Downloaded 49 times






















![MATLAB®
References
32CS Department, KFUPM (KSA).
[1] Florian Schatz, Sven Koschnicke, Niklas Paulsen, Christoph Starke, and Manfred Schimmler, “MPI
Performance Analysis of Amazon EC2 Cloud Services for High Performance Computing”, A. Abraham et al.
(Eds.): ACC 2011, Part I, CCIS 190, pp. 371–381, 2011. Springer-Verlag Berlin Heidelberg 2011.
[2] Simon Ostermann, AlexandruIosup , Nezih Yigitbasi, Radu Prodan, Thomas Fahringer and Dick Eperna, “A
Performance Analysis of EC2 Cloud Computing Services for Scientific Computing”, D.R. Avreskyetal. (Eds.) :
Cloudcomp 2009 , LNICST 34, pp. 115- 131 , 2010. Institute for Computer Sciences, Social-Informatics and
Telecommunications Engineering 2010.
[3] Amazon Elastic Compute Cloud (Amazon EC2): http://aws.amazon.com/ec2/
[4] High Performance Computing (HPC) on AWS Clusters: http://aws.amazon.com/hpc-applications/
[5] G. Zanghirati and L. Zanni, “A parallel solver for large quadratic programs in training support vector
machines,” Parallel Comput., vol. 29, pp. 535–551, Nov. 2003.
[6] C. Caragea, D. Caragea, and V. Honavar, “Learning support vector machine classifiers from distributed data
sources,” in Proc. 20th Nat. Conf. Artif. Intell. Student Abstract Poster Program, Pittsburgh, PA, 2005, pp.
1602–1603.
[7] A. Navia-Vazquez, D. Gutierrez-Gonzalez, E. Parrado-Hernandez, and J. Navarro-Abellan, “Distributed
support vector machines,” IEEE Trans. Neural Netw., vol. 17, no. 4, pp. 1091–1097, Jul. 2006.
[8] Yumao Lu, Vwani Roychowdhury, and Lieven Vandenberghe, “Distributed Parallel Support Vector Machines
in Strongly Connected Networks”, IEEE TRANSACTIONS ON NEURAL NETWORKS, VOL. 19, NO. 7, JULY 2008.](https://image.slidesharecdn.com/svmoncloudpresntation-140320134214-phpapp01/75/Svm-on-cloud-presntation-32-2048.jpg)
![MATLAB®
References
33CS Department, KFUPM (KSA).
[9] C.-C. Chang and C.-J. Lin, LIBSVM: a library for support vector machines, 2001, software and datasets
available at http://www.csie.ntu.edu.tw/cjlin/libsvm.
[10] B. Catanzaro, N. Sundaram, and K. Keutzer, “Fast support vector machine training and classification on
graphics processors,” in ICML ’08: Proceedings of the 25th international conference on Machine learning.
New York, NY, USA: ACM, 2008, pp. 104–111.
[11] S. Herrero-Lopez, J. R. Williams, and A. Sanchez, “Parallel multiclass classification using svms on gpus,” in
GPGPU’10: Proceedings of the 3rd Workshop on General-Purpose Computation on Graphics Processing
Units. New York, NY, USA: ACM, 2010, pp. 2–11.
[12] Cao, L., Keerthi, S., Ong, C.-J., Zhang, J., Periyathamby, U., Fu, X. J., & Lee, H. (2006). Parallel sequential
minimal optimization for the training of support vector machines. IEEE Transactions on Neural Networks,
17, 1039-1049.
[13] Graf, H. P., Cosatto, E., Bottou, L., Dourdanovic, I., & Vapnik, V. (2005). Parallel support vector machines:
The cascade svm. In L. K. Saul, Y. Weiss and L. Bottou (Eds.), Advances in neural information processing
systems 17, 521-528. Cambridge, MA: MIT Press.
[14] Wu, G., Chang, E., Chen, Y. K., & Hughes, C. (2006). Incremental approximate matrix factorization for
speeding up support vector machines. KDD '06: Proceedings of the 12th ACM SIGKDD international
conference on Knowledge discovery and data mining (pp. 760-766). New York, NY, USA: ACM Press.
[15] Zanni, L., Serani, T., & Zanghirati, G. (2006). Parallel software for training large scale support vector
machines on multiprocessor systems. J. Mach. Learn. Res., 7, 1467-1492.
[16] Qi Li, Raied Salman, Vojislav Kecman, “An Intelligent System for Accelerating Parallel SVM Classification
Problems on Large Datasets Using GPU”, 2010 10th International Conference on Intelligent Systems Design
and Applications.](https://image.slidesharecdn.com/svmoncloudpresntation-140320134214-phpapp01/75/Svm-on-cloud-presntation-33-2048.jpg)


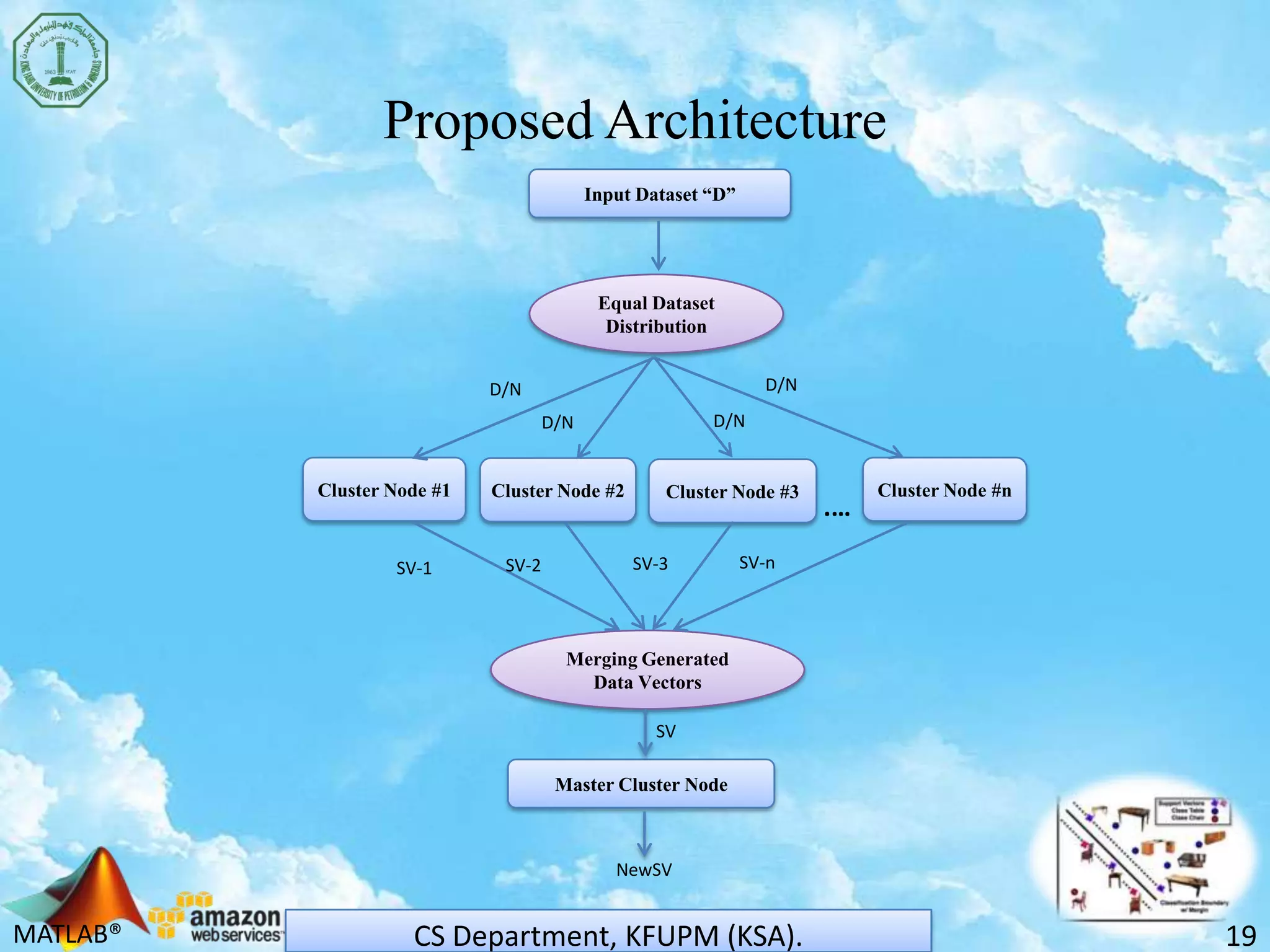
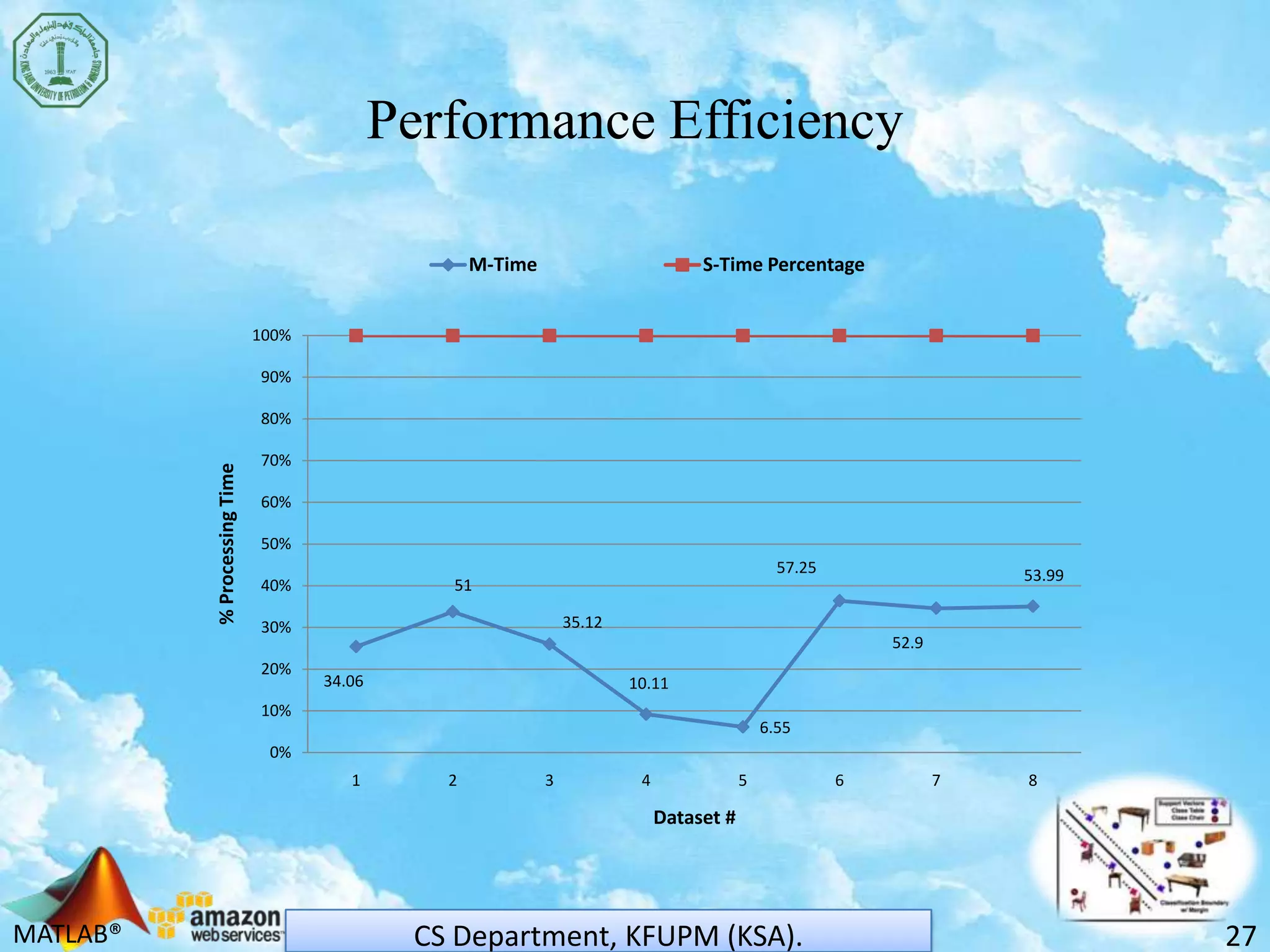
The document discusses scaling support vector machines (SVM) for large datasets using cloud computing. It proposes distributing an input dataset across multiple cloud cluster nodes to train SVMs in parallel. Experimental results show the approach reduces processing time and memory requirements compared to a single node. Accuracy is maintained while achieving up to 60% improved efficiency. The solution is cost-effective since users only pay for computing resources used. Future work involves evaluating other cloud platforms and large-scale applications.










































































