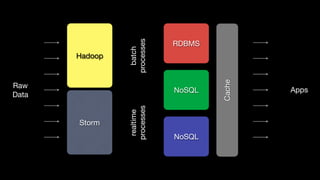
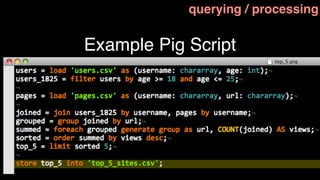
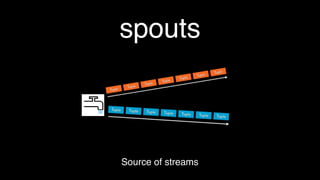
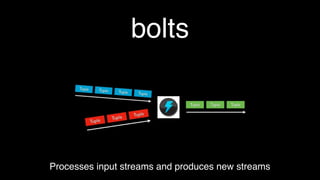
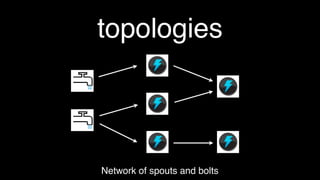
This document discusses tools for large scale data analysis. It begins by defining business value as anything that makes people more likely to give money or saves costs. It then discusses how data has outgrown local storage and requires scaling out to clusters and distributed systems. The document lists various systems that can be used for data ingestion, storage, querying, processing and output. It covers batch systems like Hadoop and real-time systems like Storm. It emphasizes that to generate business value, one needs to start analyzing big data from various sources like web logs, sensors and parse noise to find signals.