Downloaded 38 times




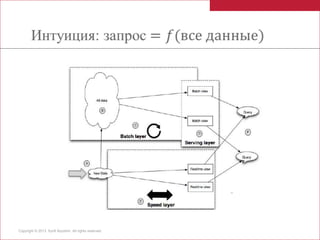






















Документ описывает практическое применение ламбда архитектуры в проекте компании Idexx Laboratories для обработки больших объемов ветеринарных данных в реальном времени. Основное внимание уделяется использованию технологий, таких как Twitter Storm, Redis и Hadoop для достижения масштабируемости и надежности системы. В документе также упоминаются бизнес-цели, проблемы с данными и ключевые компоненты системы.












































































