Downloaded 23 times



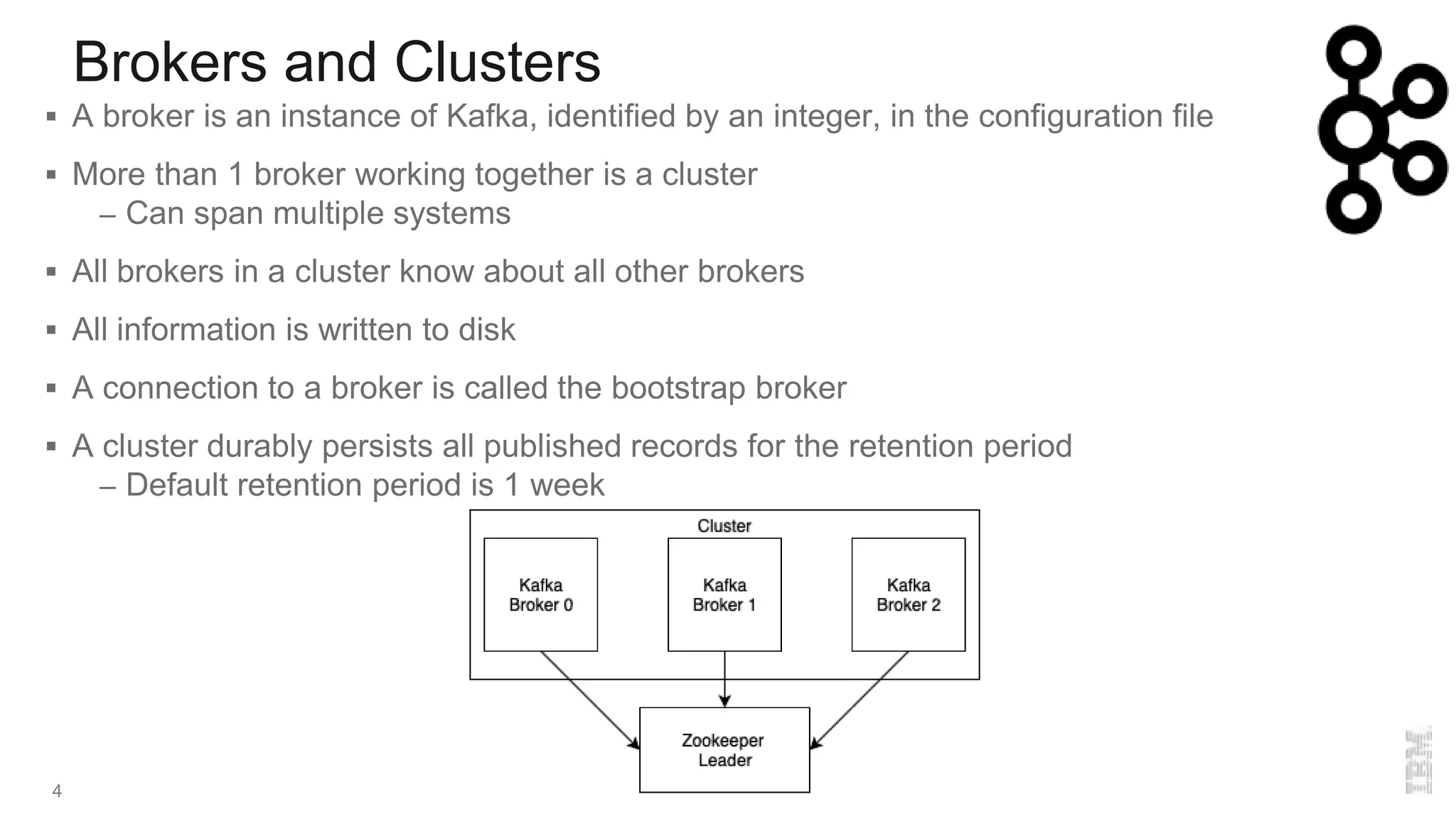

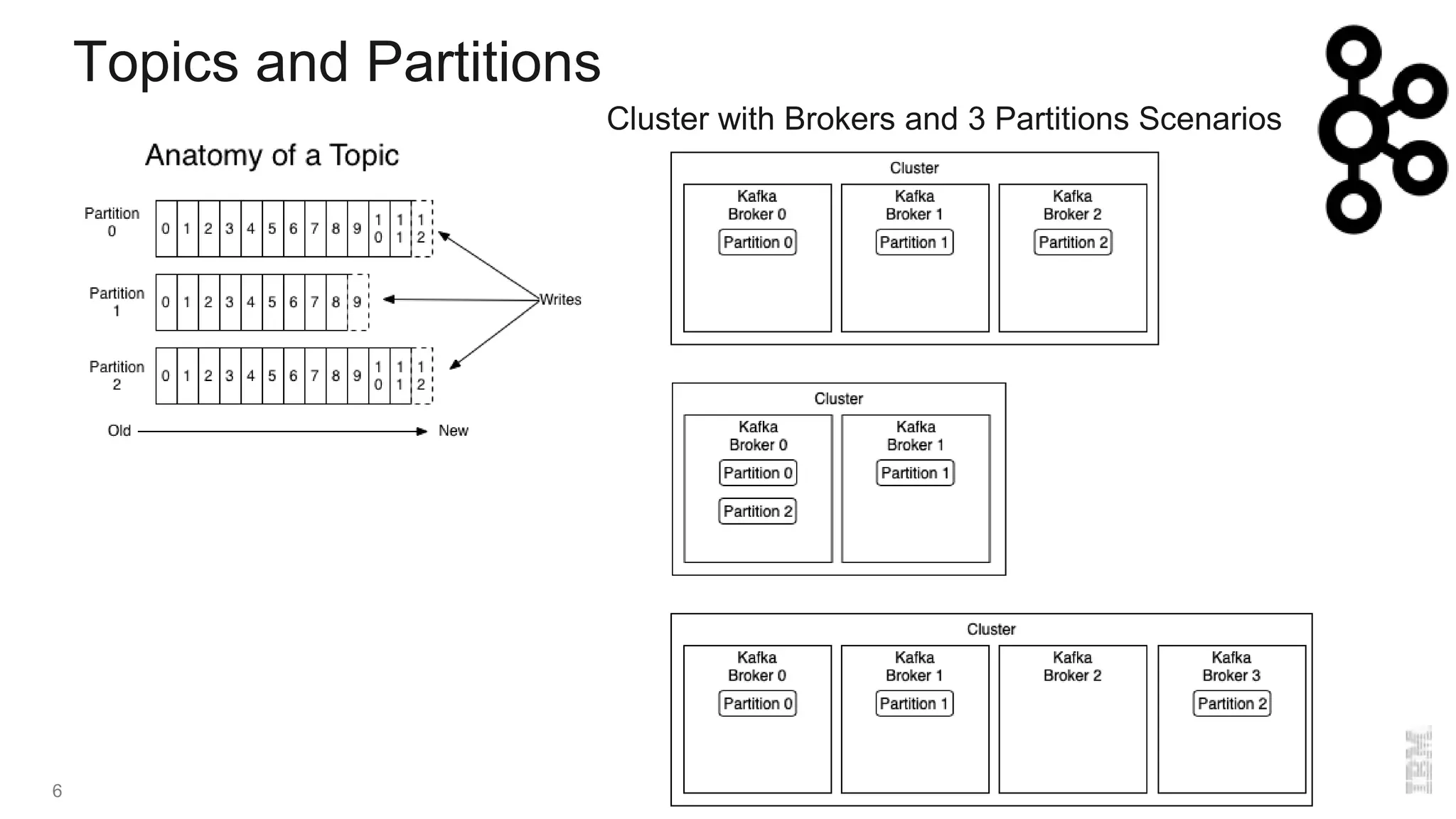



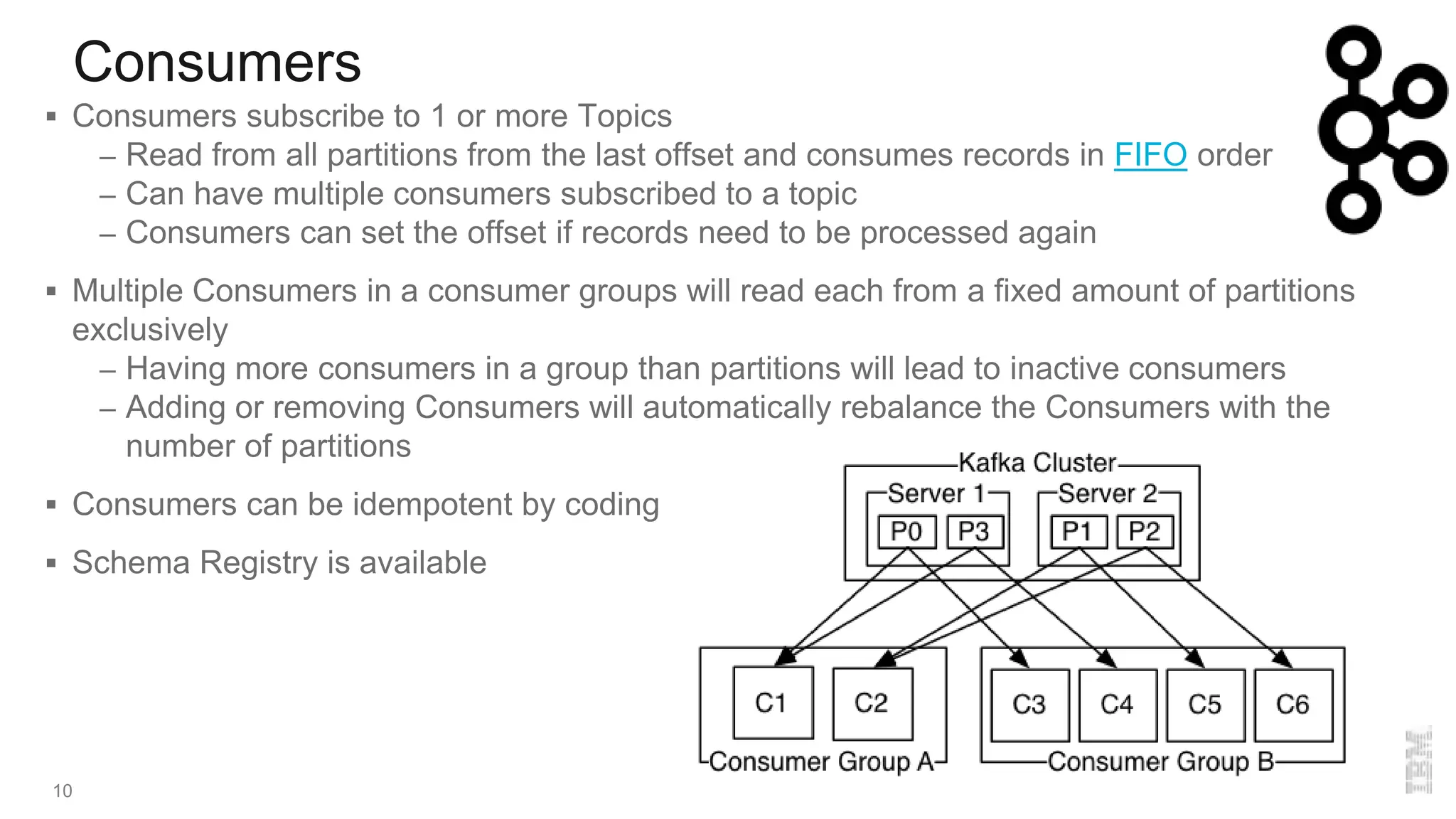
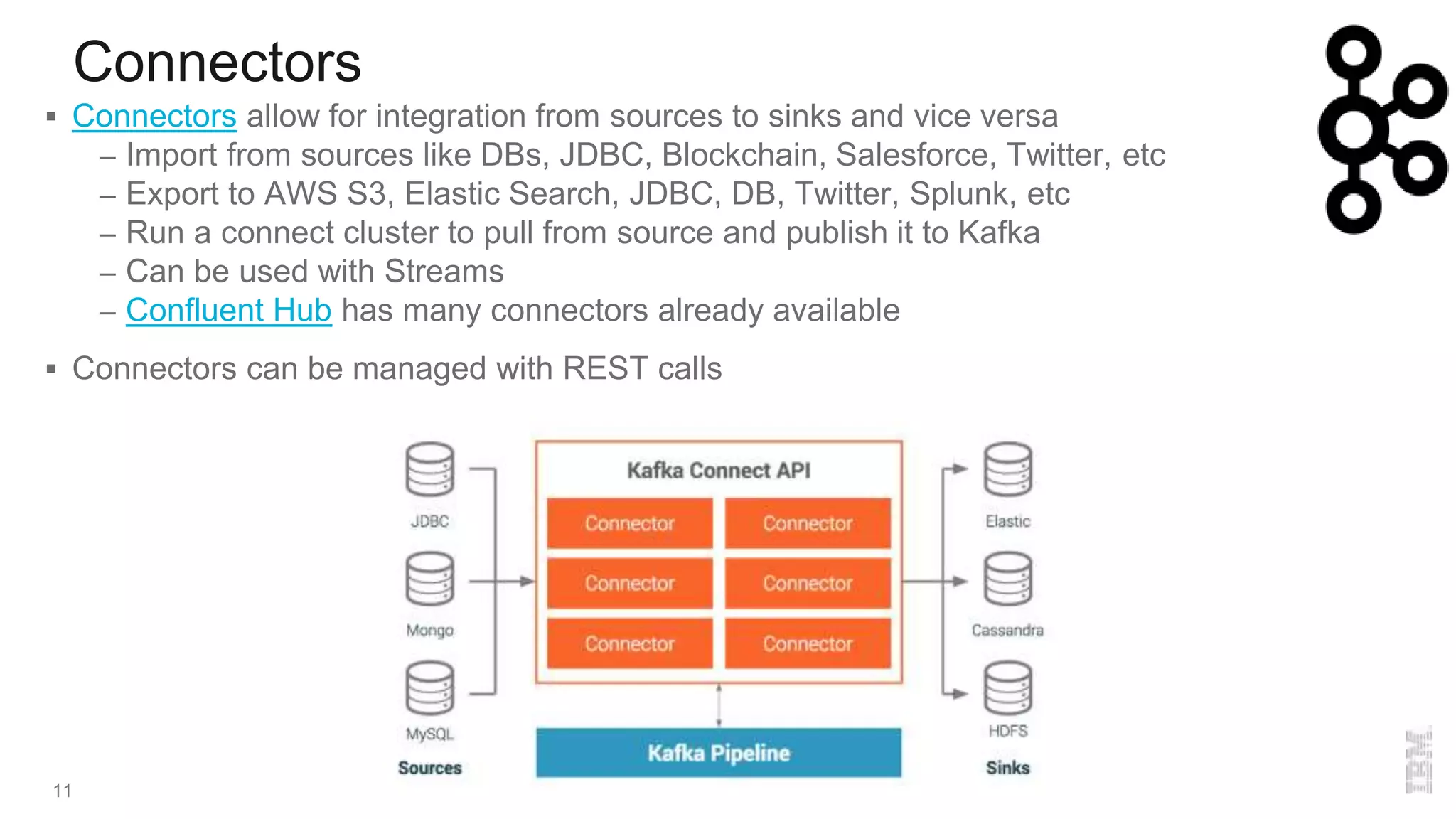








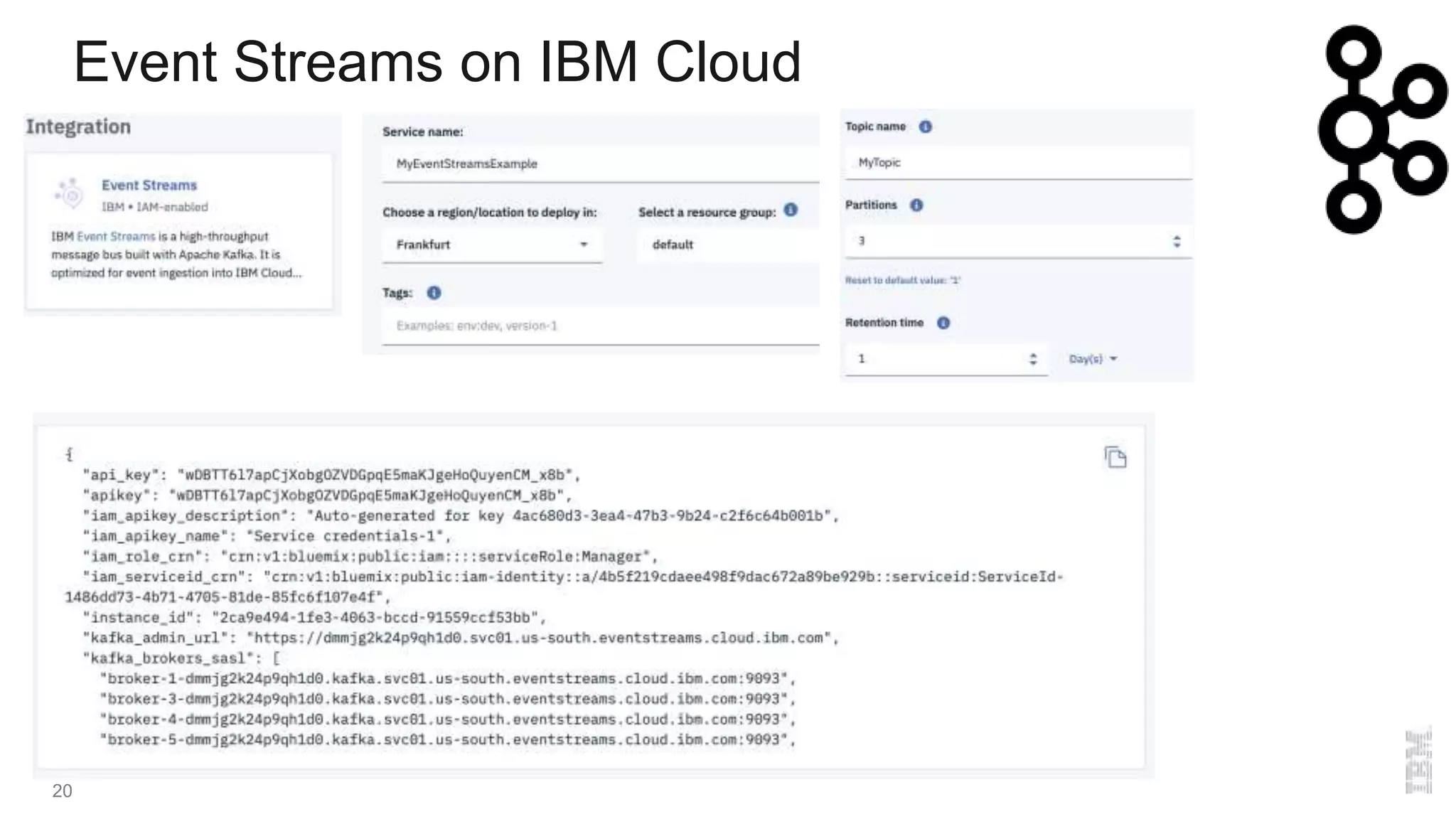






The document provides an overview of Kafka, a distributed publish-subscriber middleware developed by LinkedIn, detailing its architecture, components like brokers, topics, and partitions, along with its features for fault tolerance and scalability. It also covers consumer and producer functionalities, integration with connectors, and tools like the schema registry. Additionally, it introduces IBM Event Streams, which incorporates Kafka with enterprise features, available on IBM Cloud with options for support and various deployment plans.


















































![[DSC Europe 25] Ivan Peric - Intelligence Swarm Logic and Techno-Functional M...](https://cdn.slidesharecdn.com/ss_thumbnails/7my7c97fsduiccadgavw-2-251212103249-5a03f7c6-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Jon Dajci - Bridging TradFi and DeFi: Building the Future of ...](https://cdn.slidesharecdn.com/ss_thumbnails/fqmhfvlbqhkihjvqvhmu-7-251211083849-6af7e325-thumbnail.jpg?width=640&height=640&fit=bounds)
![[DSC Europe 25] Nikolay Burlutskiy - Best Practices for Building Enterprise M...](https://cdn.slidesharecdn.com/ss_thumbnails/uirvaiuvq8y1w8hzd9tx-7-251212103249-2619edb4-thumbnail.jpg?width=640&height=640&fit=bounds)



![[DSC Europe 25] Tatevik Maytesyan - How to actually use AI in marketing: gett...](https://cdn.slidesharecdn.com/ss_thumbnails/tjo626lsqdgfntbgl2mw-4-251216103155-e36cd239-thumbnail.jpg?width=640&height=640&fit=bounds)






![[DSC Europe 25] Katherine Forrest - AI NOW: Understanding the Velocity of Cha...](https://cdn.slidesharecdn.com/ss_thumbnails/wvvbruqfrci0sfq9xwgb-4-251212104007-e5ad1987-thumbnail.jpg?width=640&height=640&fit=bounds)
