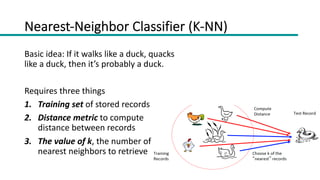
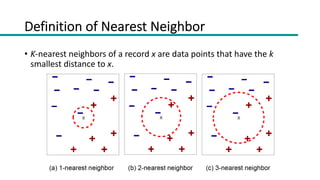
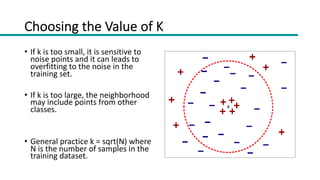
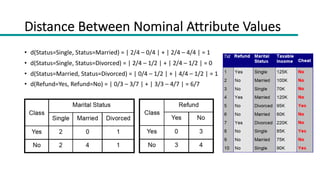
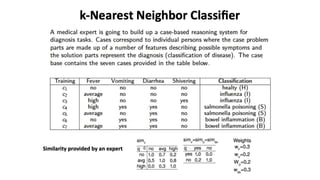
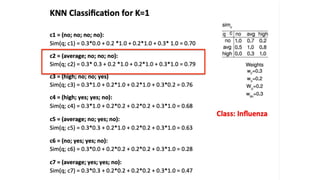
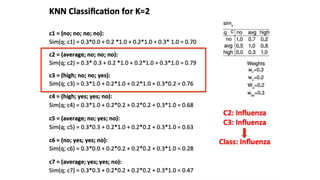
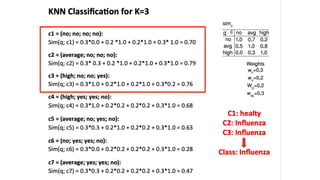
This document discusses instance-based classifiers and the k-nearest neighbors (k-NN) algorithm. It explains that k-NN classifiers store all available cases and classify new cases based on a similarity measure (e.g. distance functions). The k-NN algorithm identifies the k training examples nearest to the new case, and predicts the class as the most common class among those k examples. The document covers choosing the k value, distance measures, scaling issues, and using k-NN for regression problems.