Download as PDF, PPTX


![Increasingly connected world
!3
Internet of Things
30 B connected devices by 2020
Health Care
153 Exabytes (2013) -> 2314 Exabytes
(2020)
Machine Data
40% of digital universe by 2020
Connected Vehicles
Data transferred per vehicle per month
4 TB -> 10 TB
Digital Assistants (Predictive Analytics)
$2B (2012) -> $6.5B (2019) [1]
Siri/Cortana/Google Now
Augmented/Virtual Reality
$150B by 2020 [2]
Oculus/HoloLens/Magic Leap
Ñ
+
>](https://image.slidesharecdn.com/apachepulsaroverview-190228024057/85/Apache-Pulsar-Overview-3-320.jpg)











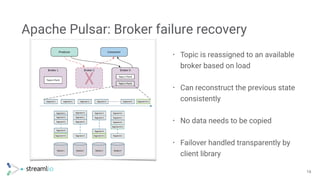






































Apache Pulsar is a cloud-native messaging and streaming platform designed to handle large-scale data ingestion and processing with low latency and high throughput. It features a flexible architecture that decouples storage from processing, enabling seamless scalability and fault tolerance, while supporting multi-tenancy and various data processing models. Pulsar offers significant advantages over legacy systems, including unified messaging models and efficient failure recovery mechanisms.












































![[AerospikeRoadshow] Apache Pulsar Unifies Streaming and Messaging for Real-Ti...](https://cdn.slidesharecdn.com/ss_thumbnails/aerospikeroadshowapachepulsarunifiesstreamingandmessagingforreal-timedata2-221103174214-18ce3fa2-thumbnail.jpg?width=640&height=640&fit=bounds)



































