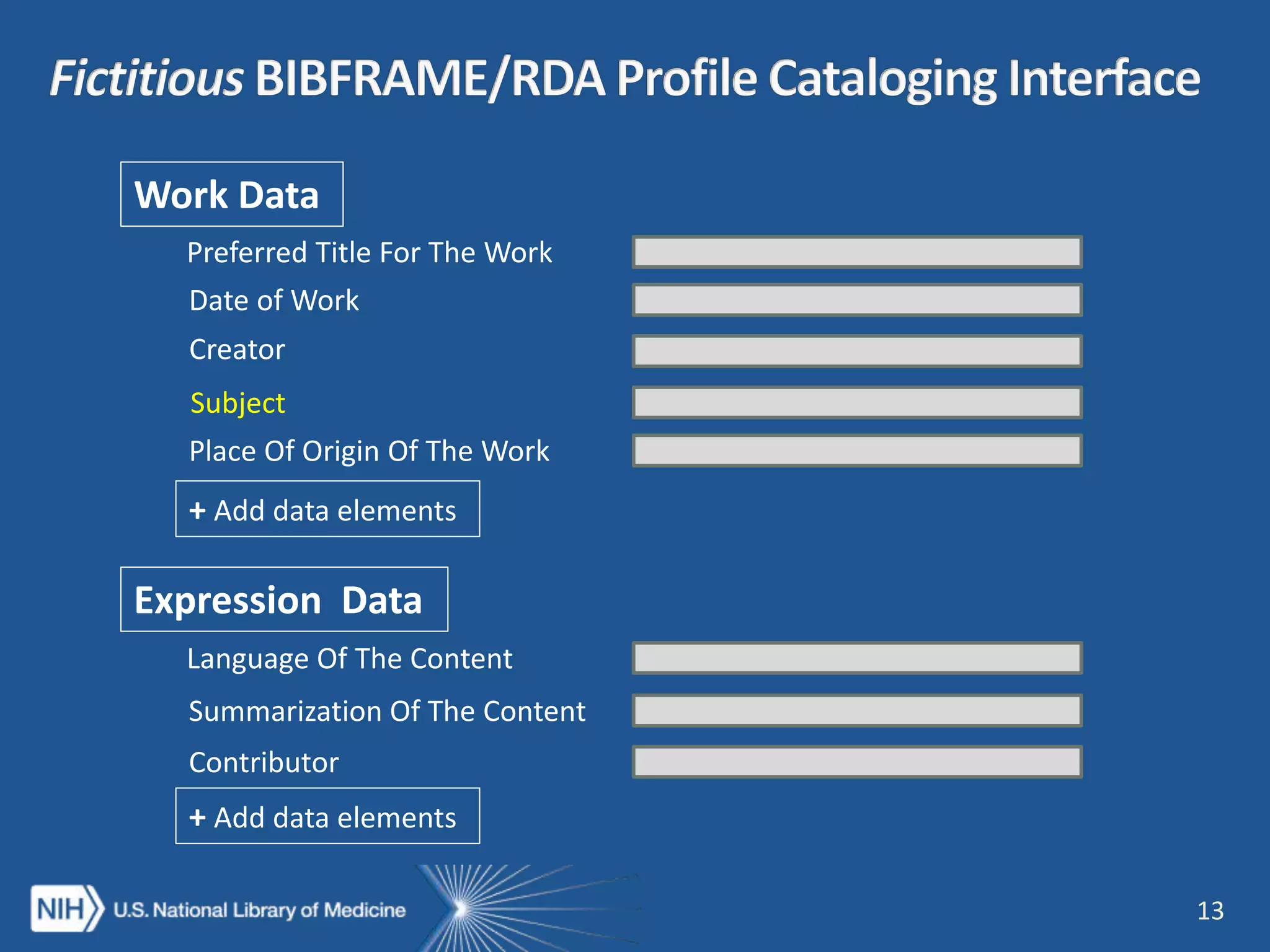
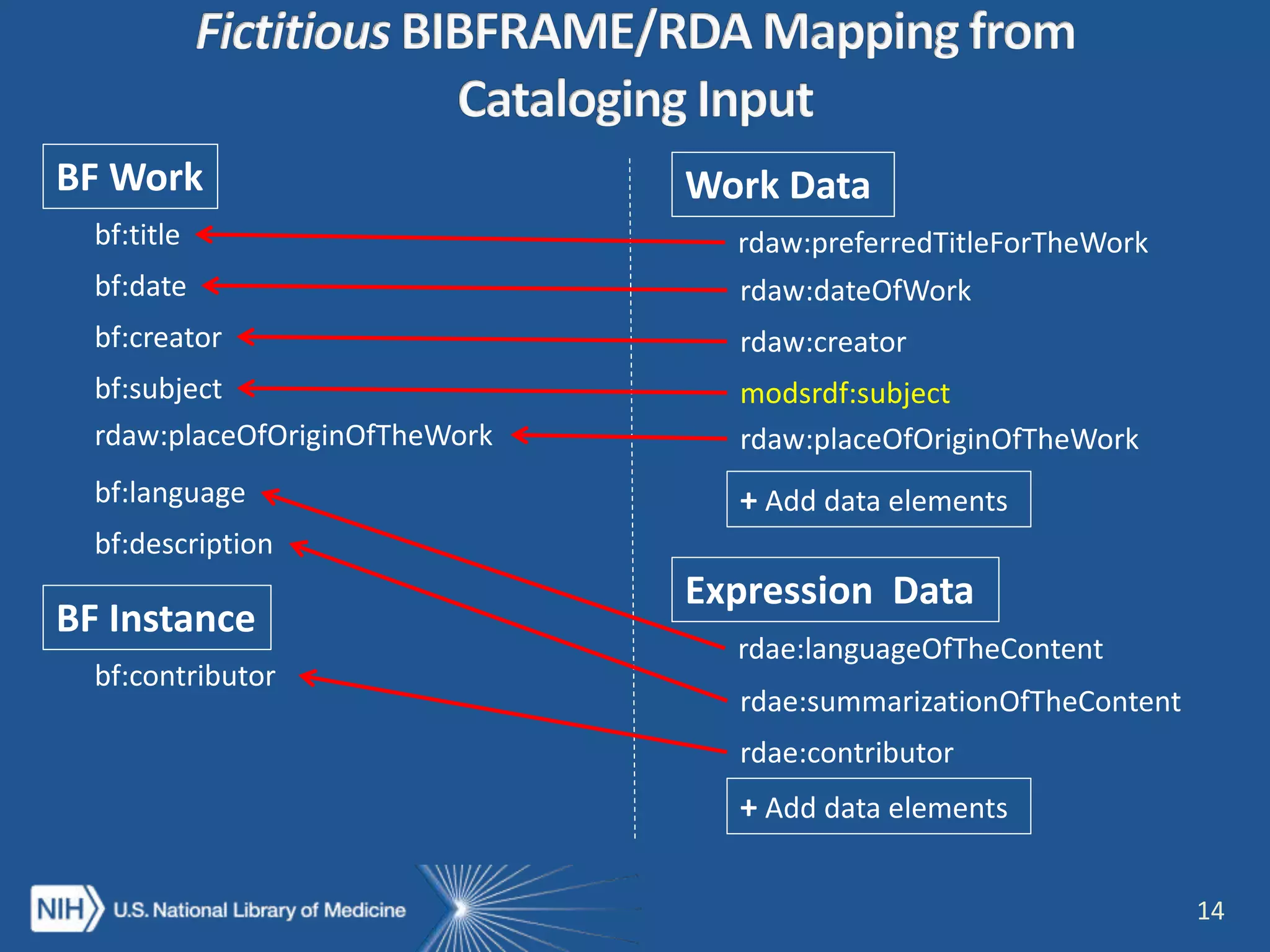
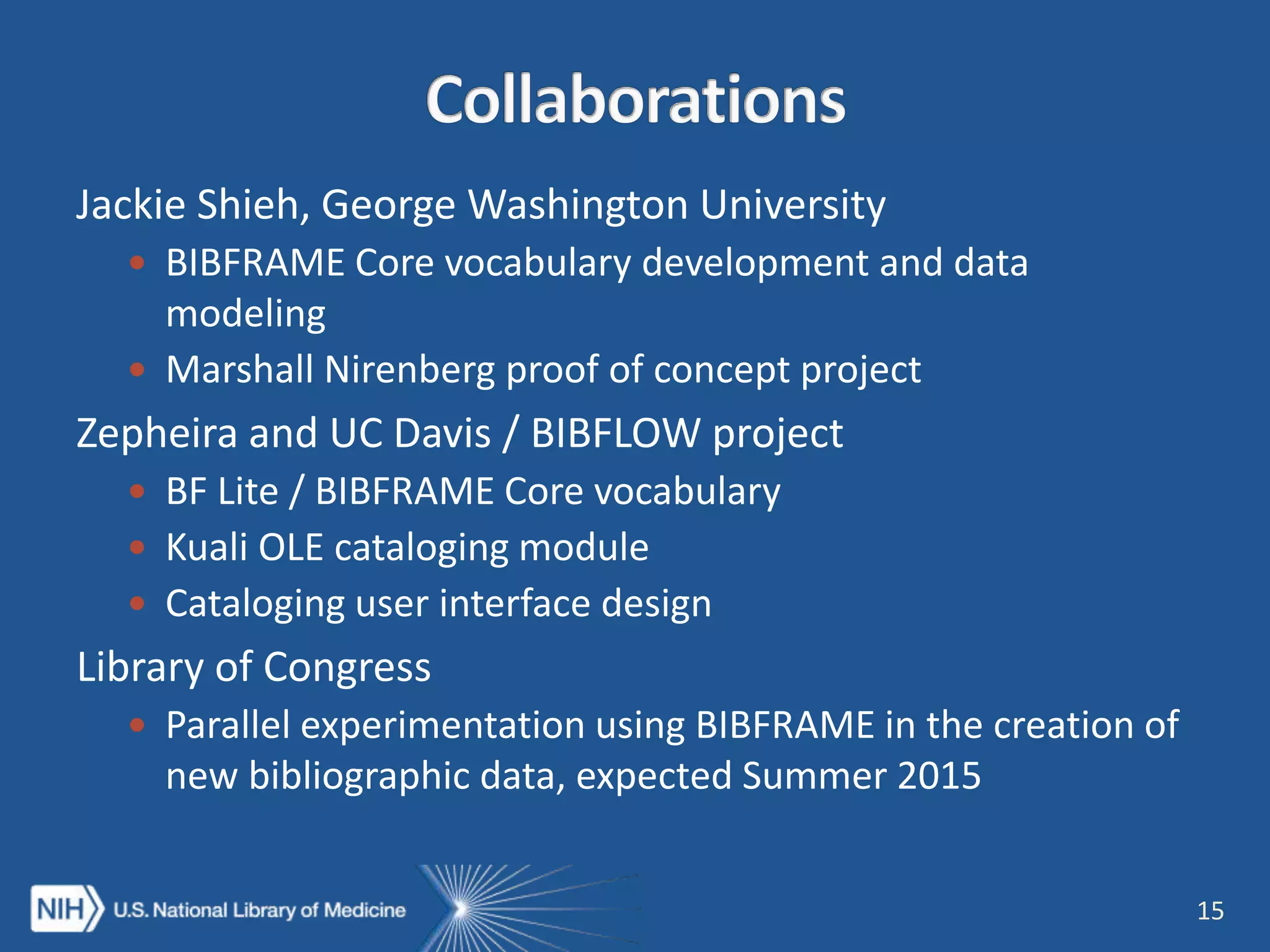




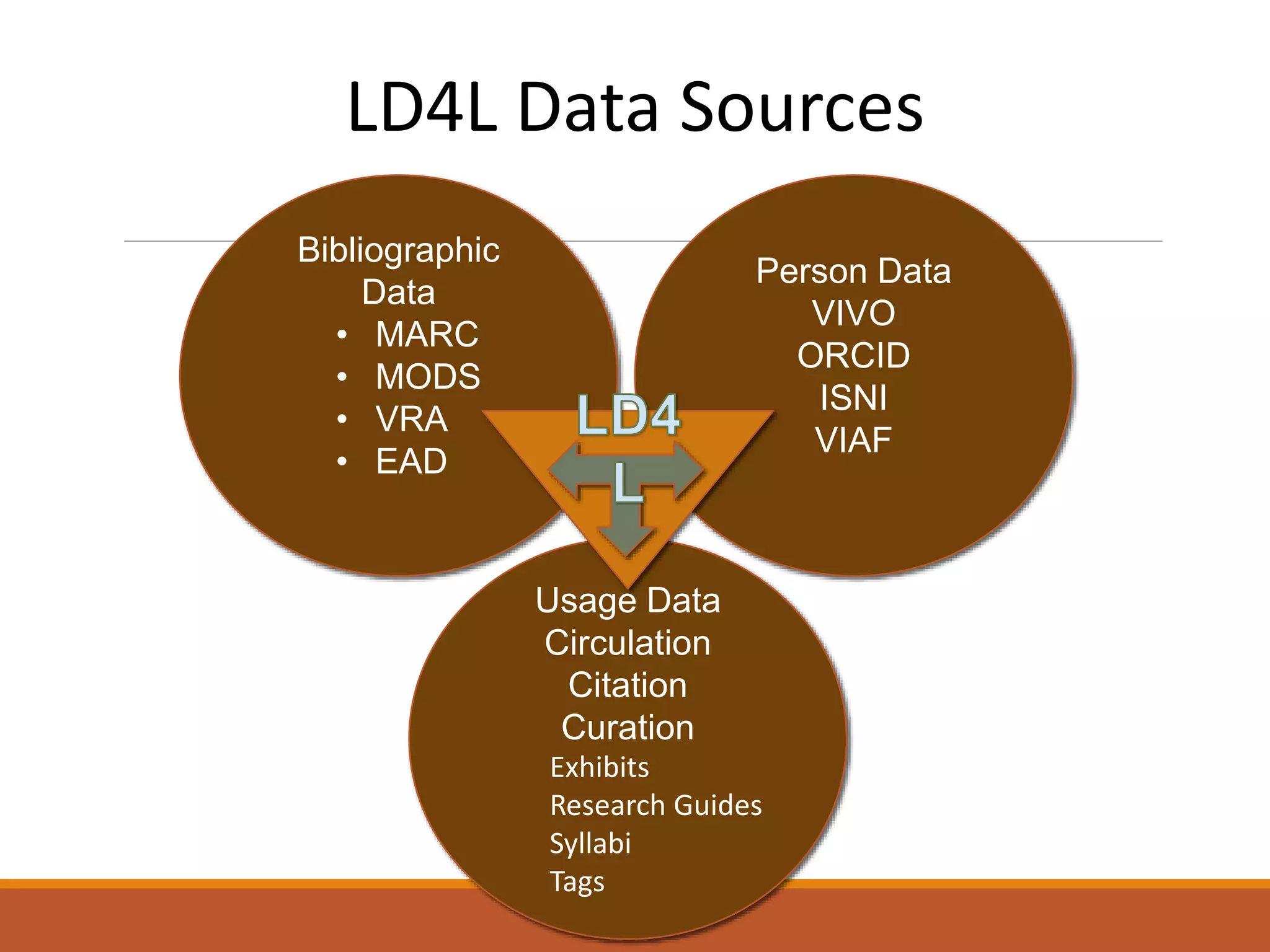

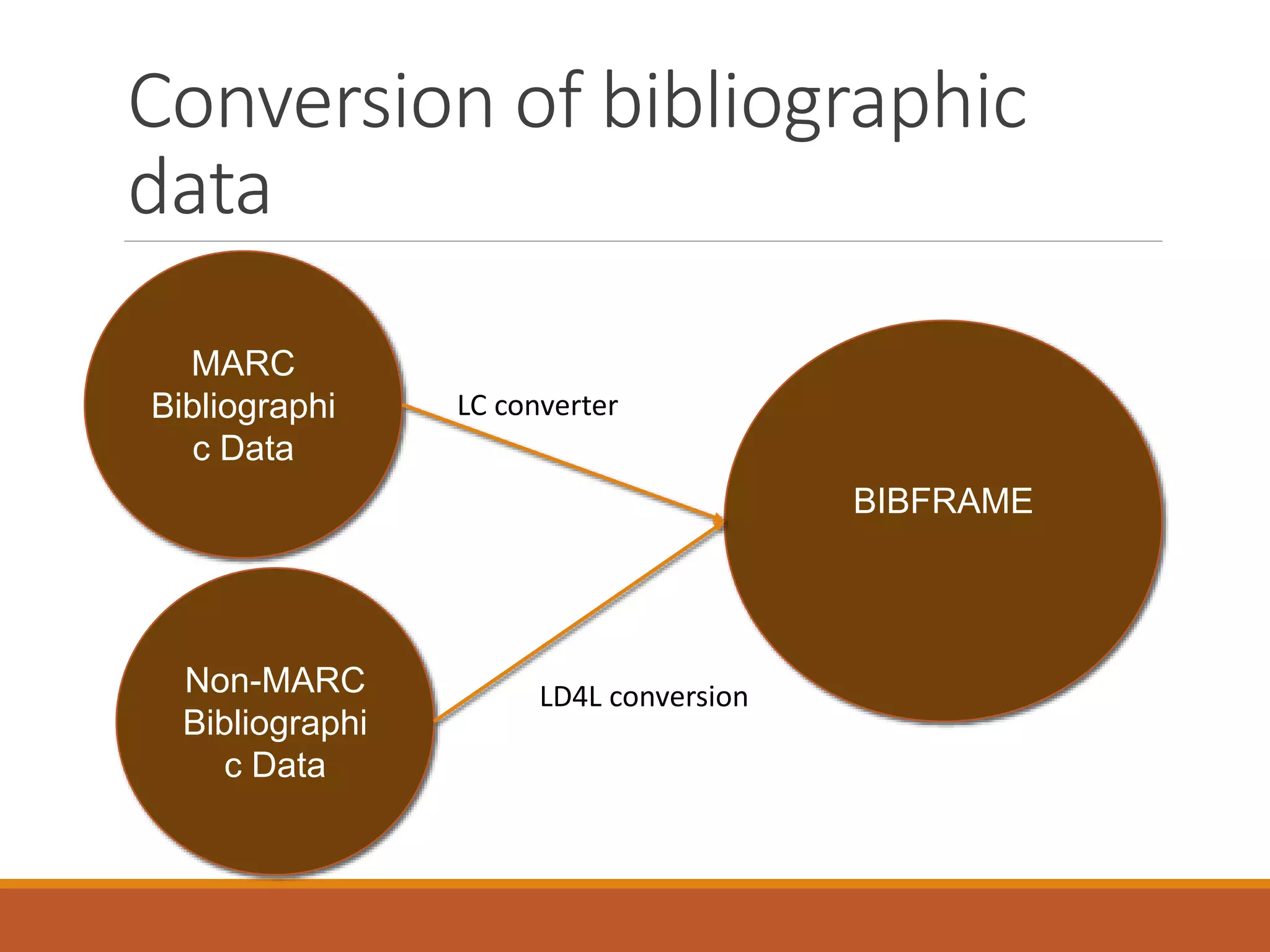



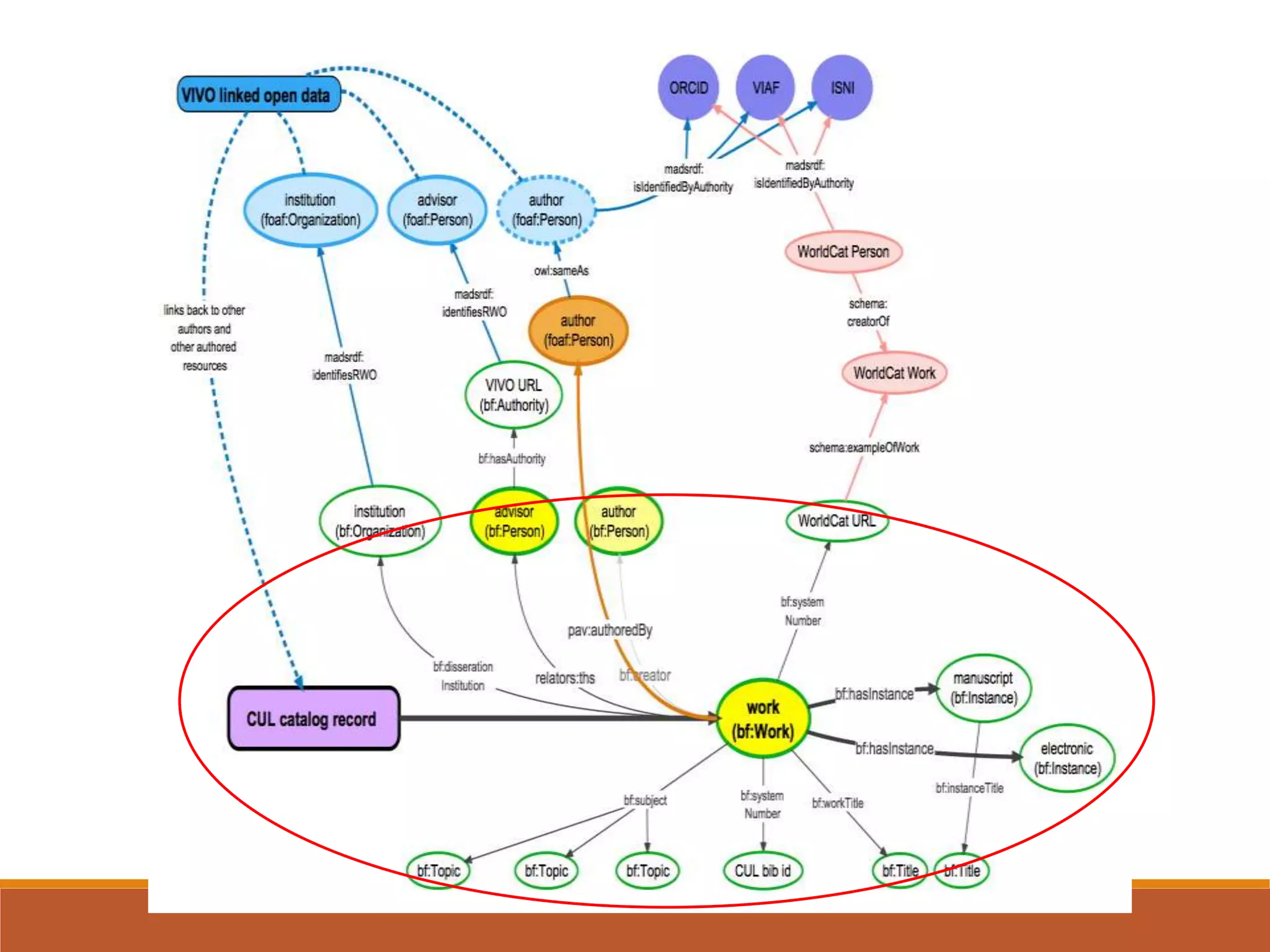
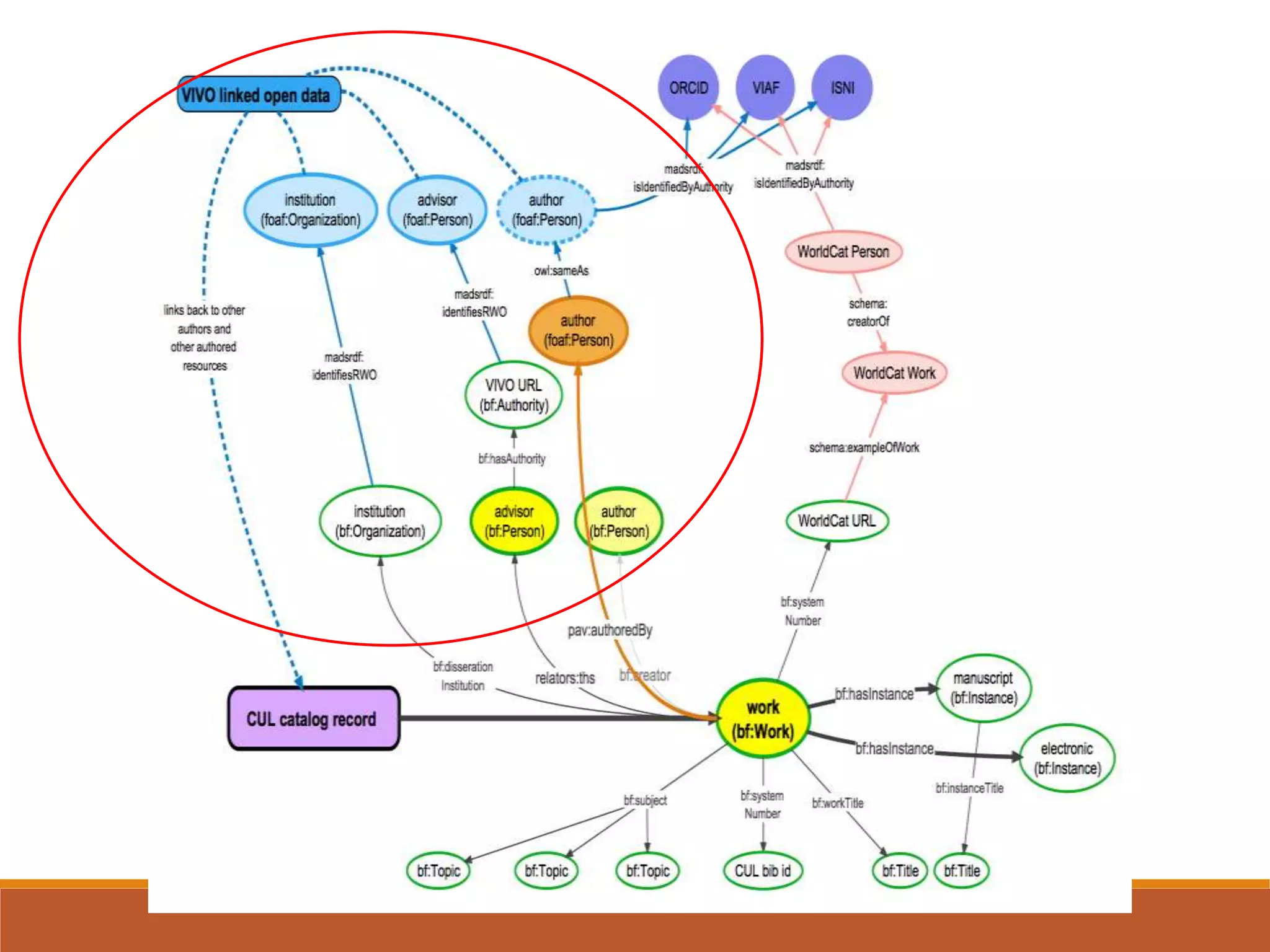
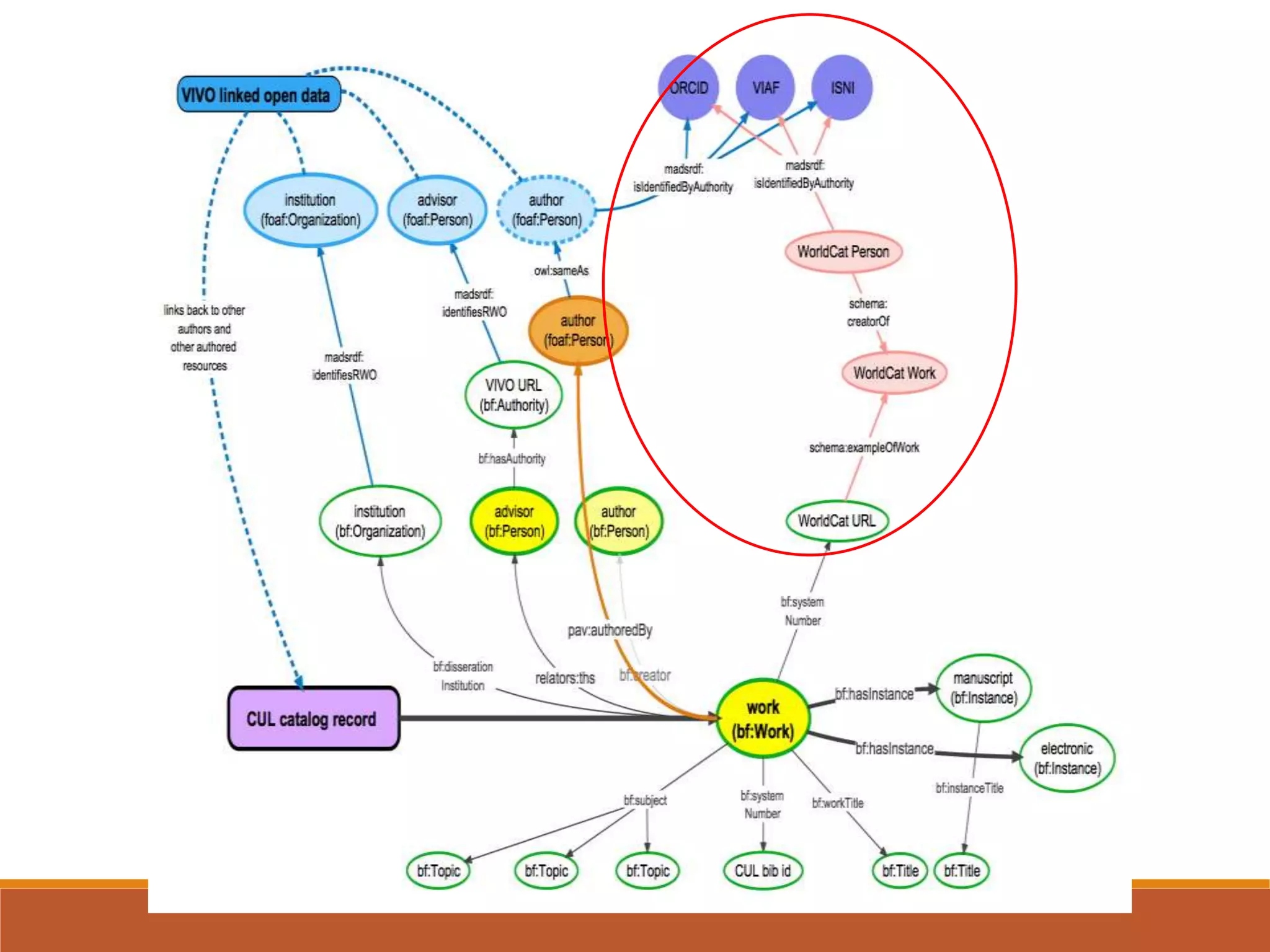

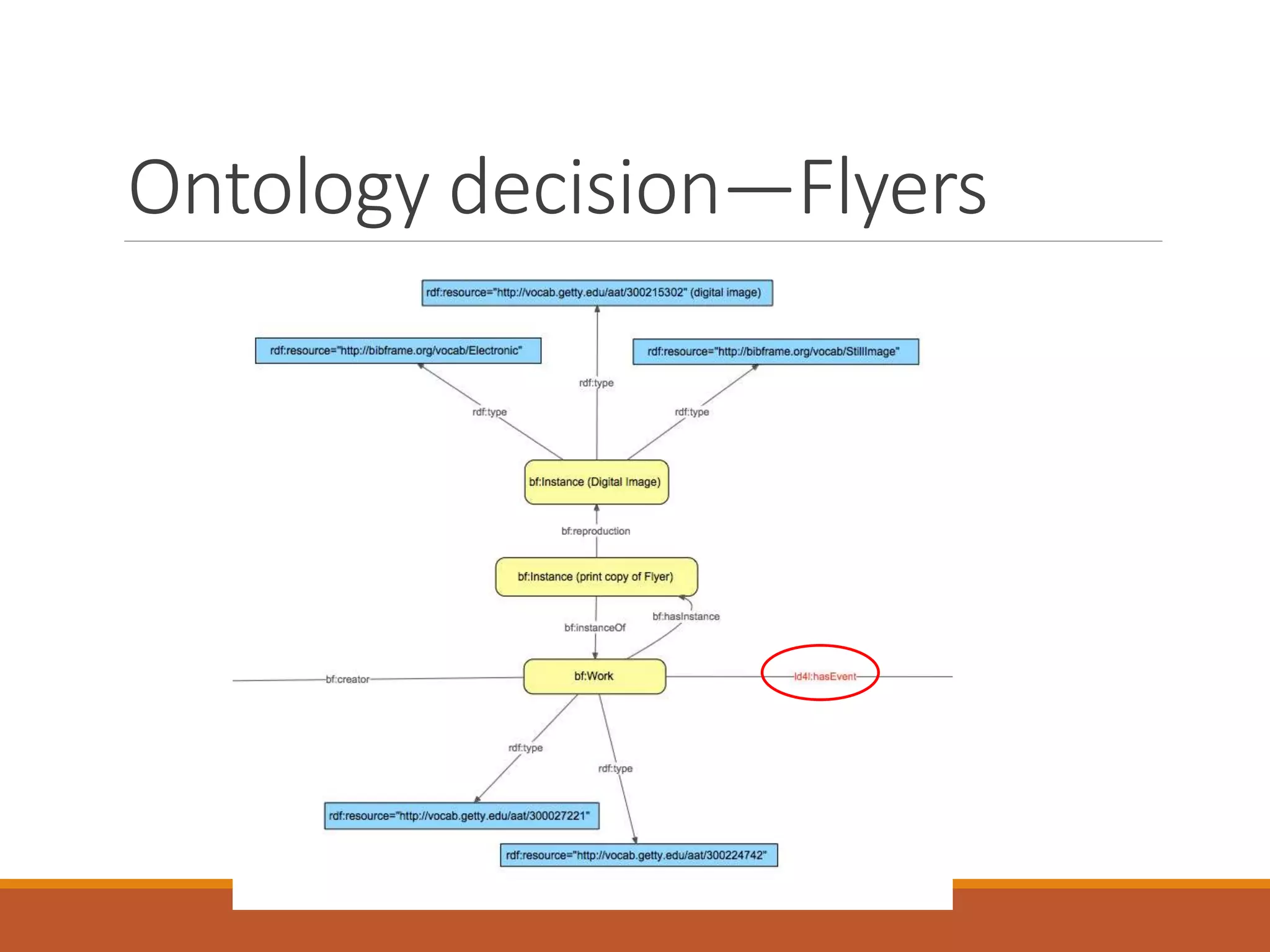
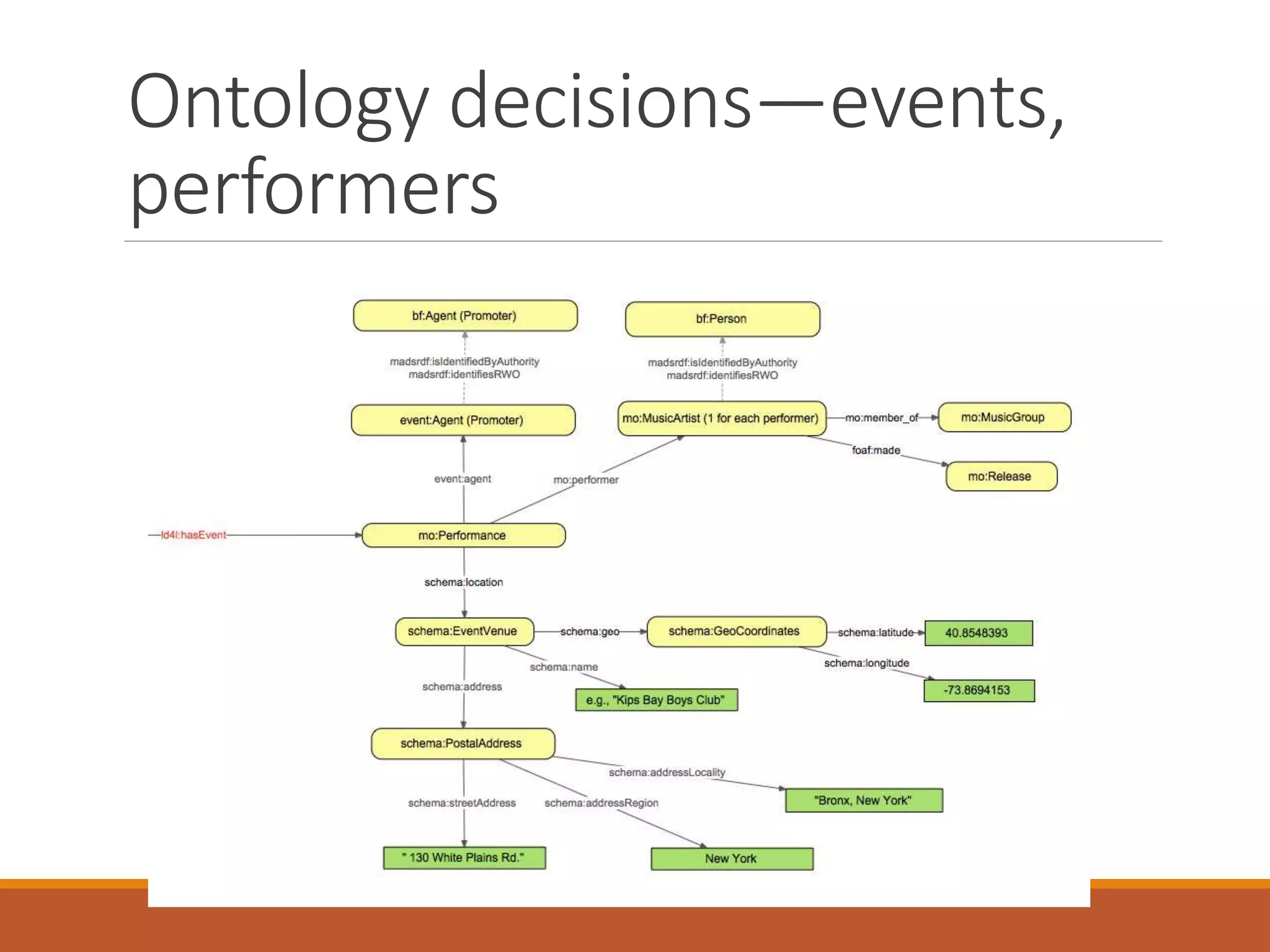











The NISO webinar on April 8, 2015, discussed early adopters' experiences with the BibFrame model, emphasizing its flexibility and modular approach to bibliographic data. Presenters outlined the development of a core BibFrame vocabulary to enhance interoperability across various metadata standards and community engagement. The session also highlighted ongoing collaborations to improve cataloging user interfaces and the importance of converting existing data into a linked data format for broader discoverability.























































































