Downloaded 28 times






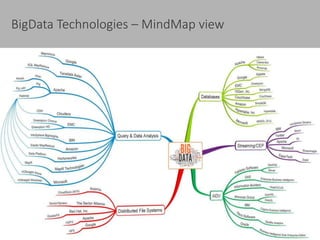
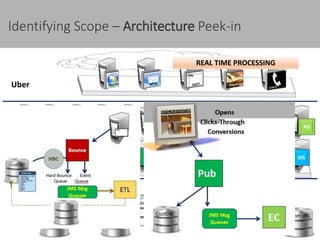


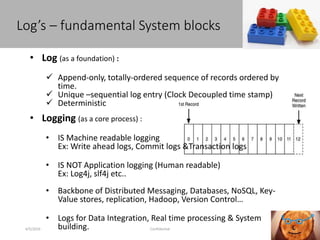

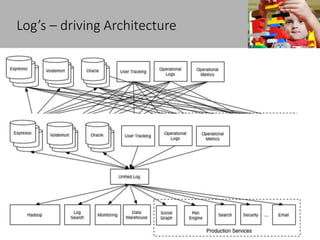


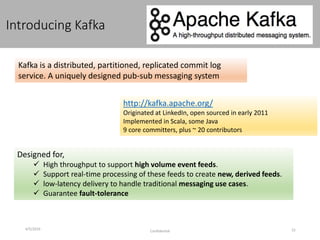

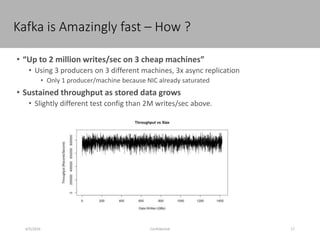

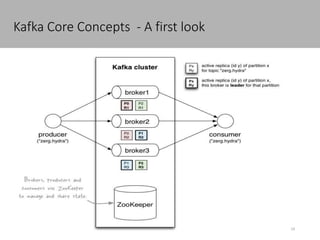
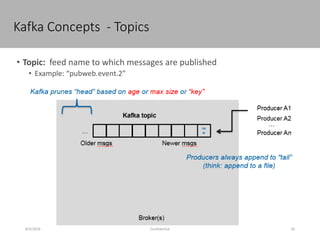
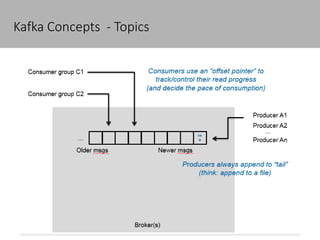
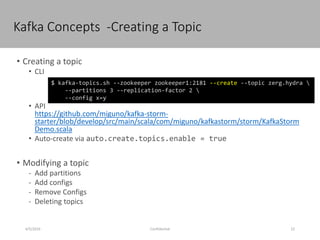
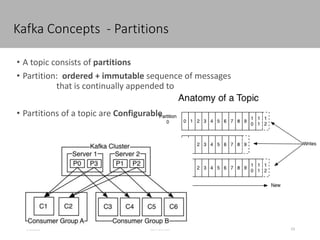
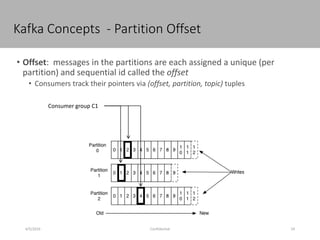


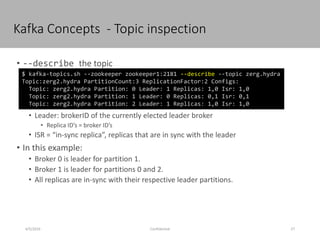
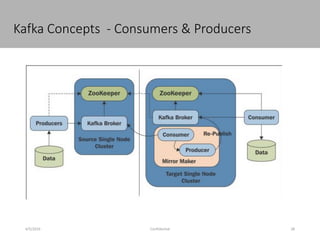
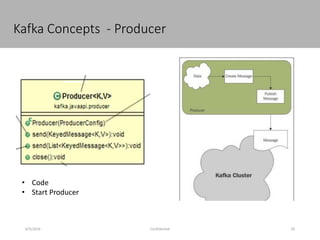
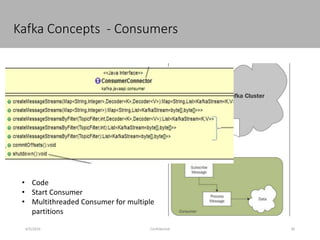
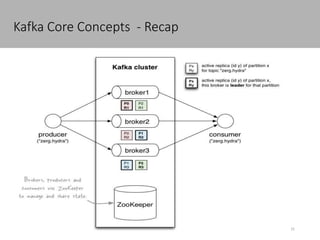



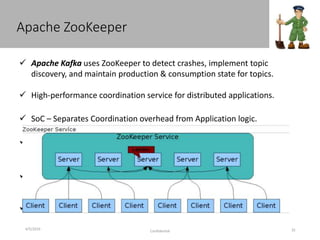
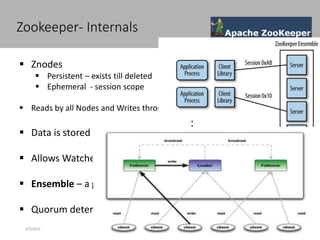


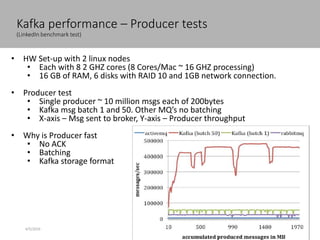
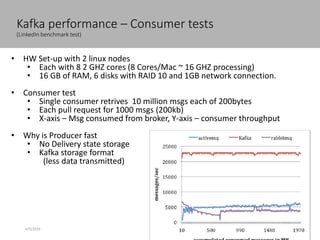




This document discusses new age distributed messaging using Apache Kafka. It begins with an introduction to Kafka concepts like topics, partitions, producers and consumers. It then explains how Kafka uses commit log architecture and an append-only log structure to provide high throughput performance. The document also covers how Zookeeper is used to coordinate Kafka brokers and keep metadata. It evaluates Kafka's performance based on LinkedIn benchmarks, finding that its lack of acknowledgements, batching and storage format allow for very fast publishing and consumption of messages. In conclusion, the document suggests Kafka could be introduced in some parts of Responsys' architecture to handle big data workloads.


































































