Download to read offline
![Cassandra Performance Evaluation with Compression
Schubert Zhang, May.2010
schubert.zhang@gmail.com
The current implementation of Cassandra’s storage layer and indexing mechanism
only allow compression at row level.
Column Family Row Serialization Structure:
1. The old structure:
Len HashCount
bloom filter BitSet
(int) (int)
index size int
FirstColumName LastColumName Offset (long) Block Width
index of block 0
(Len(short)+name) (Len(short)+name) (0 for first block) (long)
index of block 1
localDeletionTime markedForDeleteAt
deletion meta
(int) (long)
column count int
column block 0
(uncompressed) Column0 Column1 Column2 Column3
column block 1
(uncompressed) deleteMark timestamp value
(bool) (long) (byte[])
2. The new structure (to support compression)
The new structure is appropriate for both old (uncompressed) and new (compressed)
format.
format (int): -1 (old format), 0 (new, LZO compressed), 1(new, GZ compressed), 2(new, uncompressed)
Len HashCount
bloom filter BitSet
(int) (int)
localDeletionTime markedForDeleteAt
deletion meta
(int) (long)
column count int
column block 0
(compressed or not) Column0 Column1 Column2 Column3
column block 1
(compressed or not) deleteMark timestamp value
(bool) (long) (byte[])
index size int
FirstColumName LastColumName Offset (long) Block Width Size on Disk
index of block 0
(Len(short)+name) (Len(short)+name) (0 for first block) (long) (int)
index of block 1
index size’
If the first int (format) is -1, the following structure will be same as “The
old structure”, except the “index of block” will use the new one.
1](https://image.slidesharecdn.com/cassandra-performance-evaluation-with-compression-110612030054-phpapp01/85/Cassandra-Compression-and-Performance-Evaluation-1-320.jpg)
![Cassandra Performance Evaluation with Compression
Schubert Zhang, May.2010
schubert.zhang@gmail.com
The current implementation of Cassandra’s storage layer and indexing mechanism
only allow compression at row level.
Column Family Row Serialization Structure:
1. The old structure:
Len HashCount
bloom filter BitSet
(int) (int)
index size int
FirstColumName LastColumName Offset (long) Block Width
index of block 0
(Len(short)+name) (Len(short)+name) (0 for first block) (long)
index of block 1
localDeletionTime markedForDeleteAt
deletion meta
(int) (long)
column count int
column block 0
(uncompressed) Column0 Column1 Column2 Column3
column block 1
(uncompressed) deleteMark timestamp value
(bool) (long) (byte[])
2. The new structure (to support compression)
The new structure is appropriate for both old (uncompressed) and new (compressed)
format.
format (int): -1 (old format), 0 (new, LZO compressed), 1(new, GZ compressed), 2(new, uncompressed)
Len HashCount
bloom filter BitSet
(int) (int)
localDeletionTime markedForDeleteAt
deletion meta
(int) (long)
column count int
column block 0
(compressed or not) Column0 Column1 Column2 Column3
column block 1
(compressed or not) deleteMark timestamp value
(bool) (long) (byte[])
index size int
FirstColumName LastColumName Offset (long) Block Width Size on Disk
index of block 0
(Len(short)+name) (Len(short)+name) (0 for first block) (long) (int)
index of block 1
index size’
If the first int (format) is -1, the following structure will be same as “The
old structure”, except the “index of block” will use the new one.
1](https://image.slidesharecdn.com/cassandra-performance-evaluation-with-compression-110612030054-phpapp01/75/Cassandra-Compression-and-Performance-Evaluation-1-2048.jpg)
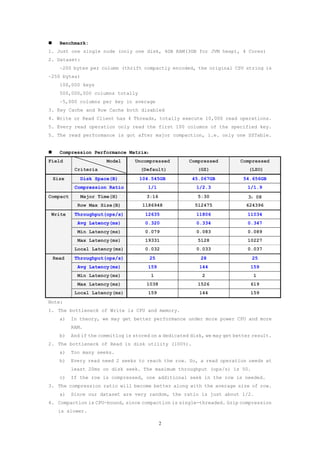
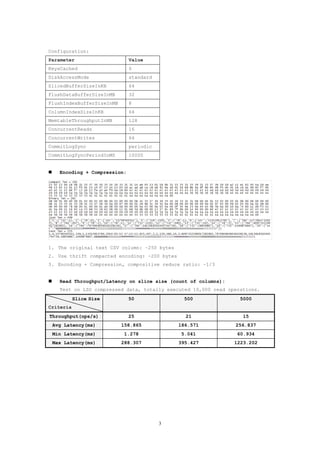
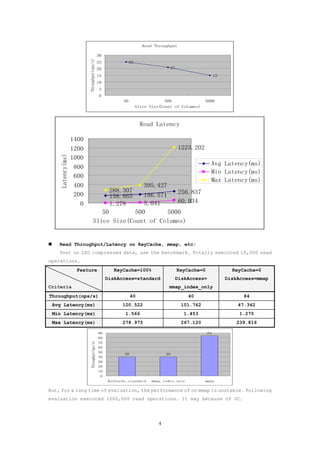
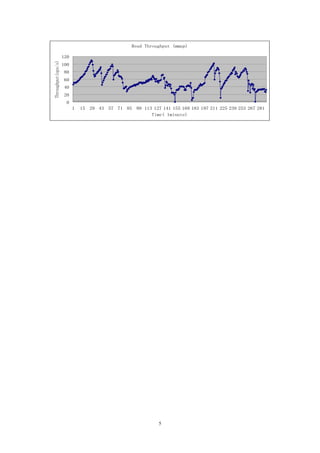

This document evaluates the performance of Cassandra's storage layer with a focus on compression mechanisms at the row level. It outlines the old and new column family row serialization structures, presents benchmarking results for both uncompressed and compressed data, and discusses performance metrics such as write/read throughput and latency. The document highlights key observations on bottlenecks in CPU, memory, and disk utility affecting performance outcomes.



































































































