1) The document summarizes several papers on action recognition from computer vision and pattern recognition conferences.
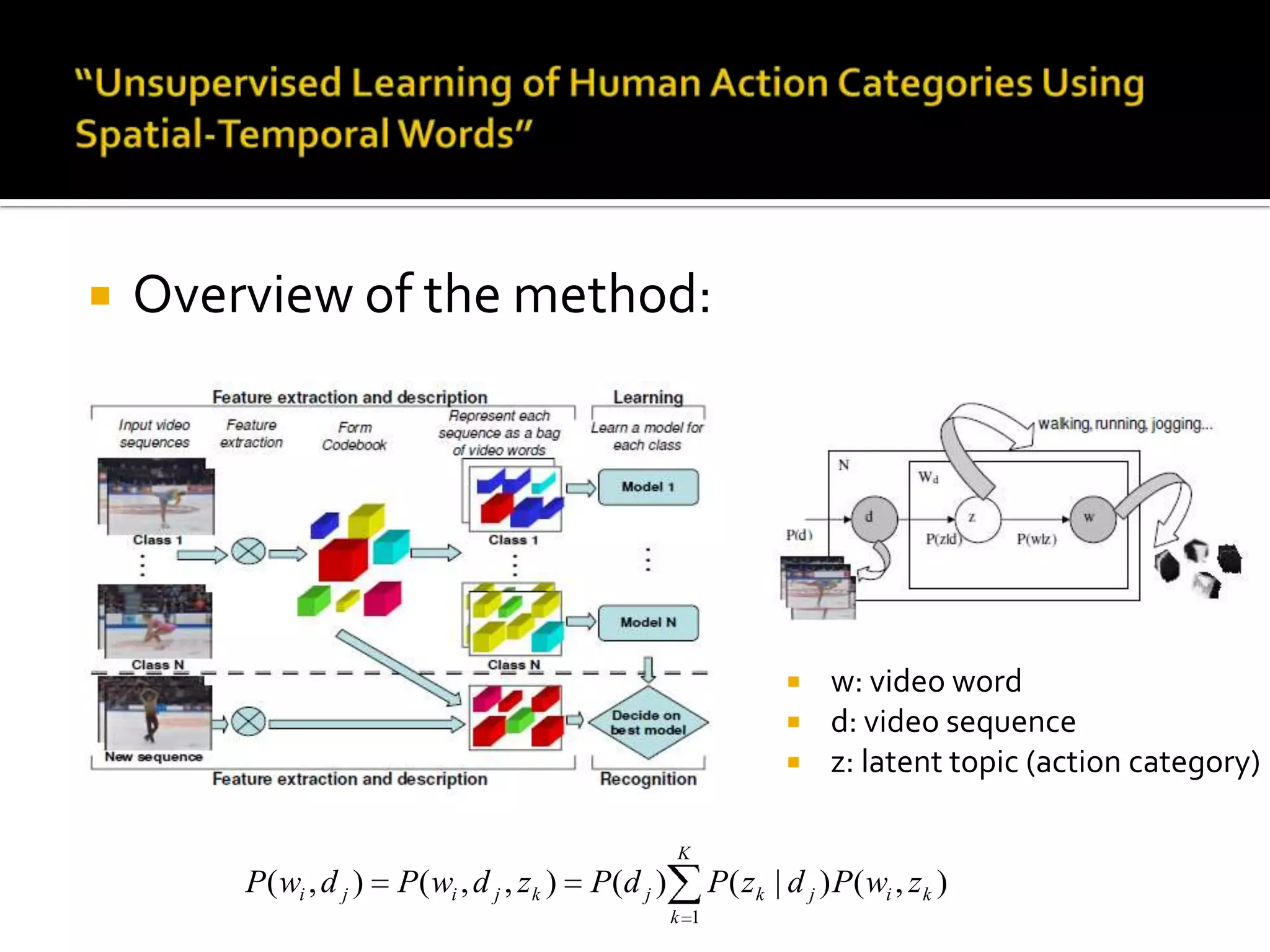
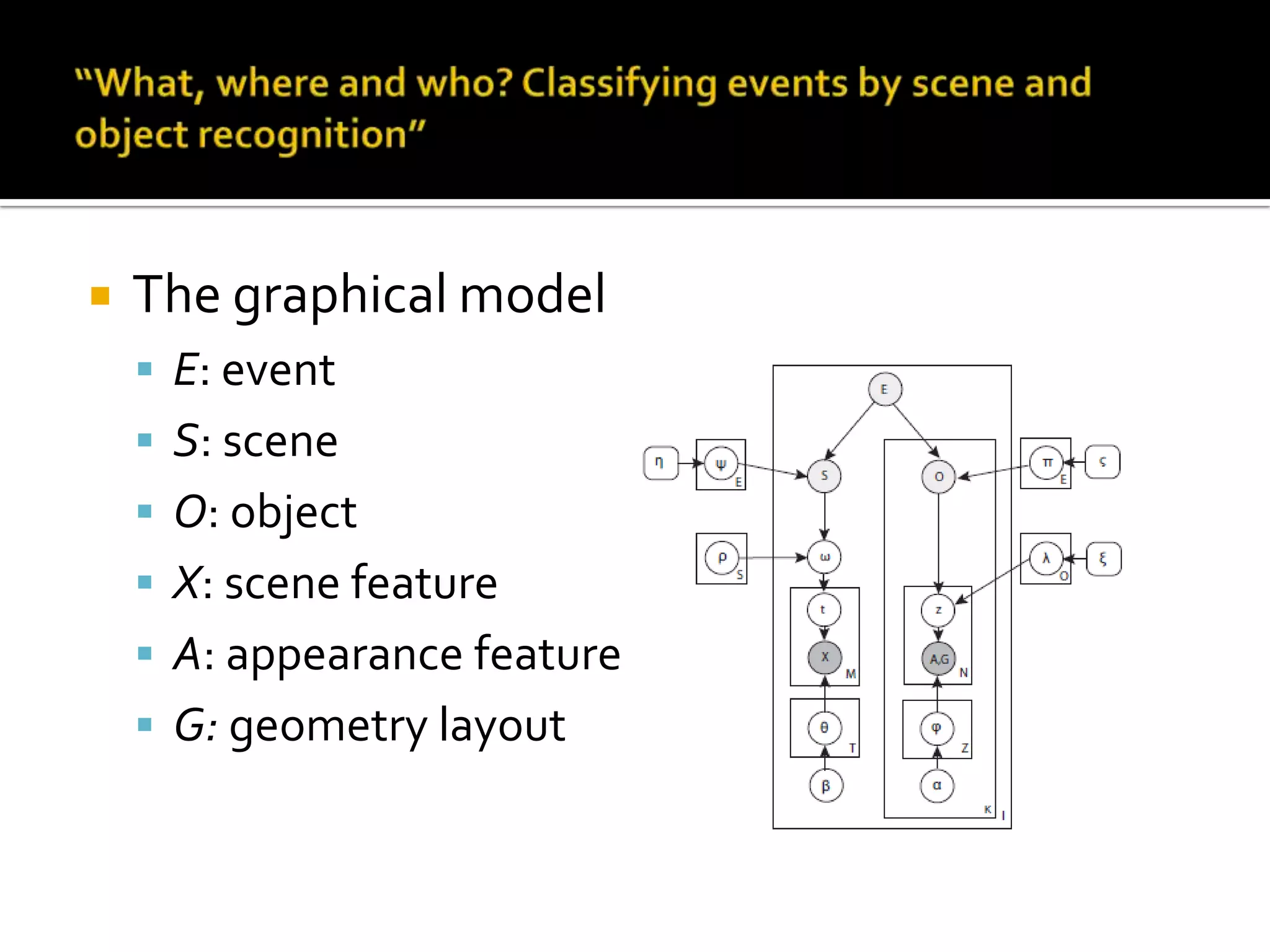
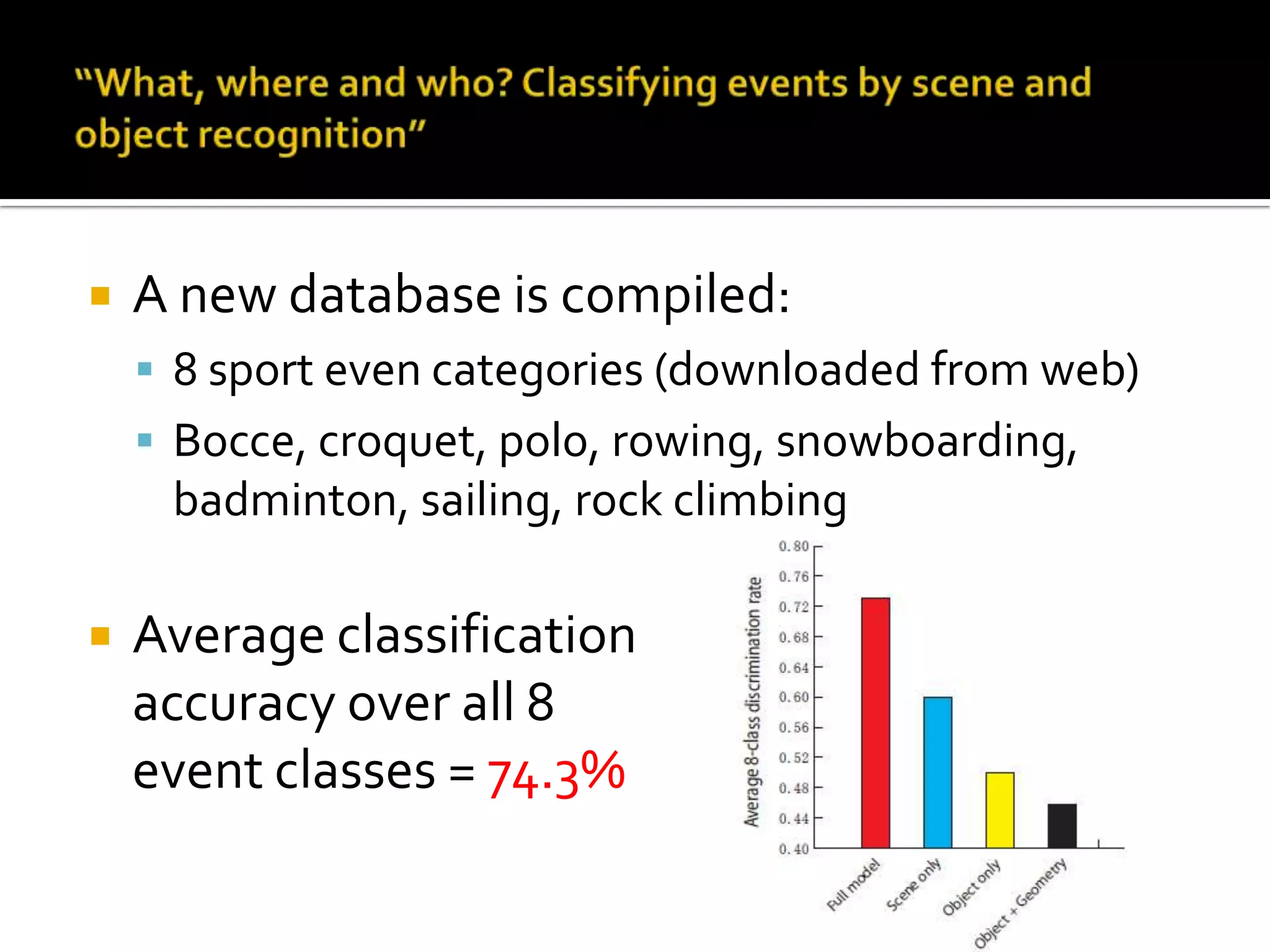
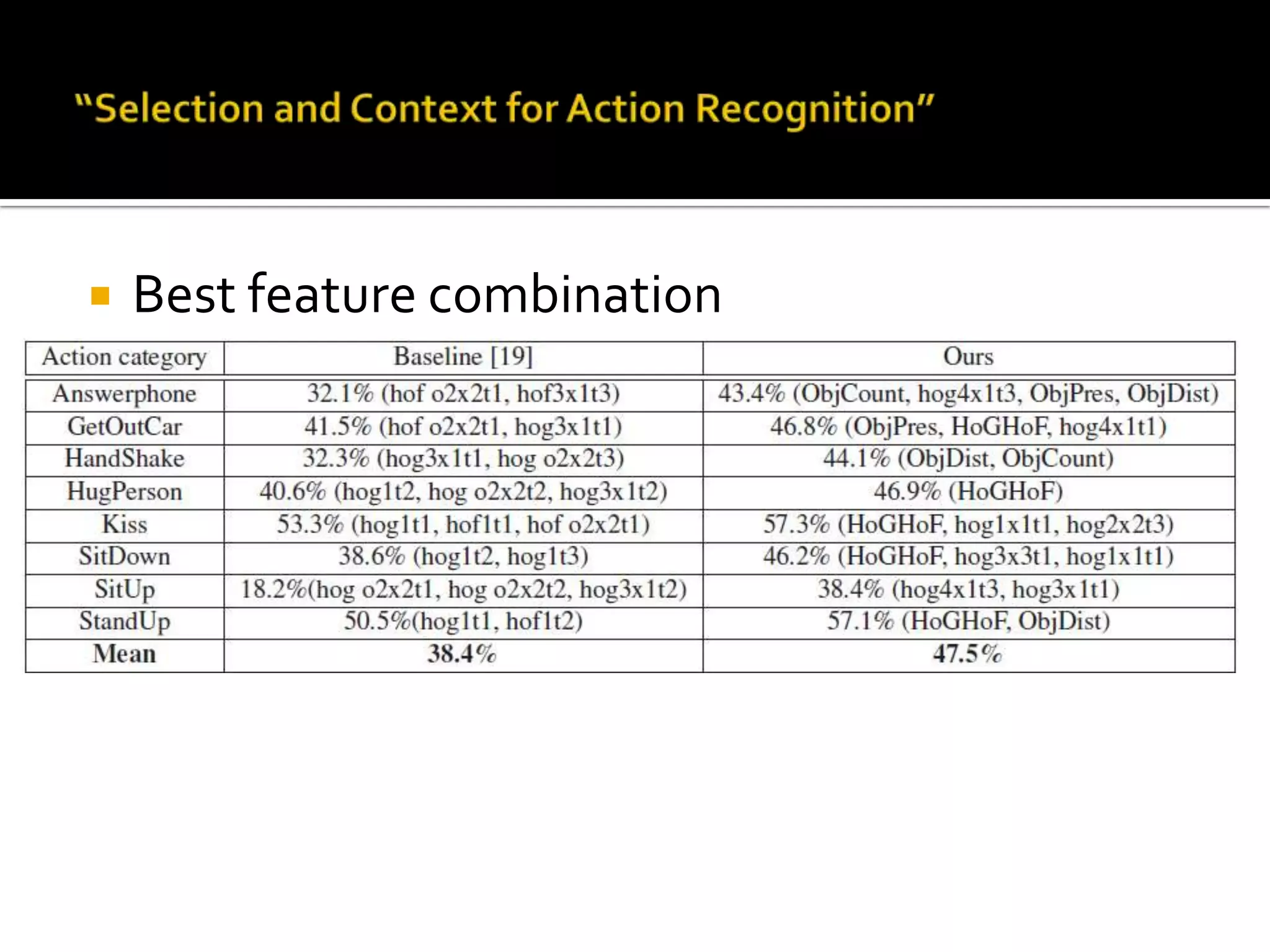
2) Key topics discussed include statistical analysis of dynamic actions using space-time gradients, space-time interest points for action detection, unsupervised learning of actions using spatial-temporal words, and recognizing actions in movies and medium resolution videos.
3) New datasets introduced include the KTH action dataset with videos of common human actions like walking and running, as well as datasets of actions extracted from real movies and videos.