Downloaded 36 times





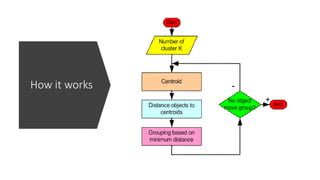
![Step 1: Begin with a decision on
the value of k : Number of clusters
(groups) and input variables. Use
silhouette score to determine k.
Step 2: Scale the data using [(x-
min(x)/max(x)-min(x)] and initialize
cluster centers. Randomly select k
observations from the scaled data
and consider them as initial cluster
centers.
Step 3: Calculate euclidean
distance between an observation
and initial cluster centers.
• Based on euclidean distance, each
observation is assigned to one of the
clusters - based on minimum distance.
Step 4: Move onto next
observation , calculate euclidean
distance, update cluster centers
and assign this observation a
cluster membership based on
minimum distance same as step 3.
Step 5: Repeat step 4 until all
observations are assigned a cluster
membership.
Step 6 : Check cluster plot and
silhouette score to measure the
goodness of clusters generated.
How it works – Steps](https://image.slidesharecdn.com/k-meansclusteringparameterstuningusecases-180626114316/85/What-is-the-KMeans-Clustering-Algorithm-and-How-Does-an-Enterprise-Use-it-to-Analyze-Data-8-320.jpg)
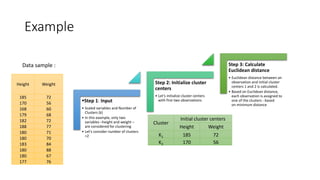
![Height Weight
185 72
170 56
First two observations
Cluster Height Weight
K1 185 72
K2 170 56
Updated centers
Euclidian Distance from
Cluster 1
Euclidian Distance from
Cluster 2
Cluster
Assignment
SQRT [(185-185)2+(72-72)2 ] =0
SQRT [(185-170)2+(72-56)2] =
21.93
1
SQRT [(170-185)2+(56-72)2] =
21.93
SQRT [(170-170)2+(56-56)2] = 0 2
Euclidean Distance from each of the clusters is calculated:
Step 3: Continue…
There is no change in centers as we considered same two observations as initial centers
Example](https://image.slidesharecdn.com/k-meansclusteringparameterstuningusecases-180626114316/85/What-is-the-KMeans-Clustering-Algorithm-and-How-Does-an-Enterprise-Use-it-to-Analyze-Data-10-320.jpg)
![Height Weight
168 60
Next observation
Cluster Height Weight
K1 185 72
K2
(170 +168)/2
=169
(56 +60)/2=
58
Updated cluster centers
Euclidian Distance from Cluster 1 Euclidian Distance from Cluster 2
Cluster
Assignment
SQRT [(168-185) 2+(60-72) 2] =20.808 SQRT[((168-170)2+(60-56) 2] = 4.472 2
Step 4 :
Move onto next observation,
calculate euclidean distance,
assign cluster membership and
update cluster centers
• Since distance is minimum from cluster 2, the observation is assigned to cluster 2.
• Now revise Cluster centers – Mean value of observations’ Height and Weight.
• Addition is only to cluster 2, so centroid of cluster 2 will be updated as follows :
Example](https://image.slidesharecdn.com/k-meansclusteringparameterstuningusecases-180626114316/85/What-is-the-KMeans-Clustering-Algorithm-and-How-Does-an-Enterprise-Use-it-to-Analyze-Data-11-320.jpg)
![Height Weight
179 68
Next observation
Cluster Height Weight
K1
(185 +179)/2
=182
(72 +68)/2
=70
K2 169 58
Updated cluster centers
Euclidian Distance from Cluster 1 Euclidian Distance from Cluster 2
Cluster
Assignment
SQRT [(179-185) 2+(68-72) 2] =7.21 SQRT[((179-170)2+(68-56) 2] = 14.14 1
Step 5:
Repeat steps 4 : calculate
Euclidean distance for next
observation, assign next
observation based on minimum
distance & update the cluster
centers until all observations are
assigned a cluster membership
o Since distance is minimum from cluster 1, the observation is assigned to cluster 1.
o Now revise Cluster Centroid – Mean value of observations’ Height and Weight.
o Addition is only to cluster 1, so centroid of cluster 1 will be updated as follows :
Example](https://image.slidesharecdn.com/k-meansclusteringparameterstuningusecases-180626114316/85/What-is-the-KMeans-Clustering-Algorithm-and-How-Does-an-Enterprise-Use-it-to-Analyze-Data-12-320.jpg)


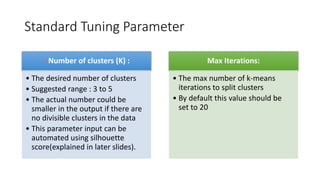

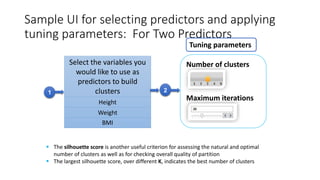

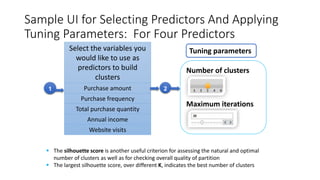


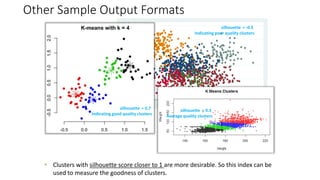





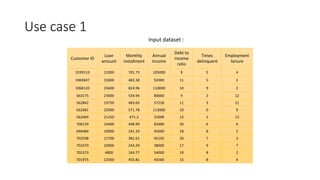
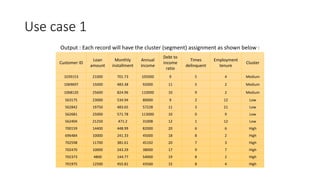
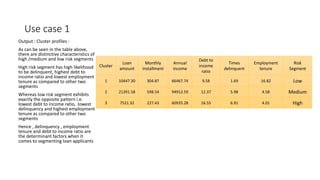
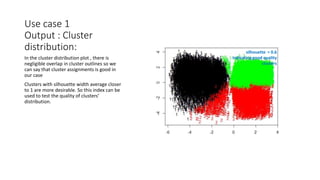
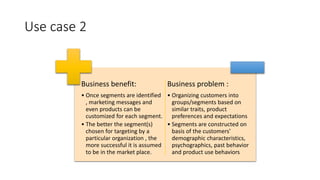
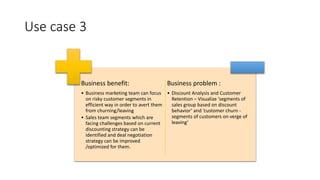


The document provides a detailed overview of k-means clustering, emphasizing its process, implementation steps, and various use cases. It explains how k-means can classify groups based on attributes with examples like loan applicants and customer segmentation. The document also discusses the algorithm's limitations and tuning parameters while highlighting the importance of assessing cluster quality through silhouette scores.























































































