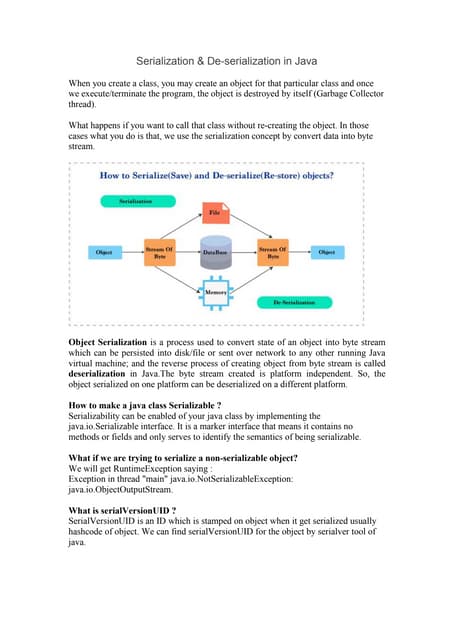
Downloaded 119 times










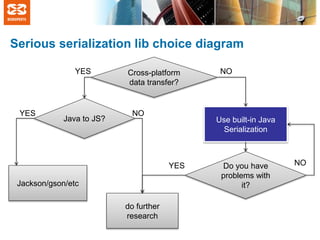




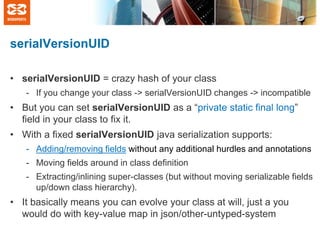


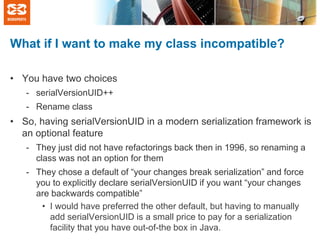















The document discusses Java serialization and common myths surrounding it. It summarizes that Java serialization allows for flexible evolution of classes while maintaining backwards compatibility through the use of serialVersionUID. It debunks common myths that Java serialization is slow, inflexible, or that changing private fields breaks compatibility. The document explains that serialization performance depends more on how streams are used rather than the underlying implementation.














































![Inspire [autosaved]](https://cdn.slidesharecdn.com/ss_thumbnails/inspireautosaved-120604001326-phpapp01-thumbnail.jpg?width=640&height=640&fit=bounds)










![[Wroclaw #7] Why So Serial?](https://cdn.slidesharecdn.com/ss_thumbnails/whysoserialv1-171206133328-thumbnail.jpg?width=640&height=640&fit=bounds)