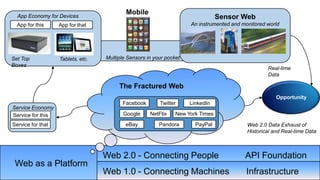
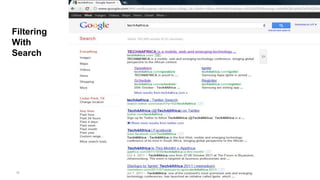
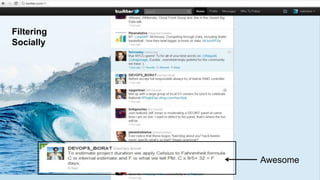
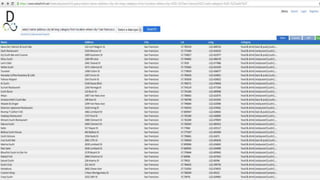
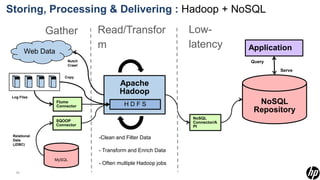
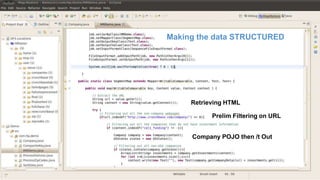
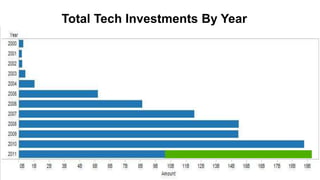
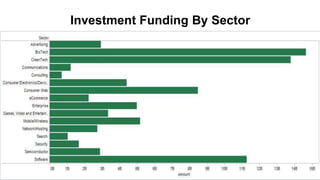
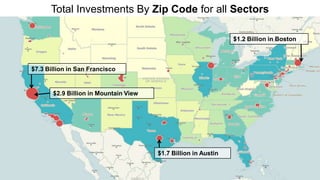
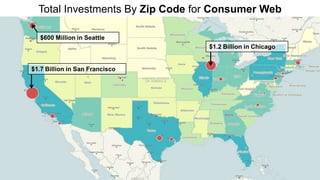
The document discusses big data and techniques for gathering, storing, processing, and delivering large amounts of data at scale. It covers using Apache Nutch to crawl web data, storing data in Apache Hadoop's distributed file system and processing it using MapReduce. For low-latency queries, it recommends column stores like Apache HBase or Apache Cassandra. The document also discusses using machine learning on historical data to build models for real-time decision making, and challenges of processing unstructured data like prose.