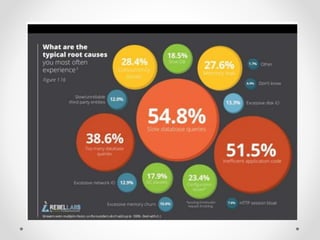
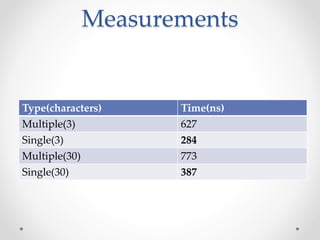
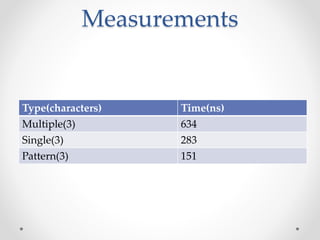
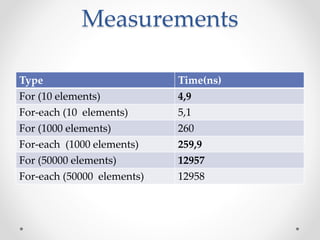
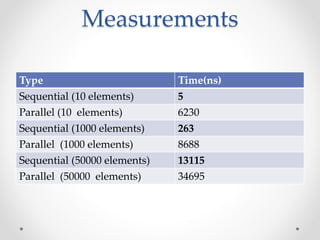
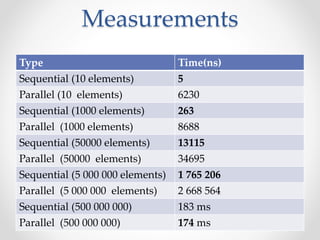
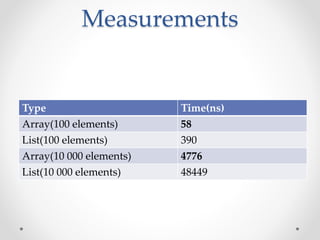
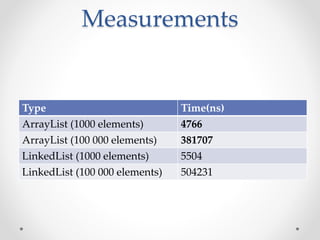
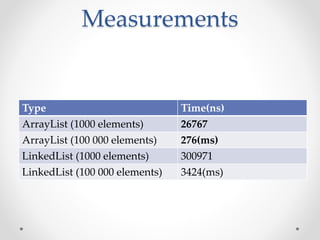
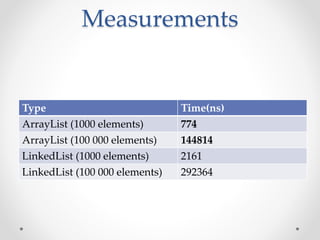
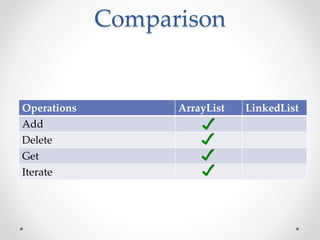
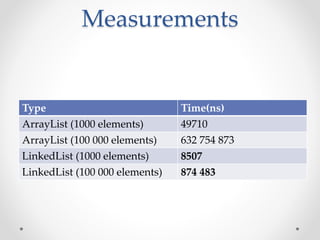
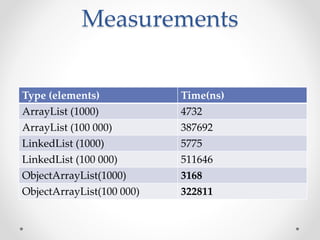
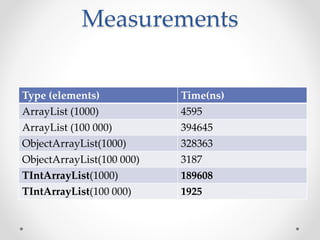
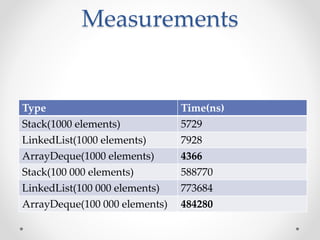
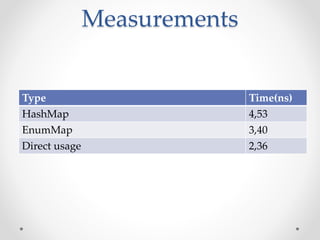
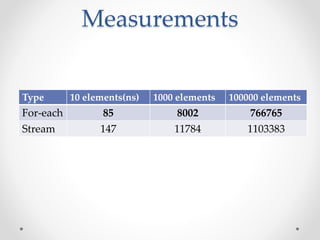
This document discusses code optimization techniques in Java applications. It begins with an overview of code effectiveness and optimization, noting that optimization should not be done prematurely. It then covers various optimization techniques including JVM options, code samples, measurements using JMH of different techniques like method vs field access, strings, arrays, collections, and loops vs streams. It finds that techniques like using ArrayList/HashMap, compiler and JIT optimization, and measurement tools can improve performance. The document emphasizes measuring optimizations to determine real effectiveness.