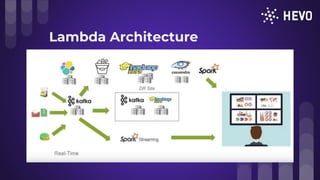
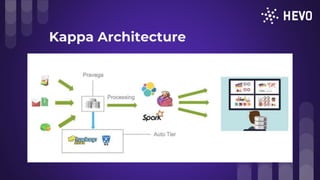
The document discusses challenges in building a data pipeline including making it highly scalable, available with low latency and zero data loss while supporting multiple data sources. It covers expectations for real-time vs batch processing and explores stream and batch architectures using tools like Apache Storm, Spark and Kafka. Challenges of data replication, schema detection and transformations with NoSQL are also examined. Effective implementations should include monitoring, security and replay mechanisms. Finally, lambda and kappa architectures for combining stream and batch processing are presented.



























































![[Heap con19] designing data intensive applications in serverless architecture](https://cdn.slidesharecdn.com/ss_thumbnails/heapcon19designingdataintensiveapplications-191004142134-thumbnail.jpg?width=640&height=640&fit=bounds)







![20260201 [FOSDEM] gomodjail - library sandboxing for Go modules.pdf](https://cdn.slidesharecdn.com/ss_thumbnails/20260201fosdemgomodjail-librarysandboxingforgomodules-260201225659-76609ec4-thumbnail.jpg?width=640&height=640&fit=bounds)
















