Download to read offline










![> conf = { // 5 data nodes
_id : "mySet",
members : [
{_id : 0, host : "A”, priority : 3},
{_id : 1, host : "B", priority : 2},
{_id : 2, host : "C”},
{_id : 3, host : "D", hidden : true},
{_id : 4, host : "E", hidden : true, slaveDelay : 3600}
]
}
> rs.initiate(conf)
Configuration Options](https://image.slidesharecdn.com/2014-05-07-fr-adddevseries-session6-deployingyourapplication-2-140516054744-phpapp01/85/2014-05-07-fr-add-dev-series-session-6-deploying-your-application-2-17-320.jpg)



![{
_id : "mySet",
members : [
{_id : 0, host : "A", tags : {"dc": "ny"}},
{_id : 1, host : "B", tags : {"dc": "ny"}},
{_id : 2, host : "C", tags : {"dc": "sf"}},
{_id : 3, host : "D", tags : {"dc": "sf"}},
{_id : 4, host : "E", tags : {"dc": "cloud"}}],
settings : {
getLastErrorModes : {
allDCs : {"dc" : 3},
someDCs : {"dc" : 2}} }
}
> db.blogs.insert({...})
> db.runCommand({getLastError : 1, w : "someDCs"})
Tagging Example](https://image.slidesharecdn.com/2014-05-07-fr-adddevseries-session6-deployingyourapplication-2-140516054744-phpapp01/85/2014-05-07-fr-add-dev-series-session-6-deploying-your-application-2-23-320.jpg)















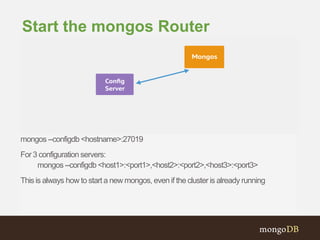
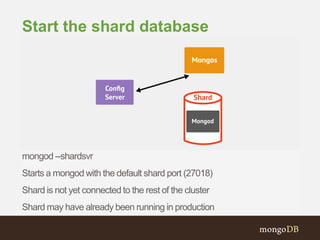
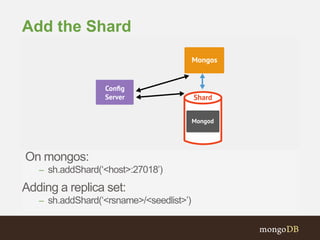
![db.runCommand({ listshards:1 })
{ "shards" :
[{"_id”:"shard0000”,"host”:”<hostname>:27018”} ],
"ok" : 1
}
Verify that the shard was added](https://image.slidesharecdn.com/2014-05-07-fr-adddevseries-session6-deployingyourapplication-2-140516054744-phpapp01/85/2014-05-07-fr-add-dev-series-session-6-deploying-your-application-2-53-320.jpg)




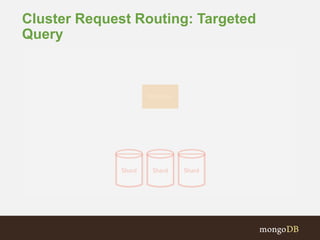

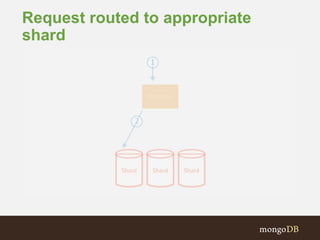









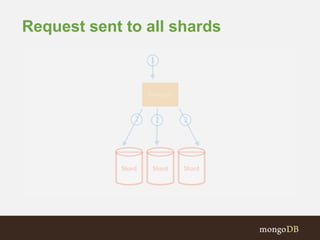
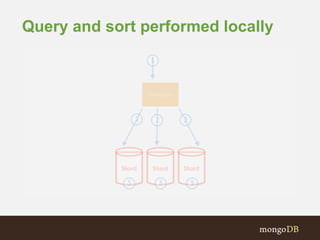








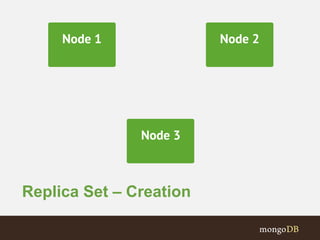
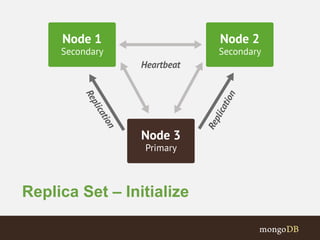
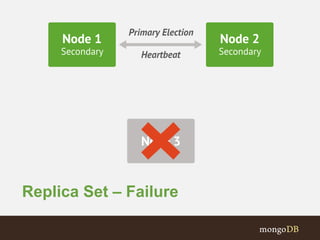
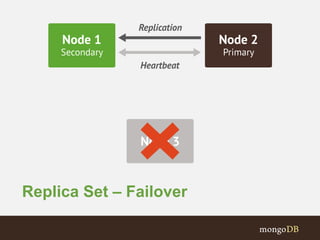
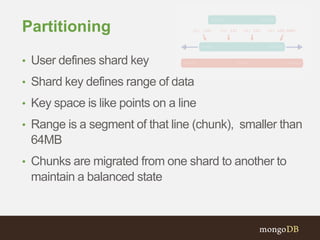
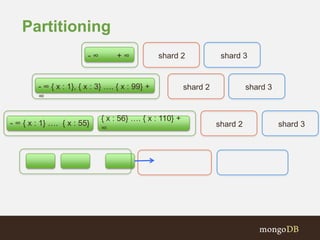
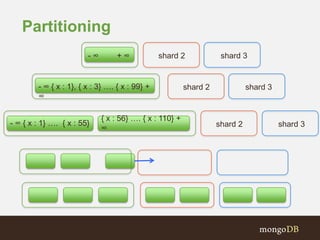
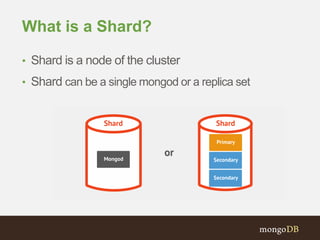
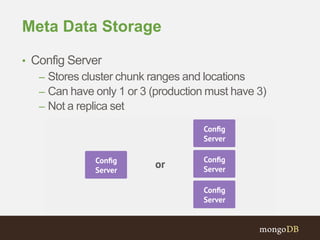
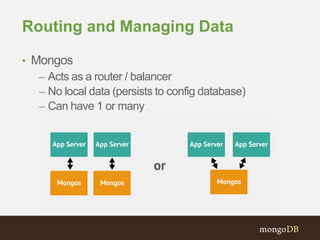
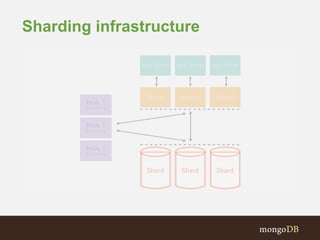
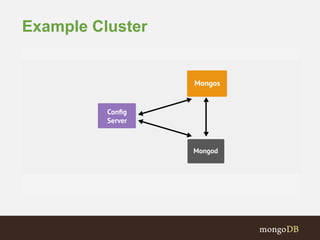
The document discusses MongoDB replication and sharding. Replication uses replica sets for high availability and disaster recovery. Sharding partitions data across multiple servers (shards) to improve scalability. The key points covered include: - Replication maintains copies of data on multiple servers for redundancy and high availability. It uses replica sets and elections for failover. - Sharding partitions data by a shard key across multiple mongod instances (shards) to scale reads and writes. It requires config servers to store metadata and mongos instances as query routers. - Write concerns allow controlling acknowledgments and replication of write operations. Tag-aware sharding allows controlling data distribution across shards.

































































![MongoDB .local San Francisco 2020: Powering the new age data demands [Infosys]](https://cdn.slidesharecdn.com/ss_thumbnails/315pminfosysfinalsfoversionvocalpart1-200120221508-thumbnail.jpg?width=640&height=640&fit=bounds)































