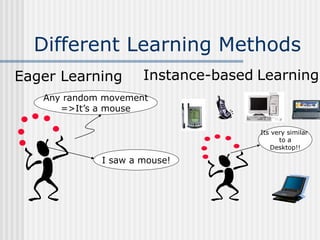
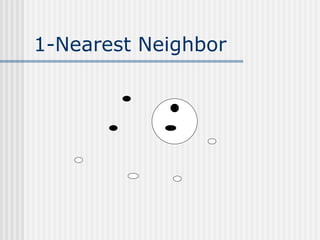
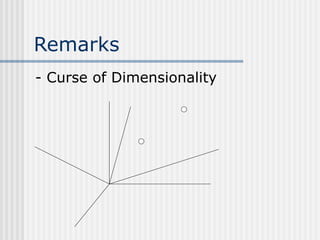
K-Nearest Neighbor is an instance-based, lazy learning algorithm that can be used for classification or regression. It stores all training examples and classifies new examples based on the majority class of its k nearest neighbors. Distance measures like Euclidean distance are used to find the k nearest neighbors. The algorithm is simple but classification can be slow. It is effective for noisy data but struggles with high-dimensional data due to the curse of dimensionality.