Downloaded 56 times





















![Verify that the shard was added
• db.runCommand({ listshards:1 })
• { "shards" :
• [ { "_id”: "shard0000”, "host”: ”<hostname>:27018” } ],
• "ok" : 1
}](https://image.slidesharecdn.com/sharding-121212103139-phpapp01/85/Sharding-27-320.jpg)






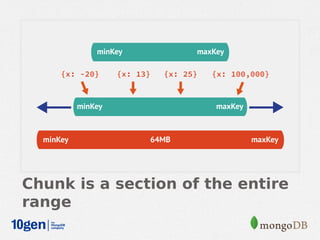
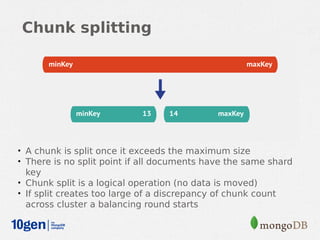
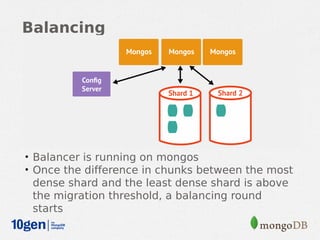
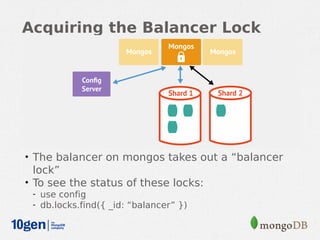
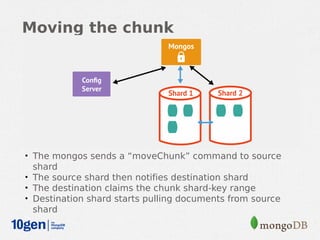
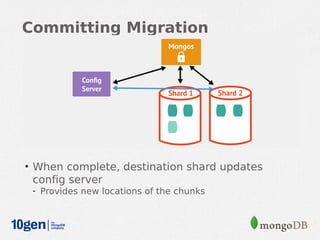
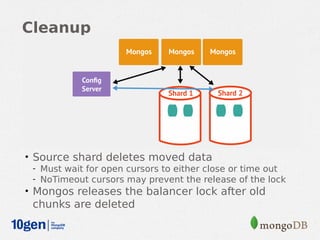



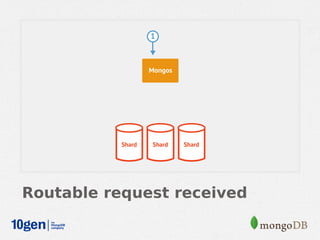
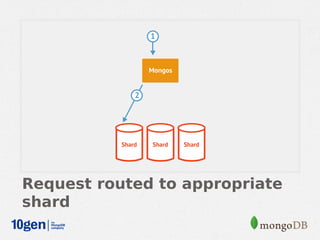
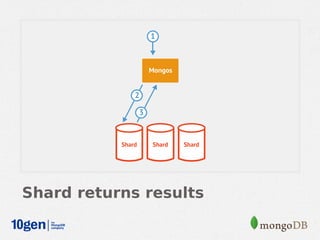
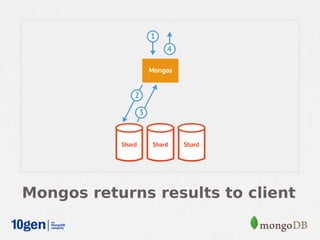


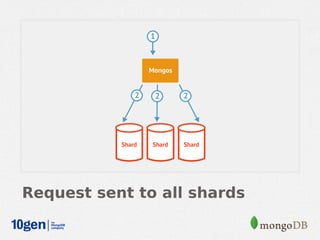
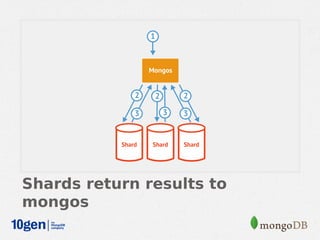
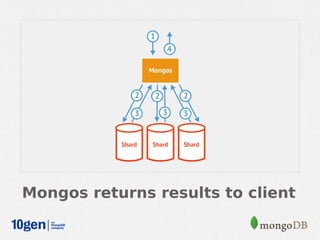


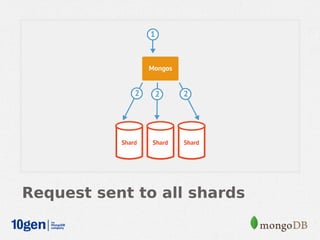
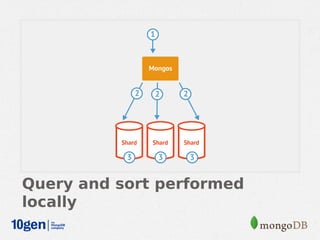





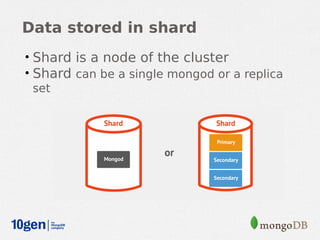
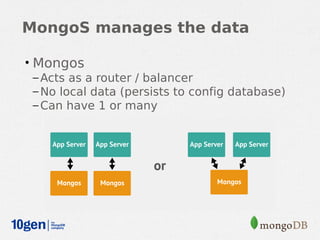
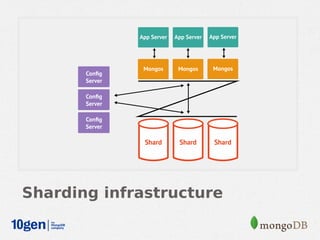
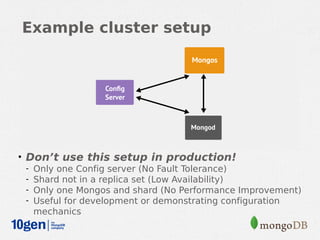
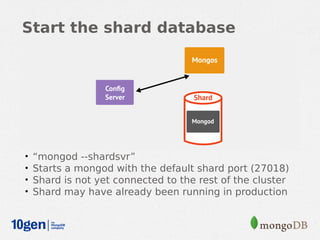
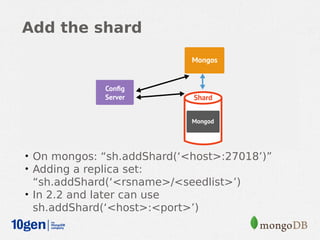
MongoDB provides an auto-sharding feature that allows horizontal scaling of data across multiple servers. It partitions data into chunks based on a user-defined shard key and distributes the chunks across shards. The MongoDB cluster consists of config servers to store metadata, shards to store data, and mongos instances to route queries. Sharding in MongoDB requires enabling sharding on a database and sharding collections, which partitions the data into chunks that can be balanced across shards as the data grows.





























































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)











