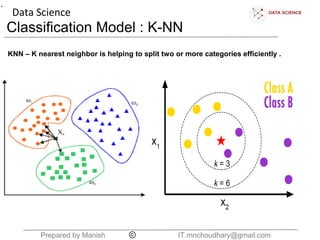
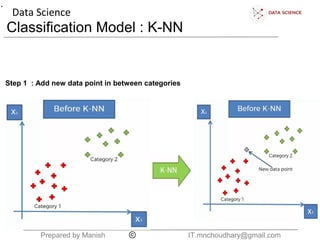
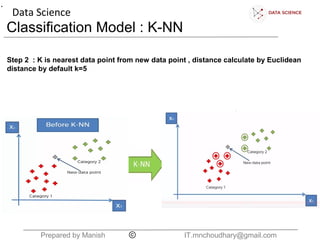
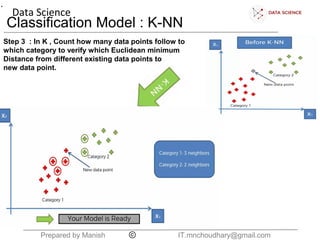
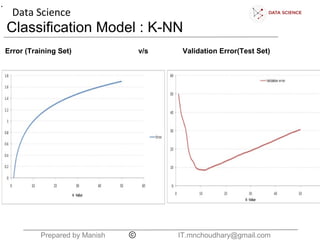
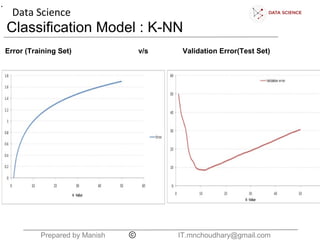
The document discusses the K-nearest neighbors (KNN) classification algorithm. It explains that KNN helps split data into categories by adding new data points and finding the K nearest existing points based on Euclidean distance. It counts the categories of the nearest K points and assigns the new point to the most common category. The document also discusses choosing the K boundary, measuring distances, and the relationship between training and validation error.
















































![k-nearestneighborknn-231215171119-a5cfb915.pptx [Read-Only].pptx](https://cdn.slidesharecdn.com/ss_thumbnails/k-nearestneighborknn-231215171119-a5cfb915-251010013925-09814a4b-thumbnail.jpg?width=640&height=640&fit=bounds)






















