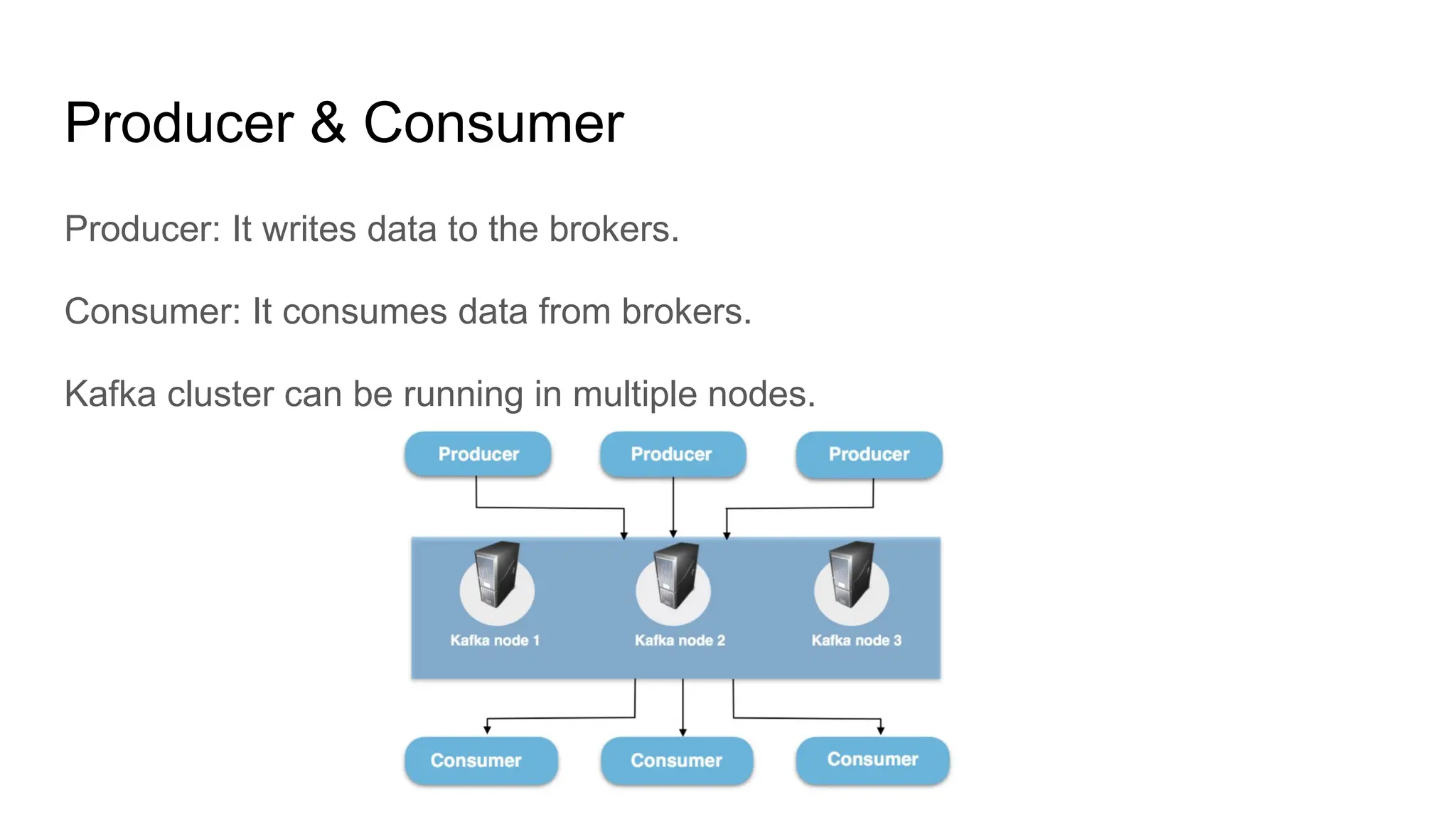
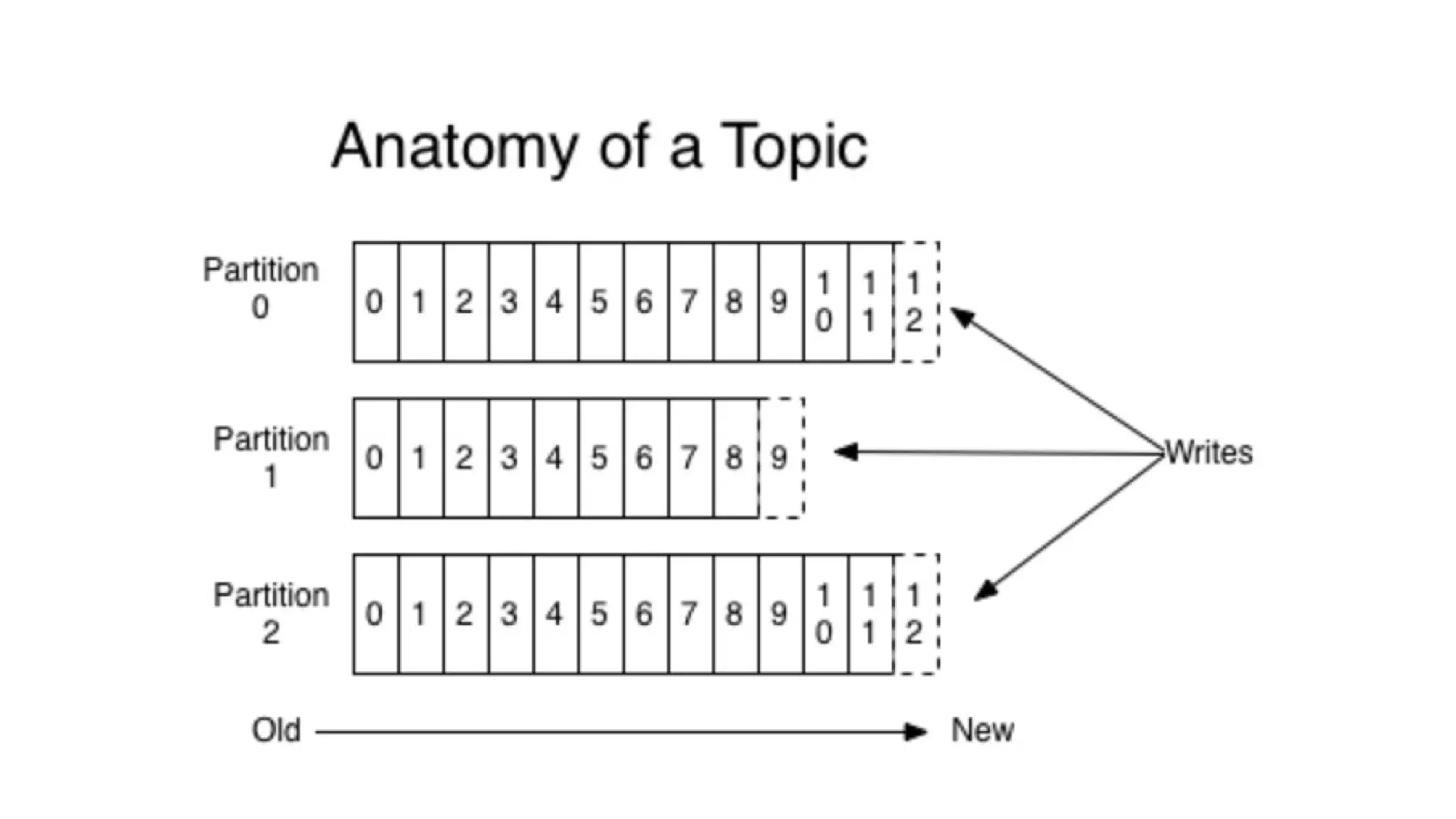
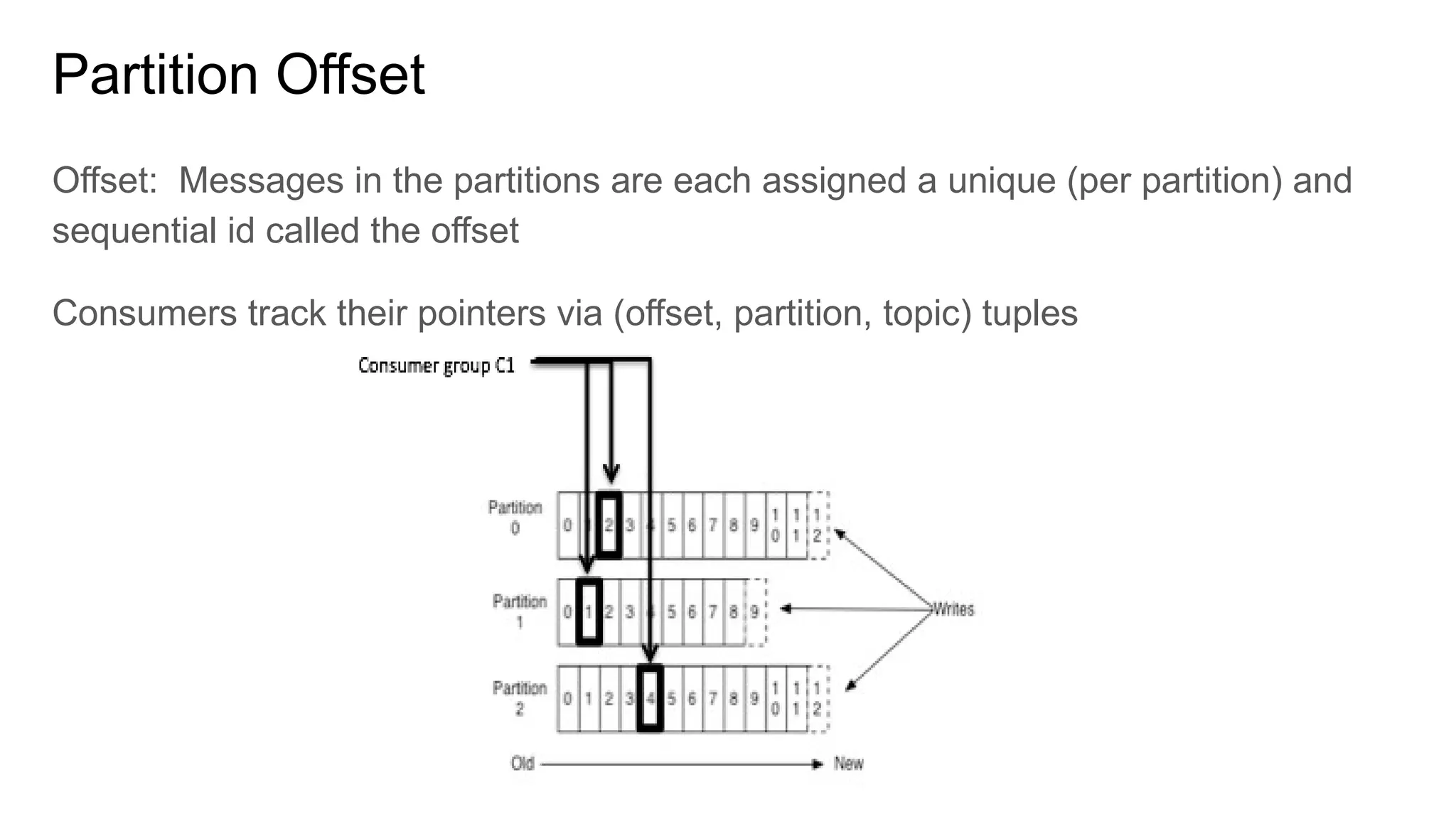
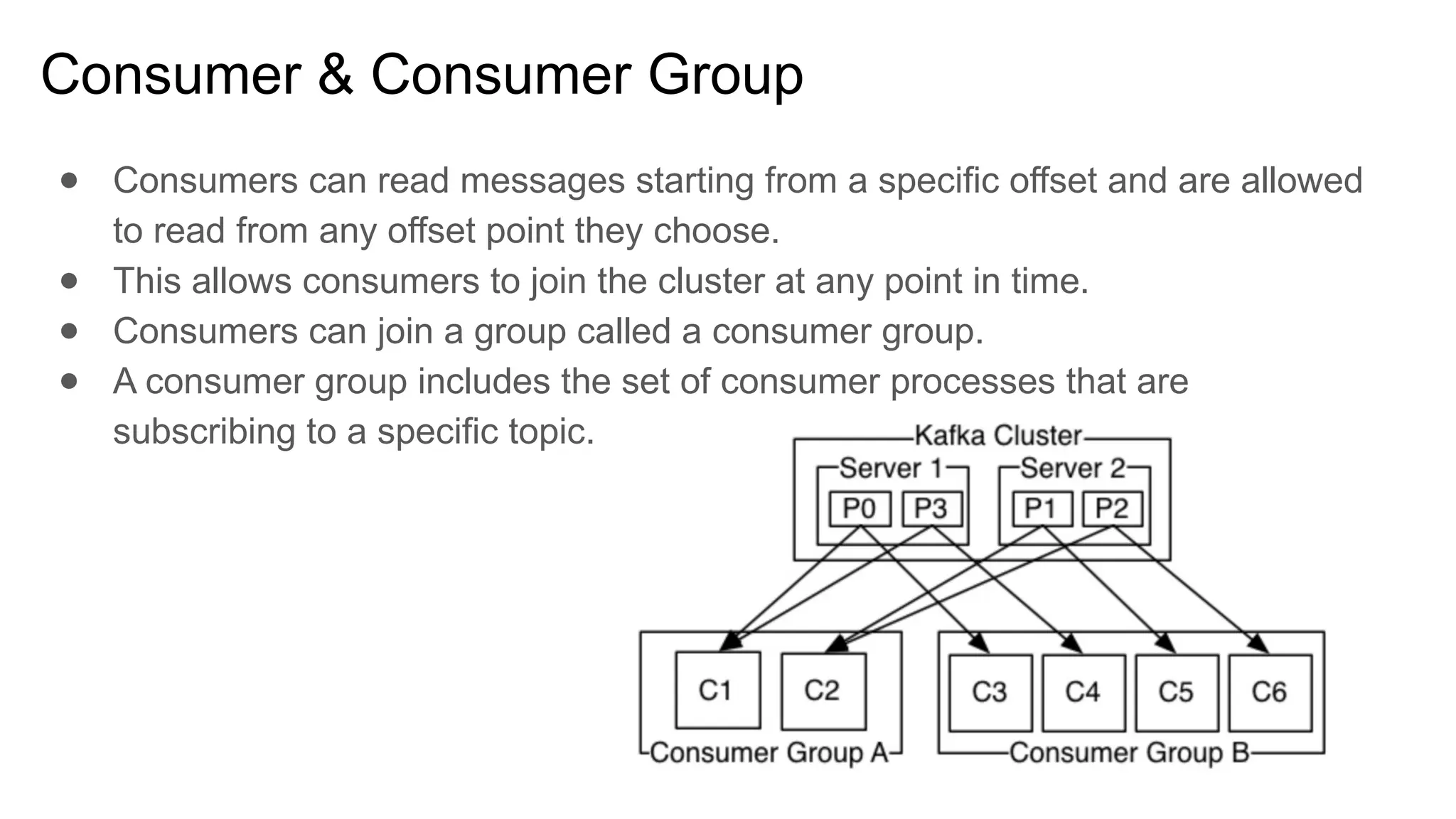
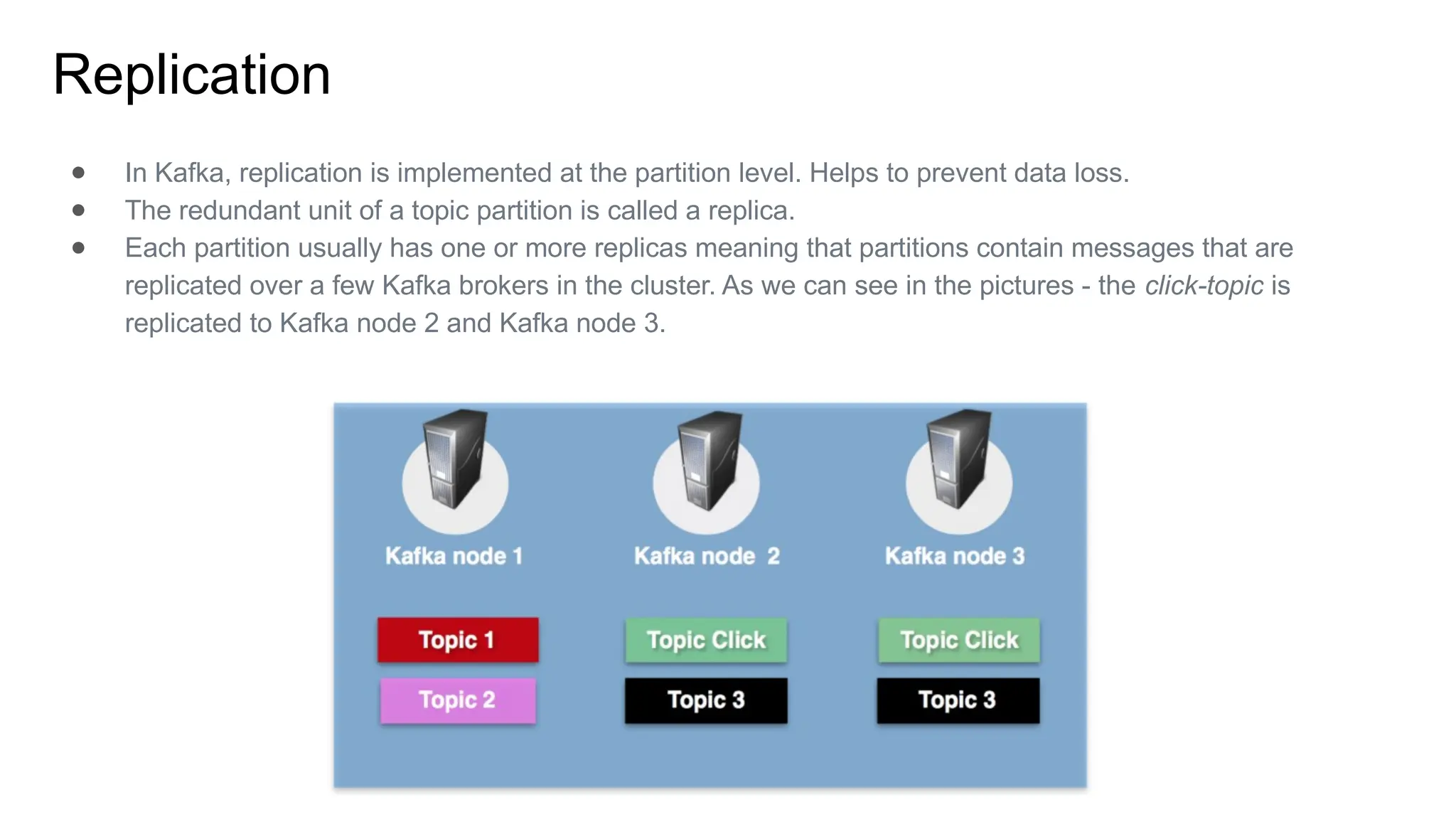
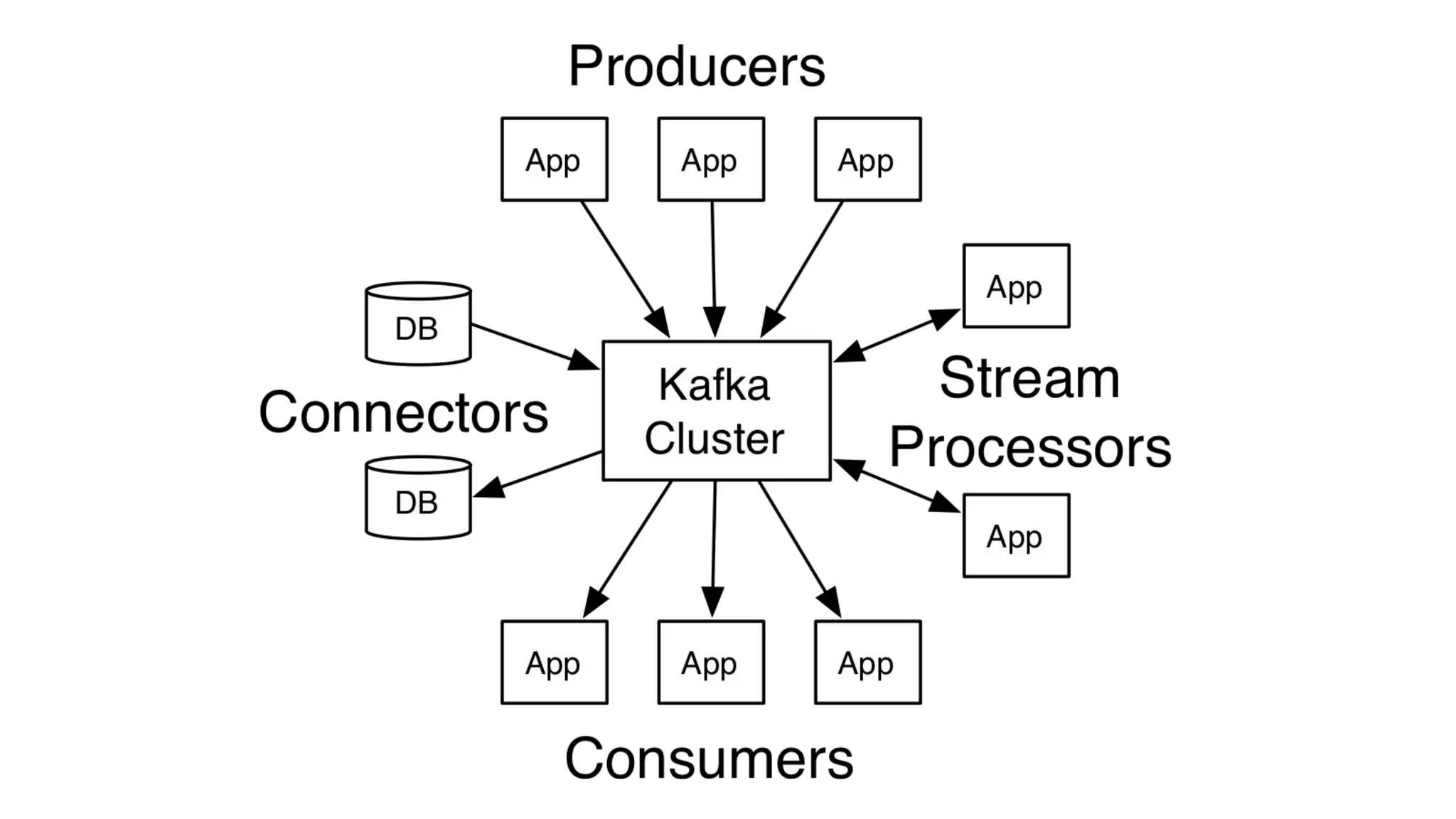
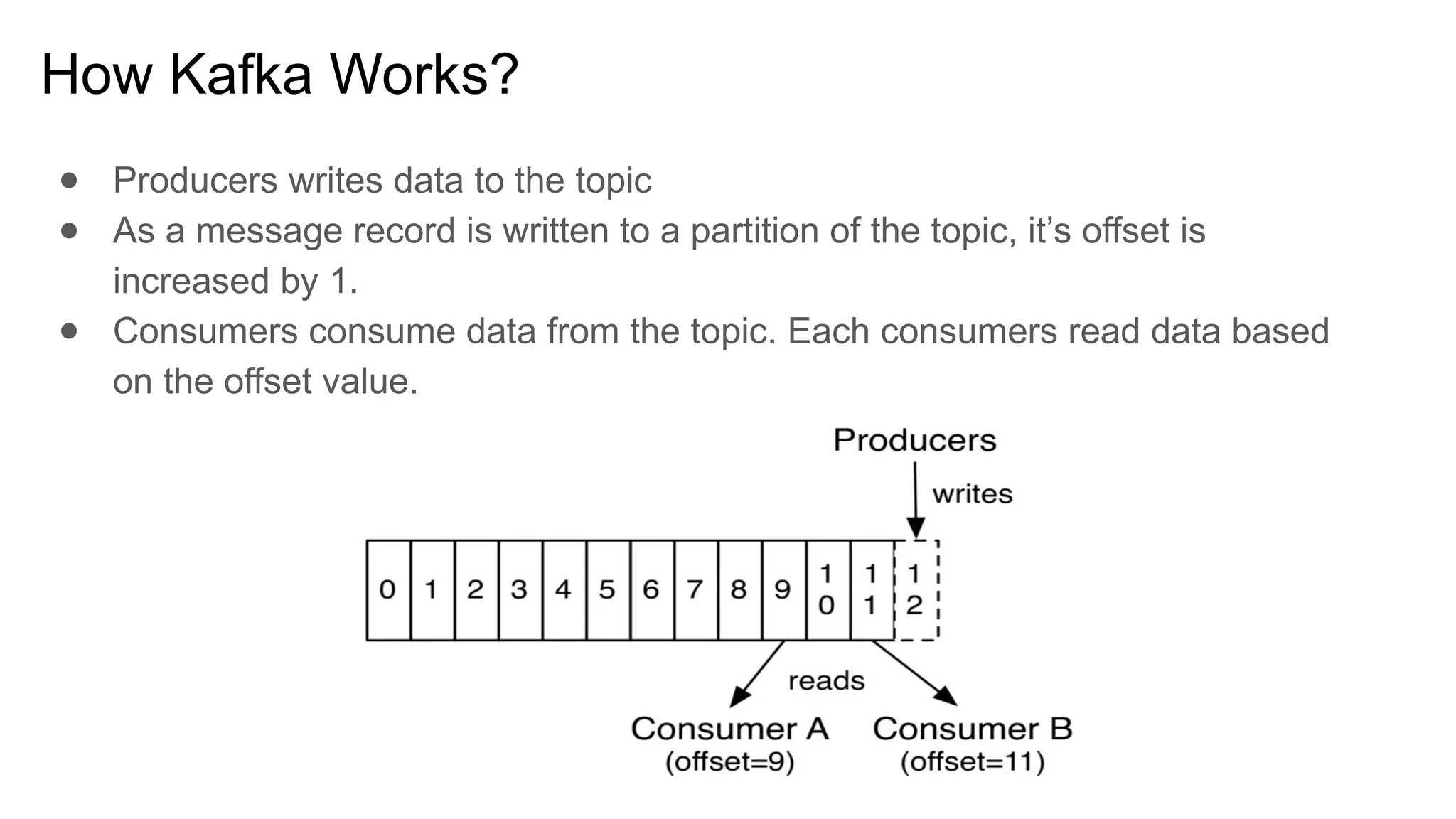
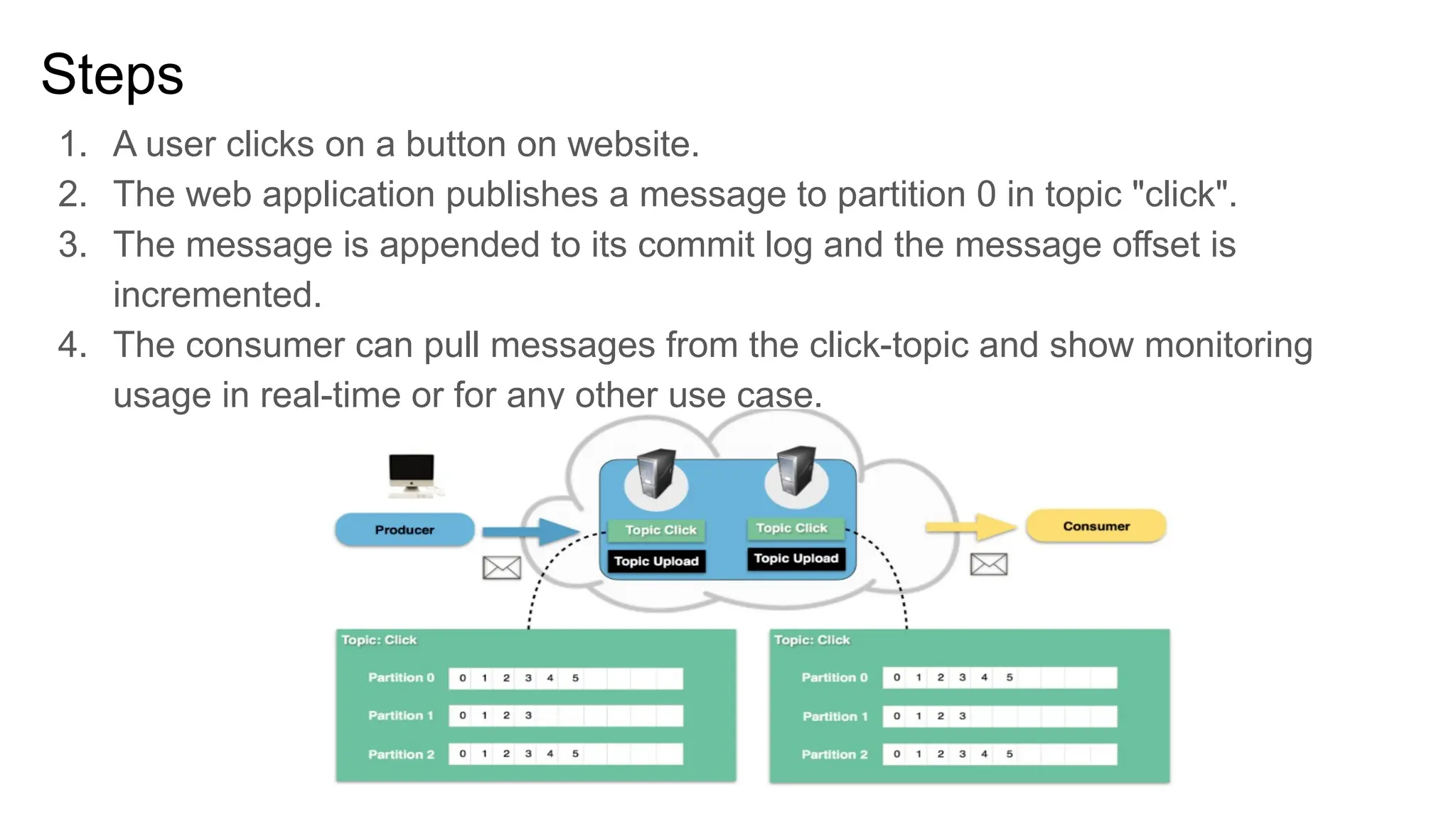
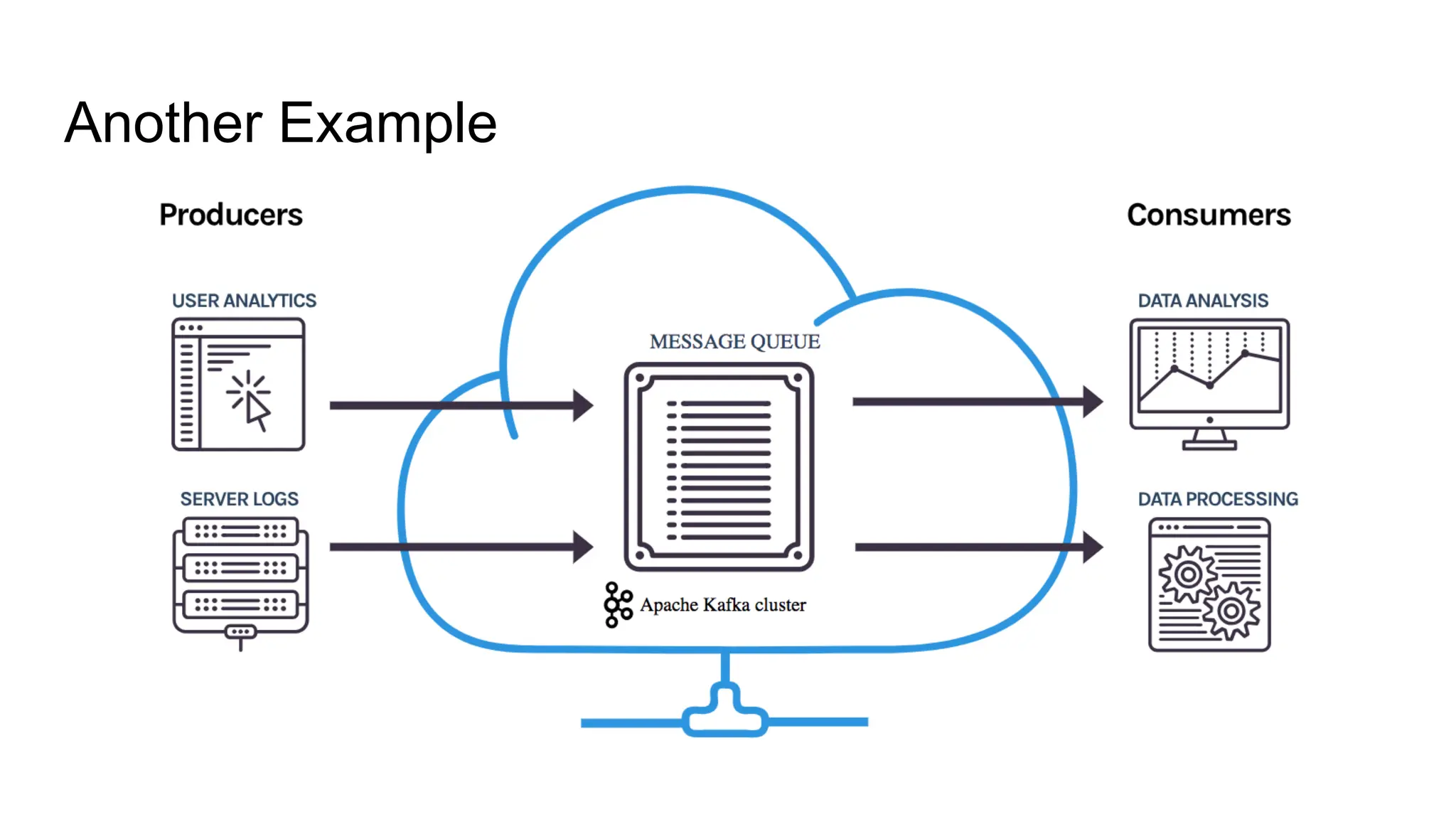
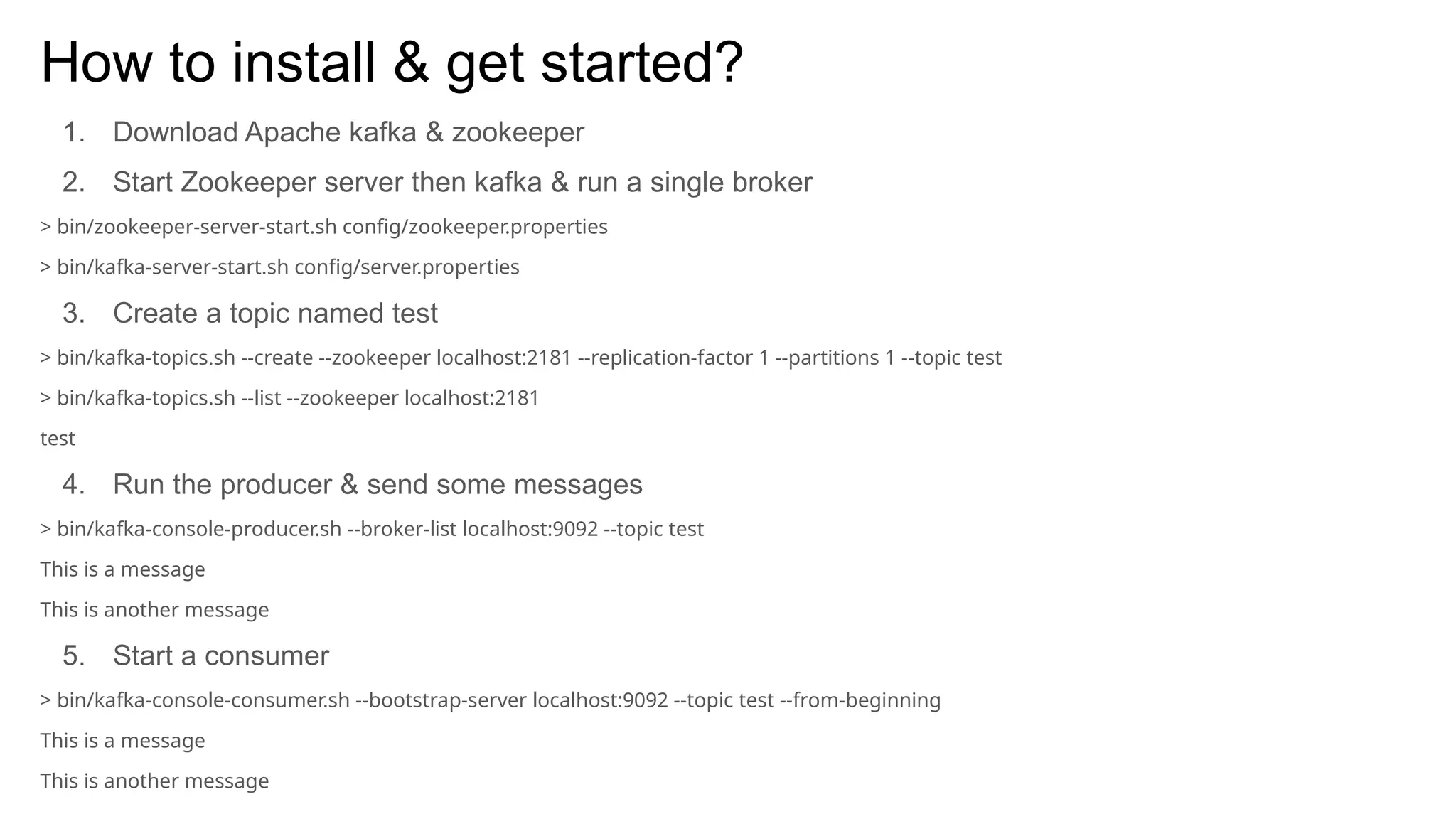
The document provides an overview of Apache Kafka, describing it as a distributed streaming platform used for building real-time data pipelines and applications. It outlines key components such as brokers, producers, consumers, topics, and partitions, as well as Kafka's APIs and replication mechanisms. Additionally, it includes installation instructions and examples of real-world applications like website activity tracking.