Download as PDF, PPTX










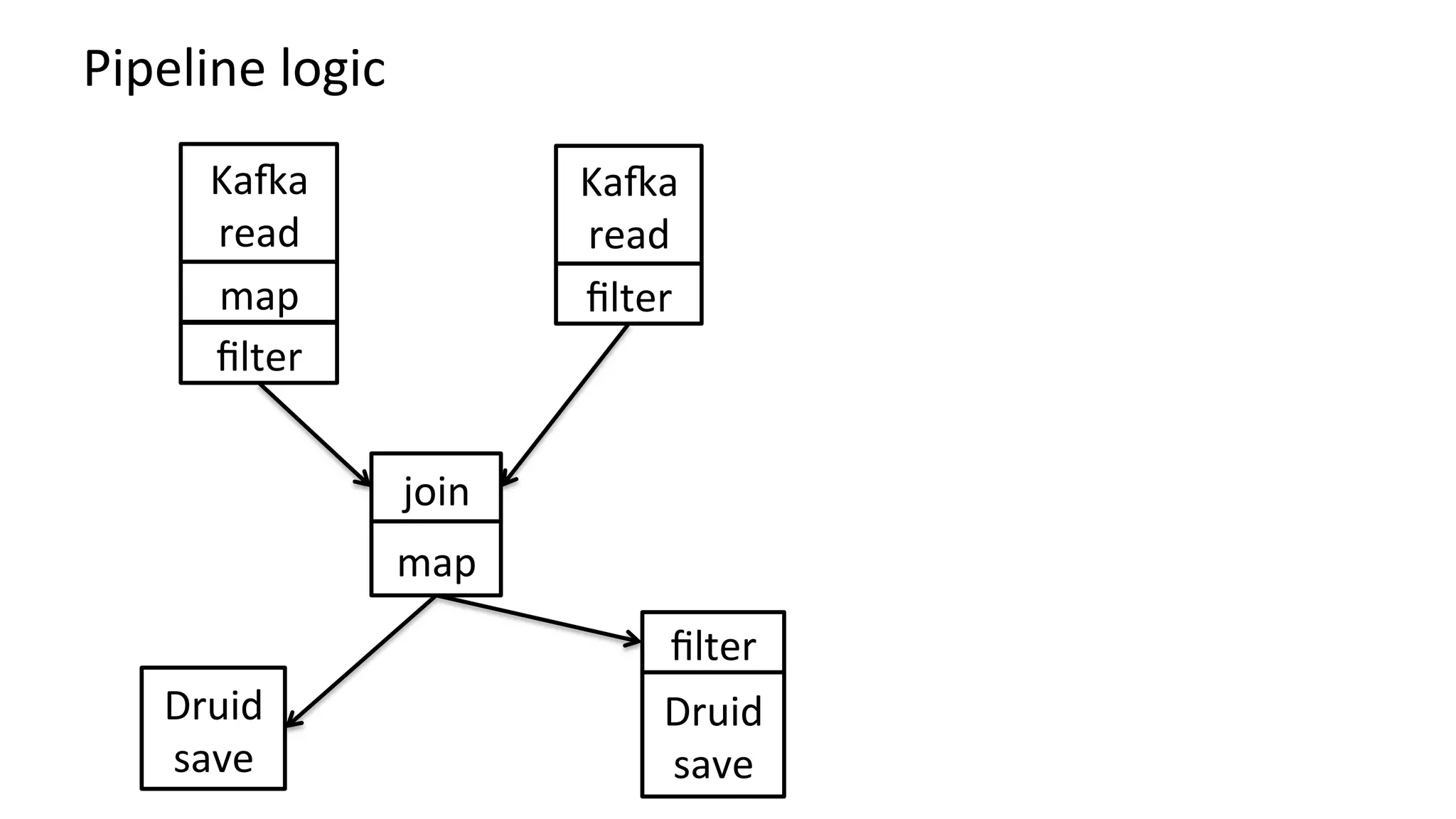



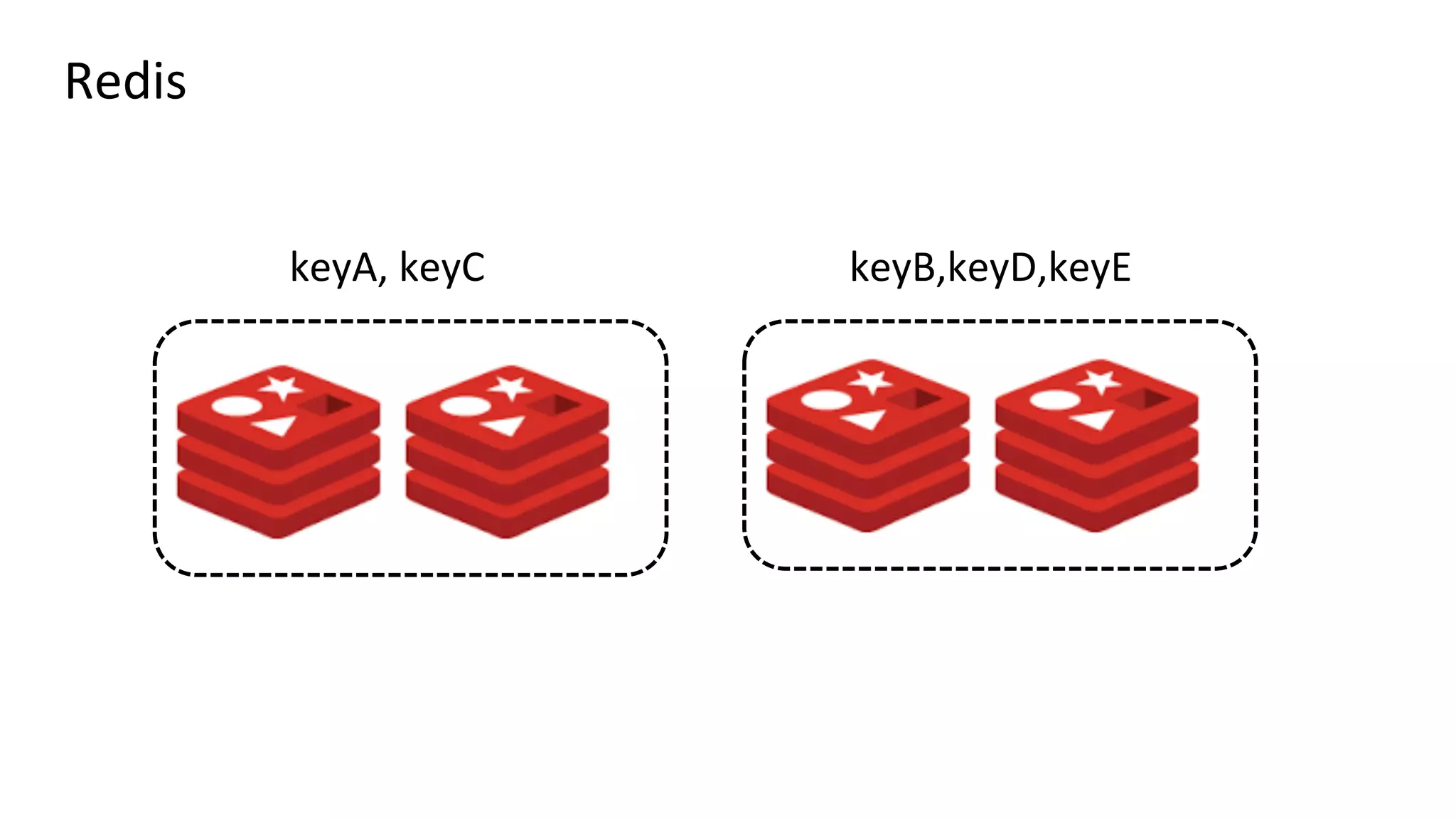




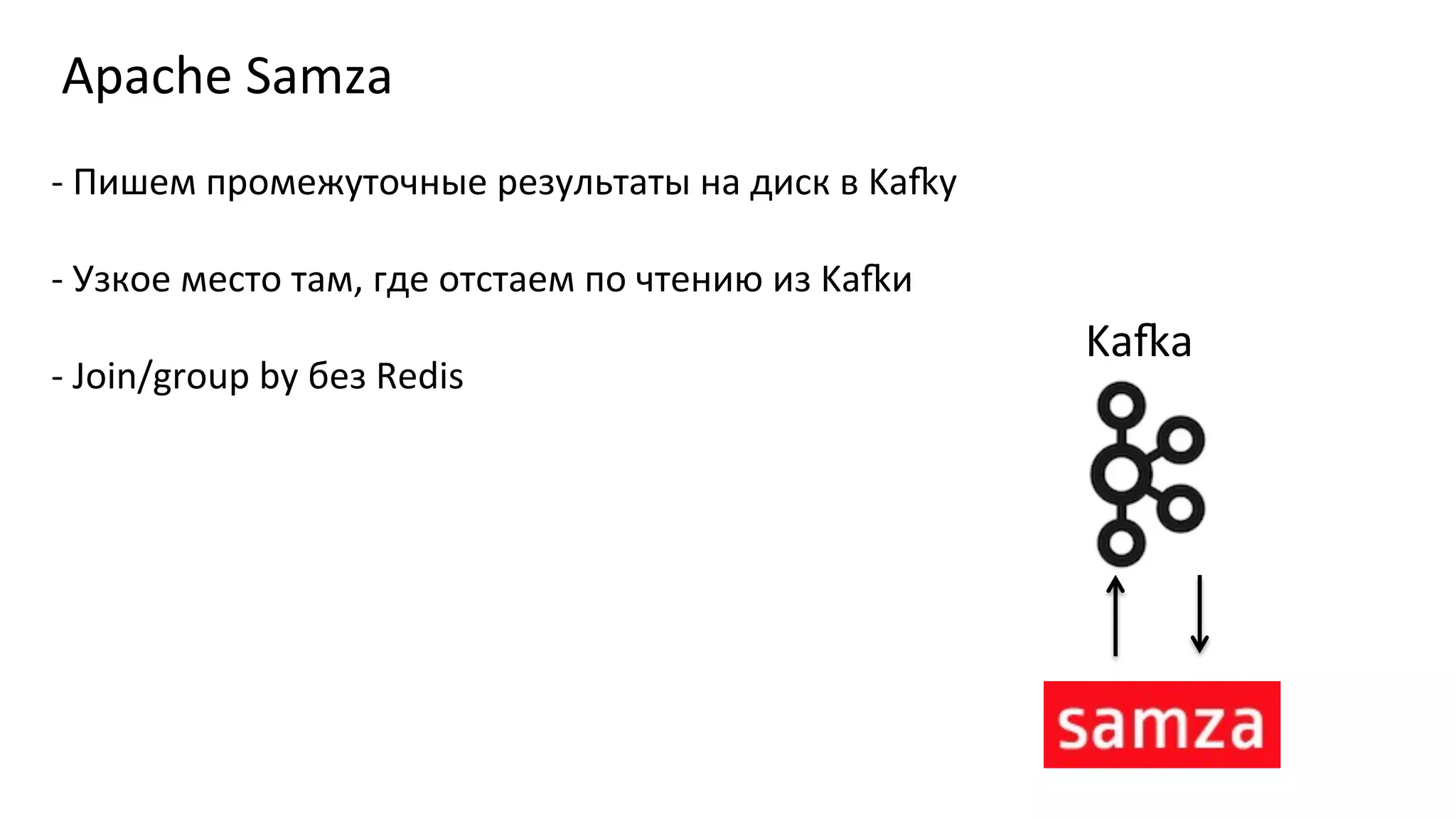


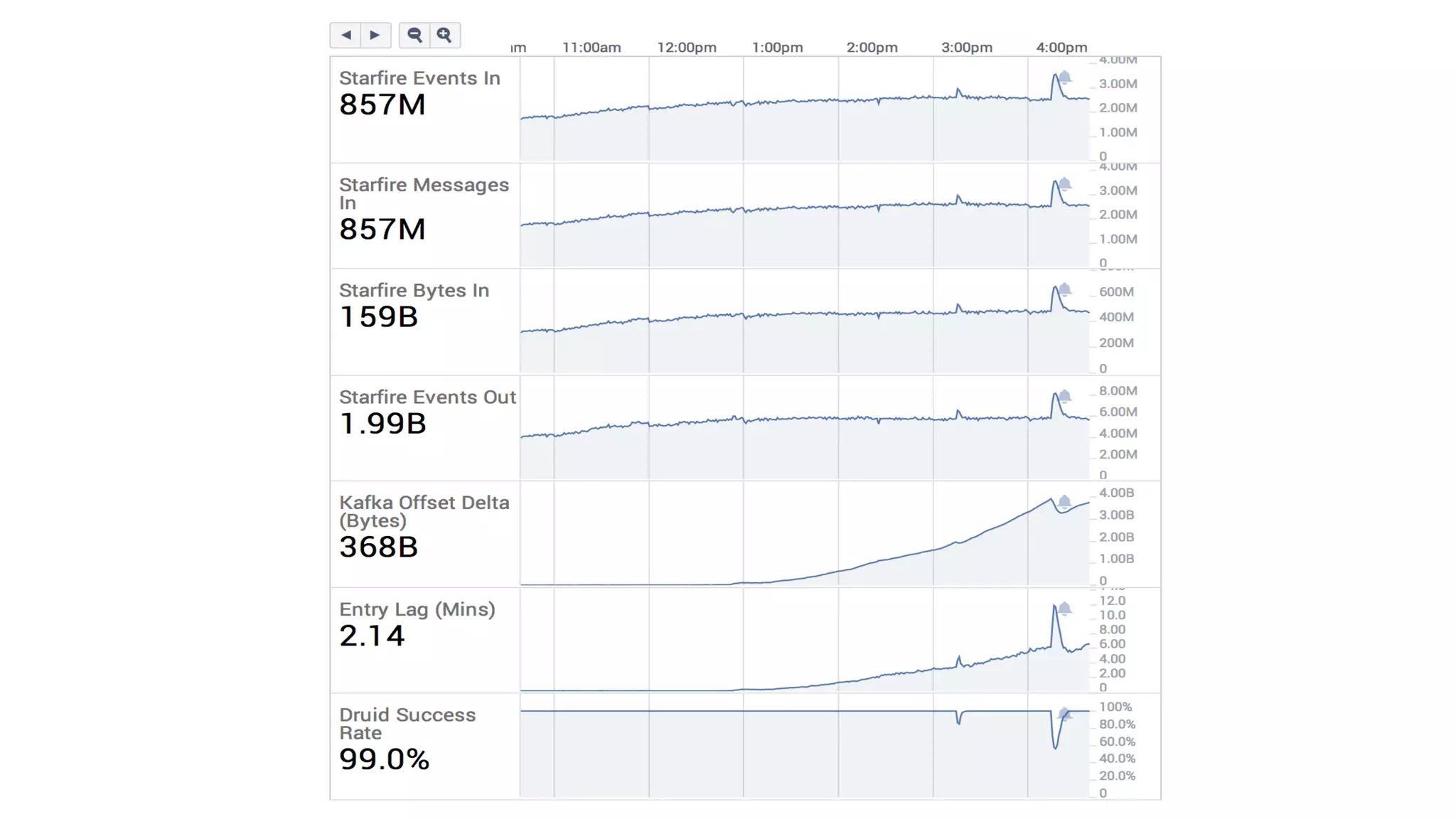



Документ описывает архитектуру обработки данных в real-time для аналитики, включая использование платформ таких как Apache Druid и Kafka. Приведены специфические метрики производительности, объемы обработки данных и подходы к запросам в контексте работы с большими данными. Также отмечены сложности, связанные с настройкой потоковых данных и проработка ошибок.
































































